Optimized Frameworks and Libraries for Intel® Processors
Meena Arunachalam, principal engineer, Intel Corporation
@IntelDevTools
Get the Latest on All Things CODE
Sign Up
Modern AI and machine-learning applications perform a range of tasks that convert raw data into valuable insights. Data scientists create multiphase, end-to-end pipelines for AI and machine-learning applications (Figure 1). The phases include:
- Data ingestion
- Data cleaning
- Data exploration
- Feature engineering
They are followed by:
- Prototyping
- Model building
- Model deployment
The phases are often repeated many times, and it may be necessary to scale the entire pipeline across a cluster and to deploy it to the cloud.
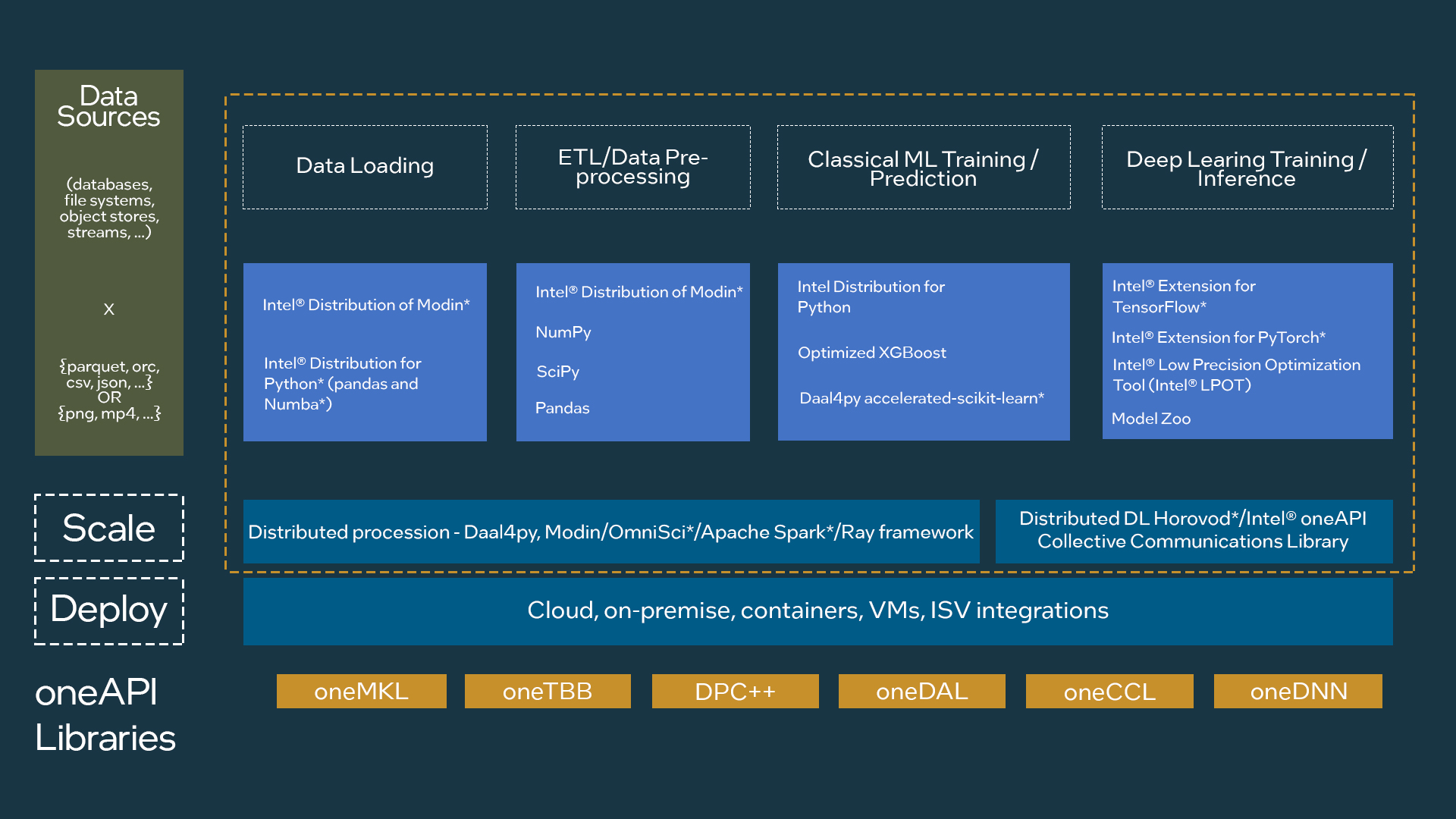
Figure 1. End-to-end analytics pipeline
The Intel® oneAPI AI Analytics Toolkit provides high-performance APIs and Python* packages to accelerate the phases of these pipelines (Figure 2).

Figure 2. Components in the Intel AI Analytics Toolkit
Intel® Distribution of Modin*, with the OmniSciDB engine, provides a scalable pandas API by simply changing a single line of code. Modin significantly improves the performance and scalability of pandas DataFrame processing.
For classical machine-learning training and inference, the Intel oneAPI AI Analytics Toolkit contains the Intel® Extension for Scikit-learn* to accelerate the following:
- Common estimators (logistic regression, singular value decomposition, principal component analysis, and more)
- Transformers
- Clustering algorithms (k-means, density-based spatial clustering of applications with noise [DBSCAN])
For gradient boosting, Intel also optimized the XGBoost* and CatBoost libraries, which provide efficient, parallel tree boosting used to solve many data science problems in a fast and accurate manner.
Let's look at two examples where the Intel oneAPI AI Analytics Toolkit helps data scientists accelerate their AI pipelines:
- Census: This workload trains a ridge regression model to predict education levels using US census data (1970–2010, published by IPUMS).
- Photometric LSST Astronomical Time-Series Classification Challenge (PLAsTiCC) Astronomical Classification: This workload is an open-data challenge on Kaggle* with the aim to classify objects in the night sky. It uses simulated astronomical time-series data to classify objects.
Both workloads have three broad phases:
- Ingestion loads the numerical data into DataFrame.
- Preprocessing and transformation runs various extract, transform, and load (ETL) operations to clean and prepare the data for modeling, such as dropping columns, dealing with missing values, type conversions, arithmetic operations, and aggregation.
- Data modeling creates separate training and test sets (model building, training, and validation, and inference).
Figure 3 shows the breakdown by phase for both workloads, which illustrates the importance of optimizing each phase to speed up the entire end-to-end pipeline.
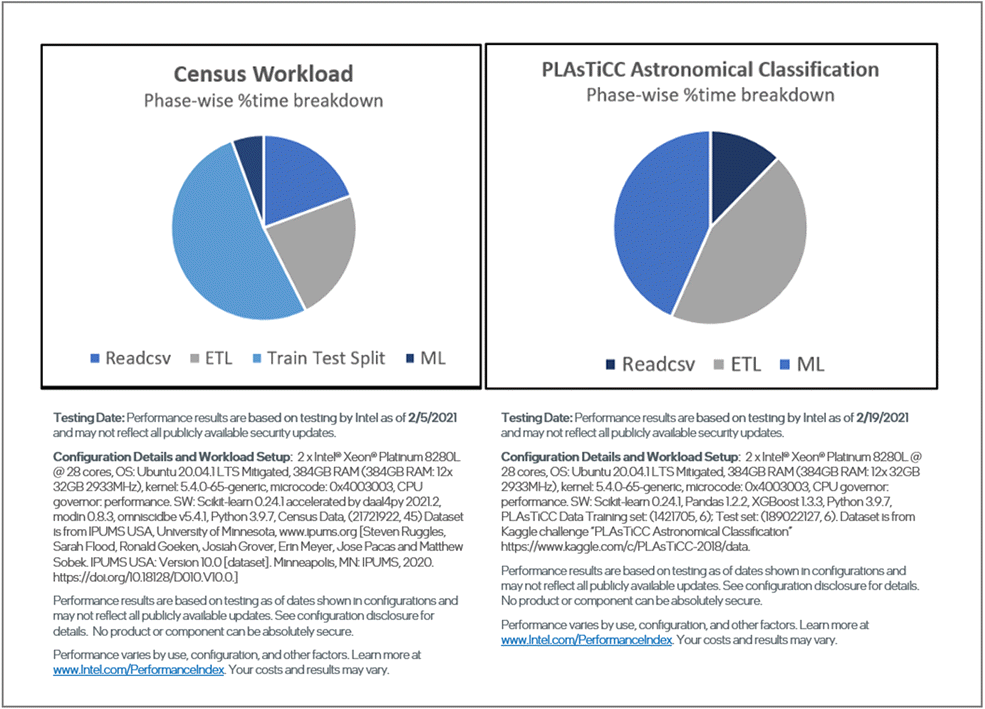
Figure 3. Breakdown by phase for each workload
Figures 4 and 5 show the relative performance and the subsequent speedups for each phase using an Intel-optimized software stack (shown in blue) compared to the stock software (shown in orange). On 2nd generation Intel® Xeon® Scalable processors, the optimized software stack gives a 10x speedup on Census and an 18x speedup for PLAsTiCC compared to the stock software stack.
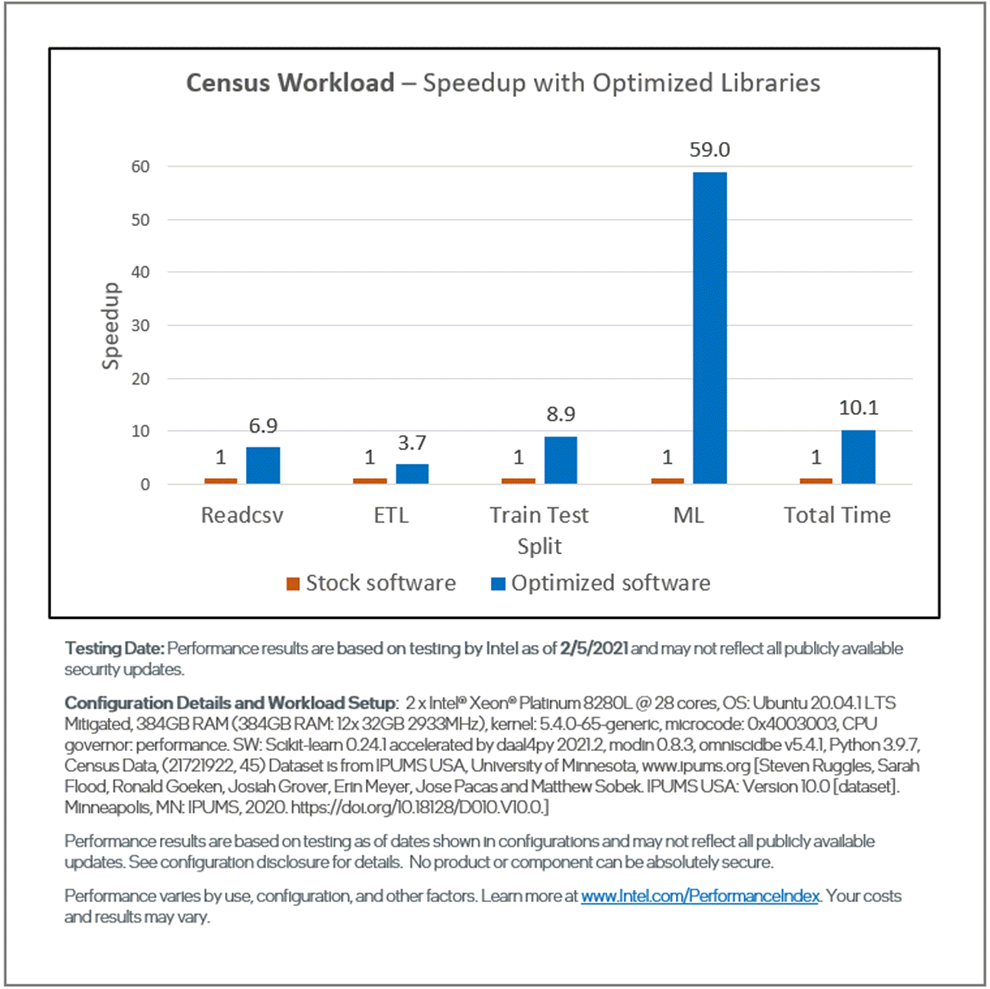
Figure 4. End-to-end performance of the Census workload showing the speedup for each phase
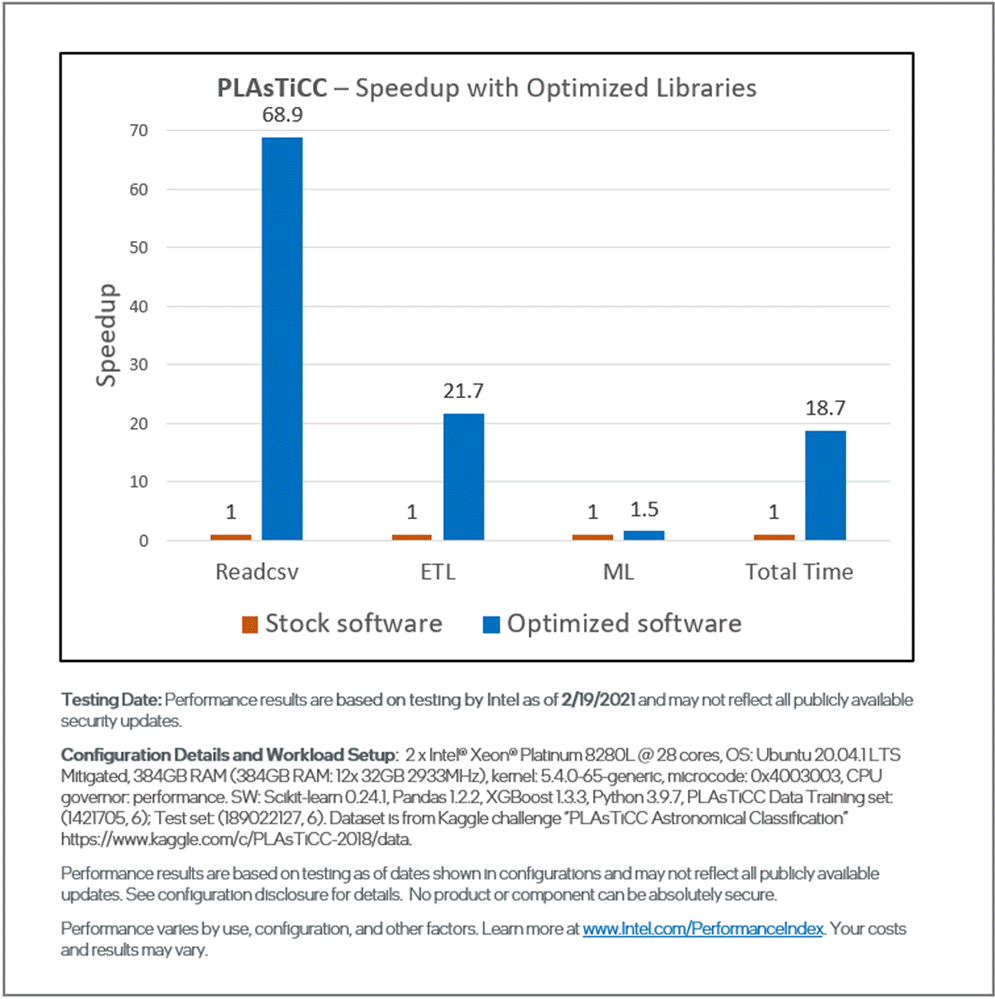
Figure 5. End-to-end performance of the PLAsTiCC workload showing the speedup for each phase
On Census, using the Intel Distribution of Modin instead of pandas gives a 7x speedup for readcsv and a 4x speedup for ETL operations. For training and prediction, using the Intel-optimized scikit-learn instead of the stock package gives a 9x speedup for the train_test_split function and a 59x speedup for training and inference. On PLAsTiCC, using the Intel Distribution of Modin gives a 69x speedup for readcsv and a 21x speedup for ETL operations. These speedups are achieved through various optimizations in the Intel oneAPI AI Analytics Toolkit, including:
- Parallelization
- Vectorization
- Core scaling
- Improved memory layouts
- Cache reuse
- Cache-friendly blocking
- Efficient memory bandwidth use
- More effective use of the processor instruction sets
Figures 6 and 7 show the end-to-end performance of the two workloads on 2nd and 3rd generation Intel Xeon Scalable processors compared to 2nd and 3rd generation AMD EPYC* processors and NVIDIA Tesla* V100 and A100 processors. The same optimized software stack is used on the Intel and AMD CPUs, while the RAPIDS* stack is used on the NVIDIA* GPUs. The complete hardware and software configurations are included in the following image:
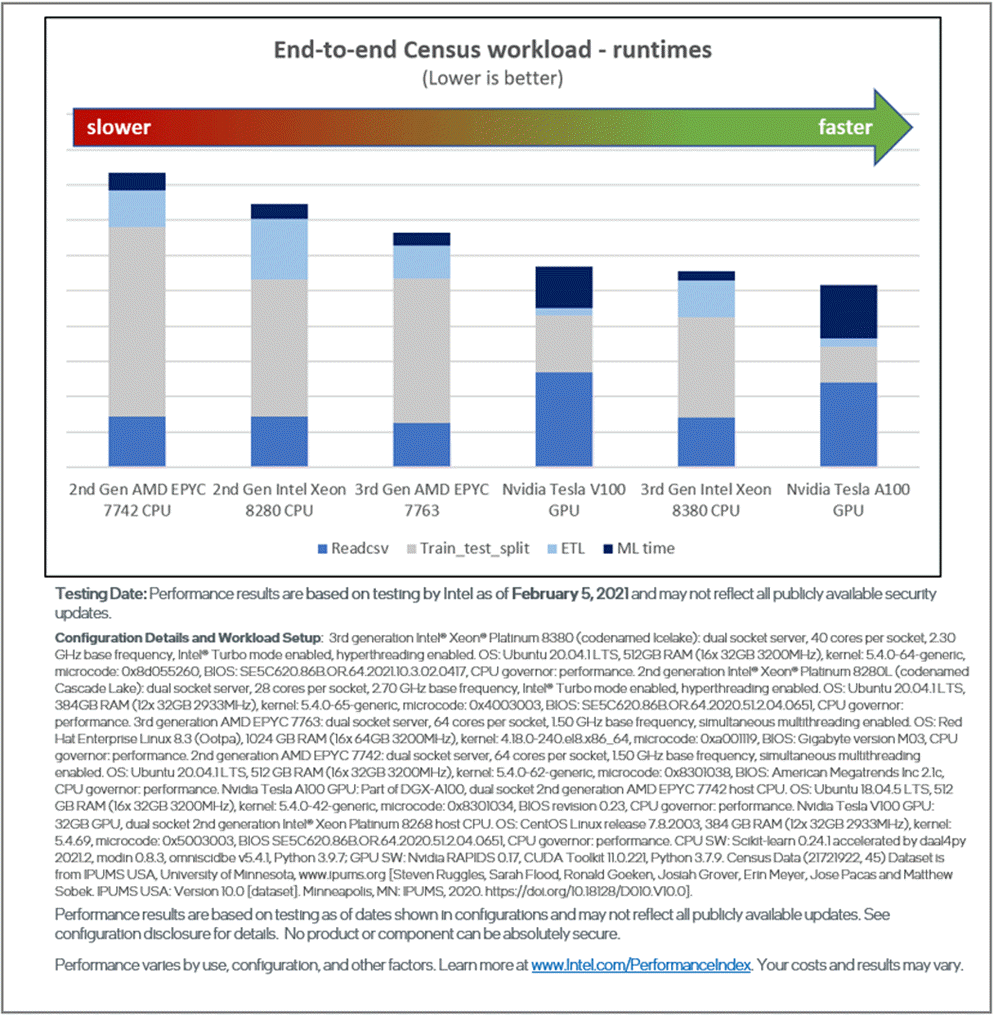
Figure 6. Competitive performance for all phases of the Census pipeline
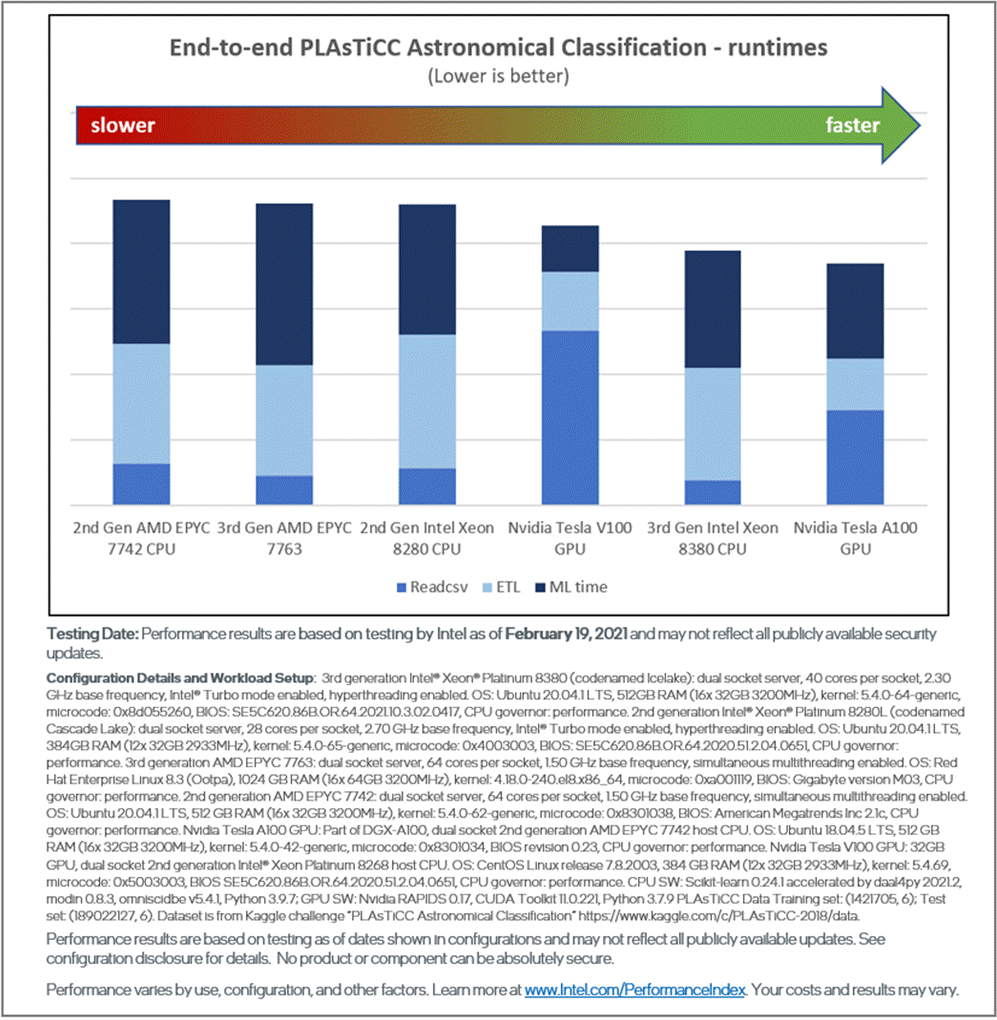
Figure 7. Competitive performance for all phases of the PLAsTiCC pipeline
In this article, we demonstrate a significant performance boost (approximately 10x–18x speedup) on Intel Xeon processors using optimized software packages with simple drop-in replacement over stock data analytics software. The results also show that CPUs and GPUs excel in different phases of the pipelines, but the 3rd generation Intel® Xeon® Platinum 8380 processor outperforms the NVIDIA V100 and is competitive with the NVIDIA A100. The 3rd generation Intel Xeon processor is also cheaper and more power-efficient. These observations reinforce the notion that generality is critical in data analytics.
You can get Modin, XGBoost, Intel Extension for Scikit-learn, and other optimized software for Intel® architectures through many common channels such as Intel’s website, YUM, APT, Anaconda*, and more. Select and download the distribution package that you prefer and follow the Get Started Guide for post-installation instructions.
Hardware and Software Configurations
3rd Generation Intel Xeon Platinum 8380
- Dual-Socket Server: 40 cores per socket, 2.30 GHz base frequency, Turbo mode enabled, hyper-threading enabled
- Operating System: Ubuntu* 20.04.1 LTS, 512 GB RAM (16 x 32 GB, 3200 MHz)
- Kernel: 5.4.0–64-generic
- Microcode: 0x8d055260
- BIOS: SE5C620.86B.OR.64.2021.10.3.02.0417
- CPU governor: Performance
2nd Generation Intel Xeon Platinum 8280L
- Dual-Socket Server: 28 cores per socket, 2.70 GHz base frequency, Turbo mode enabled, hyper-threading enabled
- Operating System: Ubuntu* 20.04.1 LTS, 384 GB RAM (12 x 32 GB, 2933 MHz)
- Kernel: 5.4.0–65-generic
- Microcode: 0x4003003
- BIOS: SE5C620.86B.OR.64.2020.51.2.04.0651
- CPU Governor: Performance
3rd Generation AMD EPYC* 7763
- Dual-socket server: 64 cores per socket, 1.50 GHz base frequency, simultaneous multithreading enabled
- Operating System: Red Hat Enterprise* Linux* 8.3, 1024 GB RAM (16x 64 GB, 3200 MHz)
- Kernel: 4.18.0–240.el8.x86_64
- Microcode: 0xa001119
- BIOS: Gigabyte version M03
- CPU governor: Performance
2nd Generation AMD EPYC 7742
- Dual-Socket Server: 64 cores per socket, 1.50 GHz base frequency, simultaneous multithreading enabled
- Operating System: Ubuntu* 20.04.1 LTS, 512 GB RAM (16 x 32 GB, 3200 MHz)
- Kernel: 5.4.0–62-generic
- Microcode: 0x8301038
- BIOS: American Megatrends* 2.1c
- CPU governor: Performance
NVIDIA Tesla* A100
- GPU: Part of DGX-A100, dual-socket 2nd generation AMD EPYC* 7742 host CPU
- Operating System: Ubuntu* 18.04.5 LTS, 512 GB RAM (16 x 32 GB, 3200 MHz)
- Kernel: 5.4.0–42-generic
- Microcode: 0x8301034
- BIOS: Revision 0.23
- CPU Governor: Performance
NVIDIA Tesla* V100
- GPU: 32 GB, dual-socket, 2nd generation Intel Xeon Platinum 8268 host processor
- Operating System: CentOS* for Linux* release 7.8.2003, 384 GB RAM (12x32 GB, 2933 MHz)
- Kernel: 5.4.69
- Microcode: 0x5003003
- BIOS SE5C620.86B.OR.64.2020.51.2.04.0651
- CPU Governor: Performance
CPU Software
- scikit-learn* 0.24.1, accelerated by daal4py 2021.2
- Modin* 0.8.3
- OmniSciDB v5.4.1
- pandas 1.2.2
- XGBoost 1.3.3
- Python 3.9.7
GPU Software
- RAPIDS 0.17
- CUDA Toolkit* 11.0.221
- Python 3.7.9
______
You May Also Like
| Achieve High-Performance Scaling for End-to-End Machine-Learning and Data-Analytics Workflows Watch | AI Analytics Part 1: Optimize End-to-End Data Science and Machine-Learning Acceleration Watch | AI Analytics Part 2: Enhance Deep-Learning Workloads on 3rd Generation Intel Xeon Scalable Processors Watch | AI Analytics PART 3: Walk Through the Steps to Optimize End-to-End Machine-Learning Workflows Watch |
Intel® oneAPI AI Analytics ToolkitAccelerate end-to-end machine learning and data science pipelines with optimized deep learning frameworks and high-performing Python libraries.Get It Now See All Tools |