Introduction
Memory copy, memcpy, is a simple yet diverse operation, as there are possibly hundreds of code implementations that copy data from one part of memory to another. However, the discussion on how to evaluate and optimize for a better memcpy never stops.
This article discusses how optimizations are positioned, conducted, and evaluated for use with memcpy in the Data Plane Development Kit (DPDK).
First, let’s look at the following simple memcpy function:
void * simple_memcpy(void *dst, const void *src, size_t n)
{
const uint8_t *_src = src;
uint8_t *_dst = dst;
size_t i;
for (i = 0; i < n; ++i)
_dst[i] = _src[i];
return dst;
}
Is there anything wrong with this function? Not really. But it surely missed some optimization methods. The function:
- Does not employ single instruction, multiple data (SIMD)
- Has no instruction-level parallelism
- Lacks load/store address alignment
The performance of the above implementation depends entirely on the compiler’s optimization. Surprisingly, in some scenarios, this function outperforms the glibc memcpy. Of course, the compiler takes most of the credit by optimizing the implementation. But it also gets us thinking: Is there an ultimate memcpy implementation that outperforms all others?
This article holds the view that the ultimate memcpy implementation, providing the best performance in any given scenario (hardware + software + data) simply does not exist. Ironically, the best memcpy implementation is to completely avoid memcpy operations; the second-best implementation might be to handcraft dedicated code for each and every memcpy call, and there are others. Memcpy should not be considered and measured as one standalone part of the program; instead, the program should be seen as a whole—the data that one memcpy accesses has been and will be accessed by other parts of the program, also the instructions from memcpy and other parts of the program interact inside the CPU pipeline in an out-of-order manner. This is why DPDK introduced rte_memcpy, to accelerate the critical memcpy paths in core DPDK scenarios.
Common Optimization Methods for memcpy
There are abundant materials online for memcpy optimization; we provide only a brief summary of optimization methods here.
Generally speaking, memcpy spends CPU cycles on:
- Data load/store
- Additional calculation tasks (such as address alignment processing)
- Branch prediction
Common optimization directions for memcpy:
- Maximize memory/cache bandwidth (vector instruction, instruction-level parallel)
- Load/store address alignment
- Batched sequential access
- Use non-temporal access instruction as appropriate
- Use the String instruction as appropriate to speed up larger copies
Most importantly, all instructions are executed through the CPU pipeline; therefore, pipeline efficiency is everything, and the instruction flow needs to be optimized to avoid pipeline stall.
Optimizing Memcpy for DPDK
Since early 2015, the exclusive memcpy implementation for DPDK, rte_memcpy, has been optimized several times to accelerate different DPDK use-case scenarios, such as vhost Rx/Tx. All the analysis and code changes can be viewed in the DPDK git log.
There are many ways to optimize an implementation. The simplest and most straightforward way is trial and error; to make a variety of improvements with some baseline knowledge, verify them in the target scenario, and then choose a better one by using a set of evaluation criteria. All you need is experience, patience, and a little imagination. Although this approach can sometimes bring surprises, it is neither efficient nor reassuring.
Another common approach sounds more promising: At first, initial effort is invested to fully understand the source code (assembly code, if necessary) behaviors and to establish the theoretical optimal performance. With this optimal baseline, the performance gap can be confirmed. Runtime sampling is then conducted to analyze defects of the existing code to seek improvement. This may require a lot of experience and analysis effort. For example, the vhost enqueue optimization in DPDK 16.11 is the result of several weeks work spent sampling and analyzing. Finally, by moving three lines of code, tests performed with DPDK testpmd showed that enqueue efficiency was improved by 1.7 times as the enqueue cost is reduced from about 250 cycles per packet to 150 cycles per packet. Later, in DPDK 17.02, the rte_memcpy optimization patch was derived from the same idea. This is hard to achieve by the first method.
See Appendix A for a description of the test hardware configuration we used for testing. To learn more about DPDK performance testing with testpmd, read Testing DPDK Performance and Features with TestPMD on Intel® Developer Zone.
There are many useful tools for profiling and sampling such as perf and VTune™. They are very effective as long as you know what data you’re looking for.
Show Me the Data!
Ultimately, the goal of optimization is to speed up the performance of the target application scenario, which is a combination of hardware, software, and data. The evaluation methods vary.
For memcpy, the use of a micro-benchmark can easily get a few key performance numbers such as the copy rate (MB/s); however, that approach lacks reference values. That’s because memcpy is normally optimized at the programming language level as well as the instruction level for the specific hardware platform and specific software code, even specific data length; and the memcpy algorithm itself doesn’t have much space for improvement. In this case, different scenarios require different optimization techniques. Therefore, micro-benchmarks speak only for themselves.
Also, it is not advisable to evaluate performance by timestamping the memcpy code. The modern CPU has a very complex pipeline that supports prefetching and out-of-order execution, which results in significant deviations when the performance is measured at the cycle level. Although forced synchronization can be done by adding serialization instructions, it may change the execution sequence of instruction flow, degrade program performance, and breach the original intention of performance measurement. Meanwhile, instructions which are highly optimized by the compiler also appear to be out-of-order with respect to the programming language. Forced sequential compiling also significantly impacts performance and makes the result meaningless. Besides, the execution time of an instruction stream includes not only the ideal execution cycles, but also the data access latency caused by pipeline stall cycles. Since the data accessed by a piece of code probably has been and will be accessed by other parts of the program, it may appear to have a shorter execution time by advancing or delaying the data access. These complex factors make the seemingly easy task of memcpy performance evaluation troublesome.
Therefore, field testing should be used for optimization evaluation. For example, in the application of Open vSwitch* (OvS) in the cloud, memcpy is heavily used in vhost Rx/Tx, and in this case we should take the final packet forwarding rate as the performance evaluation criteria for the memcpy optimization.
Test Results
Figure 1 below shows the test results of an example with Physical-VM-Physical (PVP) traffic close to the actual application scenario. And by replacing rte_memcpy in DPDK vhost with memcpy provided by glibc, comparative data is gained. The results show that an increase of 22 percent of the total bandwidth can be obtained simply by accelerating the vhost Rx/Tx part by the use of rte_memcpy. Our test configuration is described below in Appendix A.
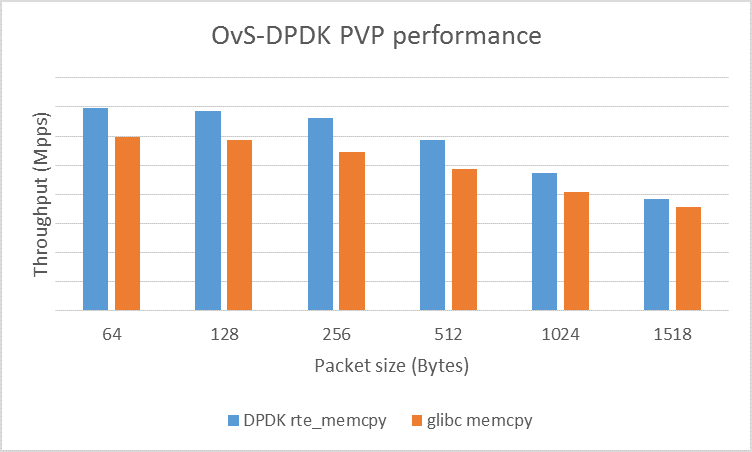
Figure 1. Performance comparison between DPDK rte_memcpy and glibc memcpy in OvS-DPDK
Continue the Conversation
Join the DPDK mailing list, dev@dpdk.org, where your feedback and questions about rte_memcpy are welcomed.
About the Author
Zhihong Wang is a software engineer at Intel. He has worked on various areas, including CPU performance benchmarking and analysis, packet processing performance optimization, network virtualization.
Appendix A
Test Environment
- PVP flow: Ixia* sends the packet to the physical network card, OvS-DPDK forwards the packet received by the physical network card to the virtual machine, the virtual machine processes the packet and sends it back to the physical network card by the OvS-DPDK, and finally back to Ixia
- Virtual machine will use MAC-forwarding using DPDK testpmd
- OvS-DPDK Version: Commit f56f0b73b67226a18f97be2198c0952dad534f1c
- DPDK Version: 17.02
- GCC/GLIBC Version: 6.2.1/2.23
- Linux*: 4.7.5-200.fc24.x86_64
- CPU: Intel® Xeon® processor E5-2699 v3 at 2.30GHz
OvS-DPDK Compile and Boot Commands
./ovs-vsctl --no-wait set Open_vSwitch . other_config:dpdk-init=true
./ovs-vsctl --no-wait set Open_vSwitch . other_config:dpdk-socket-mem="1024,1024"
./ovs-vsctl add-br ovsbr0 -- set bridge ovsbr0 datapath_type=netdev
./ovs-vsctl add-port ovsbr0 vhost-user1 -- set Interface vhost-user1 type=dpdkvhostuser
./ovs-vsctl add-port ovsbr0 dpdk0 -- set Interface dpdk0 type=dpdk options:dpdk-devargs=0000:06:00.0
./ovs-vsctl set Open_vSwitch . other_config:pmd-cpu-mask=0x10000
./ovs-ofctl del-flows ovsbr0
./ovs-ofctl add-flow ovsbr0 in_port=1,action=output:2
./ovs-ofctl add-flow ovsbr0 in_port=2,action=output:1
Use DPDK testpmd for Virtual Machine Forwarding
set fwd mac
start