Overview
This article describes the design and implementation of the datapath classifier – aka dpcls – in Open vSwitch* (OVS) with Data Plane Development Kit (DPDK). It presents flow classification and the caching techniques, and also provides greater insight on functional details with different scenarios.
Virtual switches are drastically different from traditional hardware switches. Hardware switches employ ternary content-addressable memory (TCAM) for high-speed packet classification and forwarding. Virtual switches, on other hand, use multiple levels of caches and flow caching to achieve higher forwarding rates. OVS is an OpenFlow-compliant virtual switch that can handle advanced network virtualization use cases, resulting in longer packet-processing pipelines with reduced hypervisor resources. To achieve higher forwarding rates, OVS stores the active flows in caches.
OVS user space datapath uses DPDK for fastpath processing. DPDK includes poll mode drivers (PMDs) to achieve line-rate packet processing by bypassing the kernel stack for receive and send. OVS-DPDK has three-tier look-up tables/caches. The first-level table works as an Exact Match Cache (EMC) and as the name suggests, the EMC can’t implement a wildcard matching. The dpcls is the second-level table and works as a tuple space search (TSS) classifier. Despite the fact that it is implemented by hash tables (i.e., subtables), it works as a wildcard matching table. Implementation details with examples are explained in the following sections. The third-level table is the ofproto classifier table and its content is managed by an OpenFlow-compliant controller. Figure 1 depicts the three-tier cache architecture in OVS-DPDK.
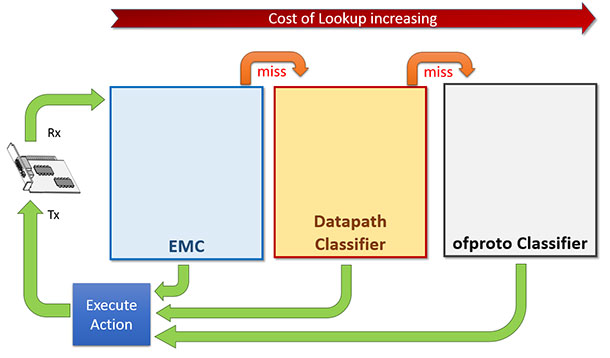
Figure 1. OVS three-tier cache architecture
An incoming packet traverses multiple tables until a match is found. In the case of a match, the appropriate forwarding action is executed. In real-world virtual switch deployments handling a few thousand flows, EMC is quickly saturated. Most of the packets will then be matched against the dpcls, so its performance becomes a critical aspect for the overall switching performance.
Classifier Deep Dive
A classifier is a collection of rules or policies, and packet classification is about categorizing a packet based on a set of rules. The OVS second-level table uses a TSS classifier for packet classification, which consists of one hash table (tuple) for each kind of match in use. In a TSS classifier implementation, a tuple is defined for each combination of field length, and the resulting set is called a “tuple space.” Since each tuple has a known set of bits in each field, by concatenating these bits in order, a hash key can be derived, which can then be used to map filters of that tuple into a hash table.
A TSS classifier with some flow matching packet IP fields (e.g., Src IP and Destination IP only) is represented as one hash table (tuple). If the controller inserts a new flow with a different match (e.g., Src and Dst MAC address), it will be represented as a second hash table (tuple). Searching a TSS classifier requires searching each tuple until a match is found. While the lookup complexity of TSS is far from optimal, it still is efficient compared to decision tree classification algorithms. In decision tree algorithms, each internal node represents a decision, which has a binary outcome. The algorithm starts by performing the test at the root of the decision tree and based on the outcome, the program branches to one of the children and continues until a leaf node is reached and the output is produced. The worst-case complexity is therefore the height of the decision tree. In case of TSS classifier with “N” subtables, the worst case complexity is O(N) and much of the overhead is in hash computation. Though the TSS classifier has high lookup complexity, it still fares better than decision trees in below ways.
Tuple Space Search vs. Decision Tree Classification
- With a few hundred-thousand active parallel flows, the controller may add and remove new flows often. This will be inefficient with decision trees as node insertion – and most of all deletion – are costly operations that could consume significant CPU cycles. Instead, hash tables require many fewer CPU cycles for both insertions and deletions.
- TSS has O(N) memory and time complexity. In worst-case scenarios, TSS may make memory accesses equal to the number of hash tables and the number of hash tables can be as many as the number of rules in the database, and is still better than decision trees.
- TSS generalizes to an arbitrary number of packet header fields.
With a few dozen hash tables around, the classifier lookup means all the subtables should be traversed until a match is found. The flow cache entries in hash tables are unique and are non-overlapping. Hence, the first match is the only match and the search operation can be terminated on a match. The order of subtables in the classifier is random and the tables are created and destroyed at runtime. Figure 2 depicts the packet flow through dpcls with multiple hash tables/subtables.
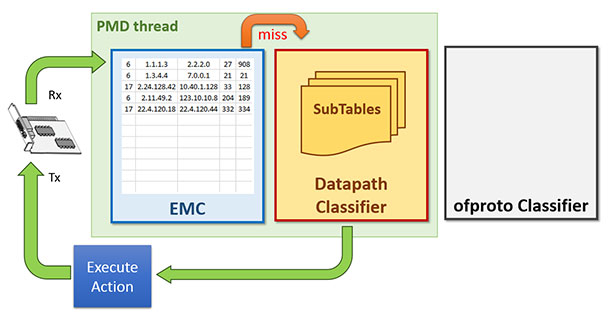
Figure 2. Packet handling by dpcls on an EMC miss
dpcls Optimization Using Subtables Ranking
In OVS 2.5, using the long-term support (LTS) branch, a classifier instance is created per PMD thread. For each lookup, all the active subtables should be traversed until a match is found. On an average, a dpcls lookup has to visit N/2 subtables for a hit, with “N” being the number of active subtables. Though a single hash table lookup is inherently fast, a performance degradation is observed because of the expensive hash computation before each hash table lookup.
To address this issue, OVS 2.6 implements a ranking of the subtables based on the count of hits. Moreover, a dpcls instance is created per ingress port. This comes from the consideration that in practice there is a strong correlation between traffic coming from an ingress port and one or a small subset of subtables that have hits. The purpose of the ranking is to sort the subtables so that the most-hit subtables will be prioritized and ranked higher. Therefore, this allows the performance to improve by reducing the average number of subtables that need to be searched in a lookup.
Figure 3 depicts the multiple dpcls instance creation for the corresponding ingress ports. In this case, there are three ingress ports of which two are physical ports (DPDK_1, DPDK_2) and one vHost-user port for VM_1. DPDK_1 dpcls, DPDK_2 dpcls and VM_1 dpcls instances are created for the DPDK_1, DPDK_2 and VM_1 vHost-user port respectively. Each dpcls will manage the packets coming from its corresponding port. For example, the packets from vHost-user port of VM_1 are processed by PMD thread 1. A hash key is computed from header fields of the ingress packet and a lookup is done on the first-level cache EMC 1 using the hash key. On a miss, the packet is handled by VM_1 dpcls.
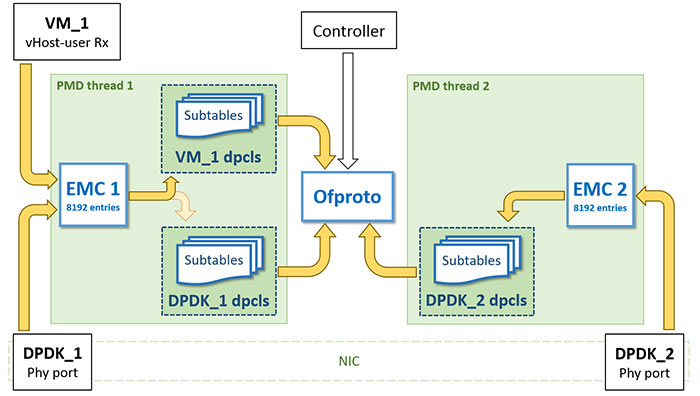
Figure 3. OVS-DPDK classifier in OVS 2.6 with dpcls instance per ingress port
How Hash Tables are Used for Wildcard Matching
Here we will discuss how hash tables are used to implement wildcard matching.
Let’s assume the controller installs a flow where the rule – referred as Rule #1 from here on – is for example:
Rule #1: Src IP = “21.2.10.*”
so the match must occur on the first 24 bits, and the remaining 8 bits are wildcarded. This rule could be installed by an OVS command, such as:
$ ovs-ofctl add-flow br0 dl_type=0x0800,nw_src=21.2.10.1/24,actions=output:2
With the above rule inserted, packets with Src IP like “21.2.10.5” or “21.2.10.123” shall match the rule.
When a packet like “21.2.10.5” is received there will be a miss on both EMC and dpcls (see Figure 1). A matching flow will be found in the ofproto classifier. A learning mechanism will cache the found flow into dpcls and EMC. Below is a description of the details of this use case with a focus on dpcls internals only.
Store a Rule into a Subtable
As a prior step to store the wildcarded Rule #1, we create a proper “Mask #1” first. That will be done by considering the wildcarded bits of the Rule #1. Each bit of the mask will be set to 1 when a match is required on that bit position; otherwise, it will be 0. So in this case, Mask #1 will be “0xFF.FF.FF.00.”
A new hash-table “HT 1” will then be instantiated as a new subtable.
The mask is applied to the rule (see Figure 4) and the resulting value is given as an input to the hash function. The hash output will point to the subtable location where Rule #1 could be stored (we’re not considering collisions here, that’s outside the scope of this document).
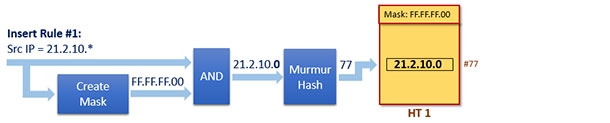
Figure 4. Insert Rule #1 in to HT 1
HT 1 will collect Rule #1 and any other “similar” rule (i.e., with the same fields and the same wildcard mask). For example it could store a further rule, like:
Rule #1A: Src IP = “83.83.83.*”
because this rule specifies Src IP – and no other field – and its mask is equal to Mask #1.
Please note that in case we want to insert a new rule with different fields and/or a different mask, we will need to create a new subtable.
Lookup for Packet #1
Packet #1 with Src IP = 21.2.10.99 arrived for processing. It will be searched on the unique existing hash table HT 1 (see Figure 5).
Mask #1 of the corresponding HT 1 is applied on the Src IP address field and hash is computed thereafter to find a matching entry in the subtable. In this case the matching entry is found => hit.
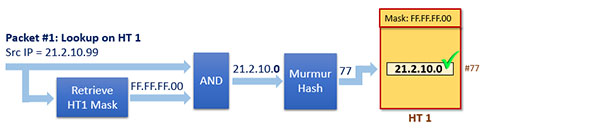
Figure 5. Lookup on HT 1 for ingress Packet #1
Insert a Second Rule
Now let’s assume the controller adds a second wildcard rule – for simplicity, still on the source IP address – with netmask 16, referred as Rule #2 from here on.
Rule #2: Src IP = “7.2.*.*”
$ ovs-ofctl add-flow br0 dl_type=0x0800,nw_src=7.2.21.15/16,actions=output:2
With the above inserted rule, packets with Src IP like “7.2.15.5” or “7.2.110.3” would match the rule.
Based on the wildcarded bits in the last 2 bytes, a proper “Mask #2” is created, in this case: “0xFF.FF.00.00.” (see Figure 6)
Note that HT 1 can store rules only with netmask “0xFF.FF.00.00.” That means that a new subtable HT 2 must be created to store Rule #2.
Mask #2 is applied to Rule #2 and the result is an input for the hash computation. The resulting value will point to a HT 2 location where Rule #2 will be stored.
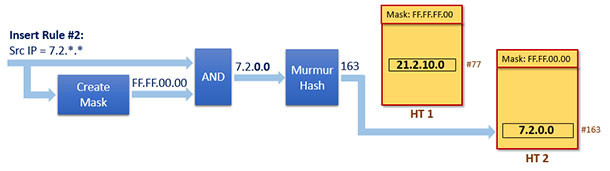
Figure 6. Insert Rule #2 in to HT 2
Lookup for Packet #2
Packet #2 with Src IP = 7.2.45.67 arrived for processing.
As we have 2 active subtables (in this case, HT 1 and HT 2), a lookup shall be performed by repeating the search on each hash table.
We start by searching into HT 1 where the mask is “0xFF.FF.FF.00.” (see Figure 7).
The corresponding table’s mask will be applied to the Packet #2 and a hash key will then be computed to retrieve a subtable entry from HT 1.
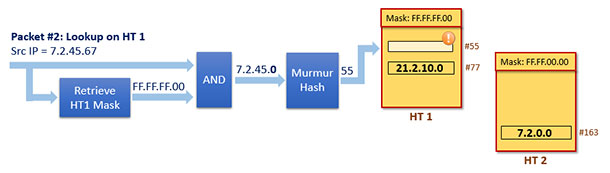
Figure 7. Lookup on HT 1 for ingress Packet #2
The outcome is a miss, as we find no entry into HT 1.
We continue our search (see Figure 8) on the next subtable –HT 2 – and proceed in a similar manner.
Now we will use the HT 2 mask, which is “0xFF.FF.00.00.”
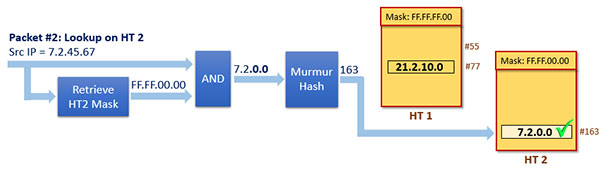
Figure 8. Lookup on HT 2 for ingress Packet #2
The outcome is successful because we find an entry that matches the Packet #2.
A Scenario with Multiple Input Ports
This use case demonstrates the classifier behavior on an Intel® Ethernet Controller X710 NIC card which features four input 10G ports. On each port a dedicated PMD thread will process the incoming traffic. For simplicity Figure 9 shows just pmd60 and pmd63 as the PMD threads for port0 and port3, respectively. Figure 9 shows the details:
- dpcls after processing two packets with Src IP address: [21.2.10.99] and [7.2.45.67].
- The EMC after processing the two packets: [21.2.10.99] and [7.2.45.67].
- pmd63 is processing packets from port 3. The figure shows the content of the tables after processing the packet with IP: [5.5.5.1]
- The new packet [21.2.10.2] will not find a match into EMC of pmd60; instead it will find a match into the Port 0 Classifier. Also, a new entry will be added into pmd60 EMC.
- The new packet [5.5.5.8] will get a miss on pmd63 EMC; however, it will find a match on the Port 3 Classifier. A new entry will then be added into pmd63 EMC.
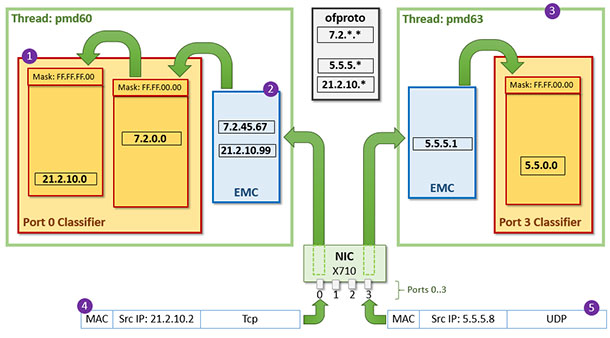
Figure 9. dpcls with multiple PMD threads in OVS-DPDK
Conclusion
In this article, we have described the working of the user space classifier with different test cases and also demonstrated how different tables in OVS-DPDK are set up. We’ve also discussed the shortcomings of the classifier in the OVS 2.5 release and how this is improved in OVS 2.6. The follow-up article, OvS-DPDK Datapath Classifier – Part 2, discusses the code flow, classifier bottlenecks, and ways to improve the classifier performance on Intel® architecture.
For Additional Information
For any question, feel free to follow up with the query on the Open vSwitch discussion mailing thread.
Videos and Articles
To learn more about OVS with DPDK, check out the following videos and articles on Intel® Developer Zone and Intel® Network Builders University.
Open vSwitch with DPDK Architectural Deep Dive
DPDK Open vSwitch: Accelerating the Path to the Guest
The Design and Implementation of Open vSwitch
Tuple Space Search
To learn more about the Tuple Space Search:
About the Authors
Bhanuprakash Bodireddy is a Network Software Engineer with Intel. His work is primarily focused on accelerated software switching solutions in user space running on Intel® architecture. His contributions to OvS-DPDK include usability documentation, Keep-Alive feature, and improving the datapath Classifier performance.
Antonio Fischetti is a Network Software Engineer with Intel. His work is primarily focused on accelerated software switching solutions in user space running on Intel® architecture. His contributions to OVS with DPDK are mainly focused on improving the datapath Classifier performance.