Introduction
Today, all transactional databases (DBs) use DRAM to hide the multiple-orders-of-magnitude higher latencies experienced by the underlying storage tiers. DRAM keeps a cache of recently accessed data in the read path, improving overall read performance by ensuring hot data (which has temporal locality) is accessed at DRAM latencies. Similarly, for writes, the idea is to write as fast as possible to reduce write confirmation delays. Write latencies are critical in interactive applications, where users may not tolerate long wait times.
Although DRAM provides the necessary speed for the write path due to its volatility, there is potential for data loss. To mitigate the risks without incurring large performance penalties, DBs today use a write-ahead log (WAL) stored in persistent media to account for every write. The WAL is usually updated before or at the same time as DRAM data structures. Writing to WALs is faster than writing to the DB itself because WALs are unstructured: writing to a WAL usually implies just appending data to a file.
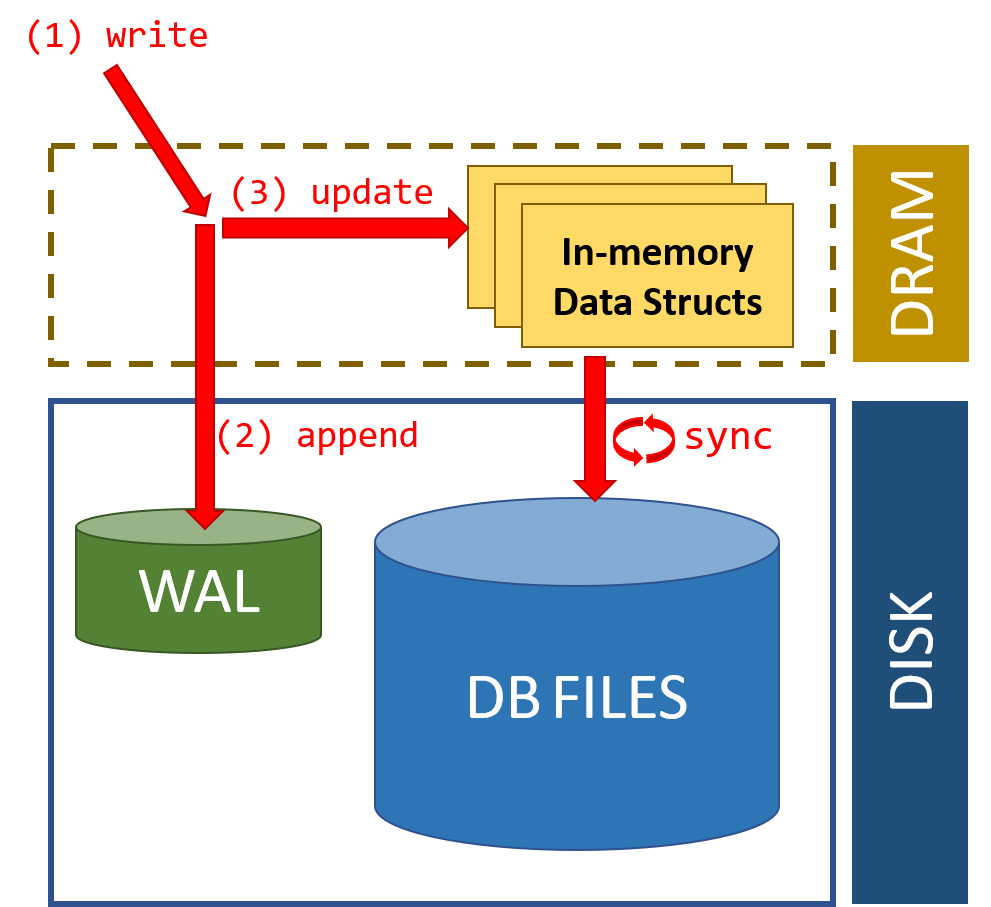
In the event of a crash, the logs are used to replay the sequence of writes and bring the whole DB to a consistent state. The logs can then be discarded or after every synchronization point.
In this article, we will demonstrate different approaches for implementing a WAL with Intel® Optane™ Persistent Memory (PMem) and examine the performance differences between them. I addition, we will compare the results with the performance offered by an Intel® SSD DC P4510.
All the experiments shown below are performed using a single 128GiB PMem module, and the data is written from a single thread only. The writing thread is also pinned to the same socket where the PMem module is installed, effectively avoiding any Non-Uniform Memory Access (NUMA) issues. The file system used for all experiments is EXT4. For more information regarding the testing platform, see the performance disclaimer at the end of the article.
This article represents a natural continuation of my previous articles Speeding Up I/O Workloads with Intel® Optane™ Persistent Memory Modules and Storage Redundancy with Intel® Optane™ Persistent Memory Modules. I recommend that the reader reads those as well.
A basic understanding of persistent memory concepts and terminology is assumed. If you are entirely new to persistent memory, please visit our page on Intel® Developer Zone, where you will find the information you need to get started.
Sector Mode
All I/O done against PMem is done at cache line granularity (i.e., memory copies). Even writes done through a file system are converted by the driver into memory copies. Because the x86 architecture only guarantees writing atomically for 8 bytes at a time, applications and file systems that rely on write atomicity at the block/sector level can experience data corruption due to torn sectors in the event of a crash or power failure.
To eliminate this risk, we create namespaces in sector mode (also known as Storage over App Direct). In this mode, the kernel driver maintains a data structure called the Block Translation Table (BTT) to guarantee torn sectors do not occur. To learn more about the BTT, read the article Using the Block Translation Table for sector atomicity.
Use the following command to create a sector type namespace which results in the creation of a block device /dev/pmem0s.
# ndctl create-namespace -m sector --region=region0
To format the newly created device with the EXT4 filesystem, run:
# mkfs.ext4 /dev/pmem0s
Finally, mount the device:
# mount /dev/pmem0s /mnt/pmem0s
Configuring our PMem in sector mode allows us to use a regular write() system call to append data to the WAL without worrying about atomicity. Nevertheless, and as we will see later on when we explore the fsdax mode, this incurs a performance penalty.
Appending to an Empty File
Let’s start with the most straightforward approach: appending data to an empty file. For every data point, 30 million writes are issued (this is the same for all the other experiments presented in this article). The main loop for these experiments is shown in the following code snippet:
for (i=0; i<REPS; i++) {
timespec_get (&tstart, TIME_UTC);
if (write (fd, buf, bufsize) != bufsize) {
fprintf (stderr, "write() didn't write a complete buffer\n");
exit (1);
}
timespec_get (&tstart_fsync, TIME_UTC);
fdatasync (fd);
timespec_get (&tend_fsync, TIME_UTC);
...
}
In the snippet above, REPS equal 30 million. The variable bufsize equals the size of the buffer that we are writing in each operation (what in the figures below is called “write size”).
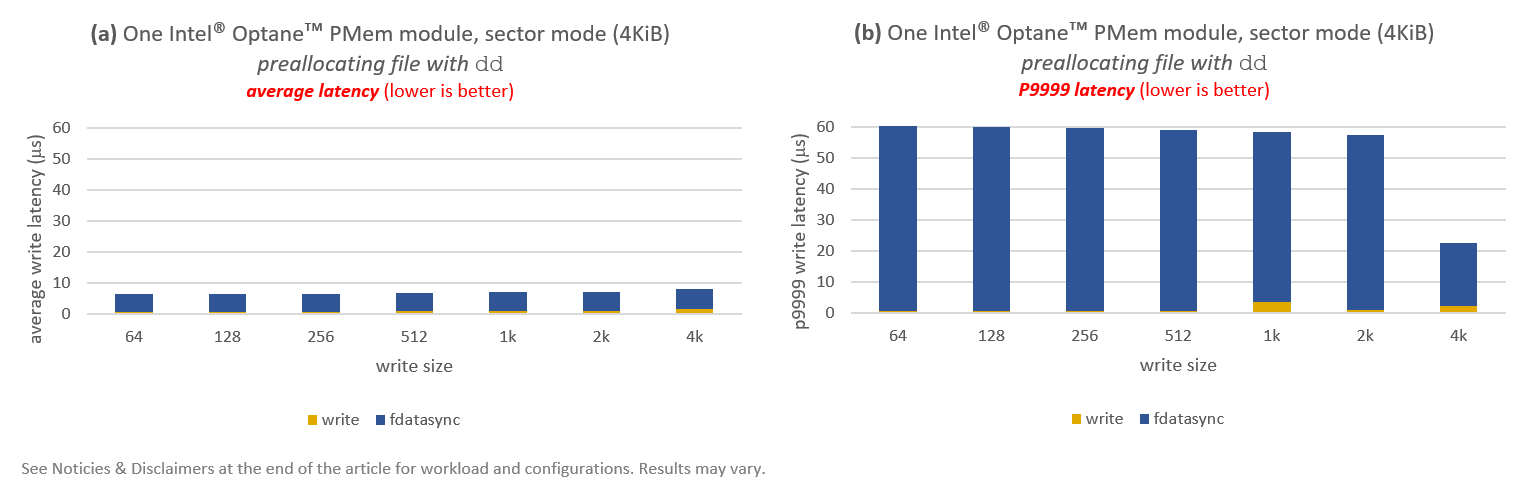
Results are shown in Figure 2, where Figure 2(a) showcases average latencies (in microseconds), while Figure 2(b) does the same for P9999 latencies. P9999 is the cut-off value indicating that 99.99% of accesses achieved a latency less than or equal to P9999.
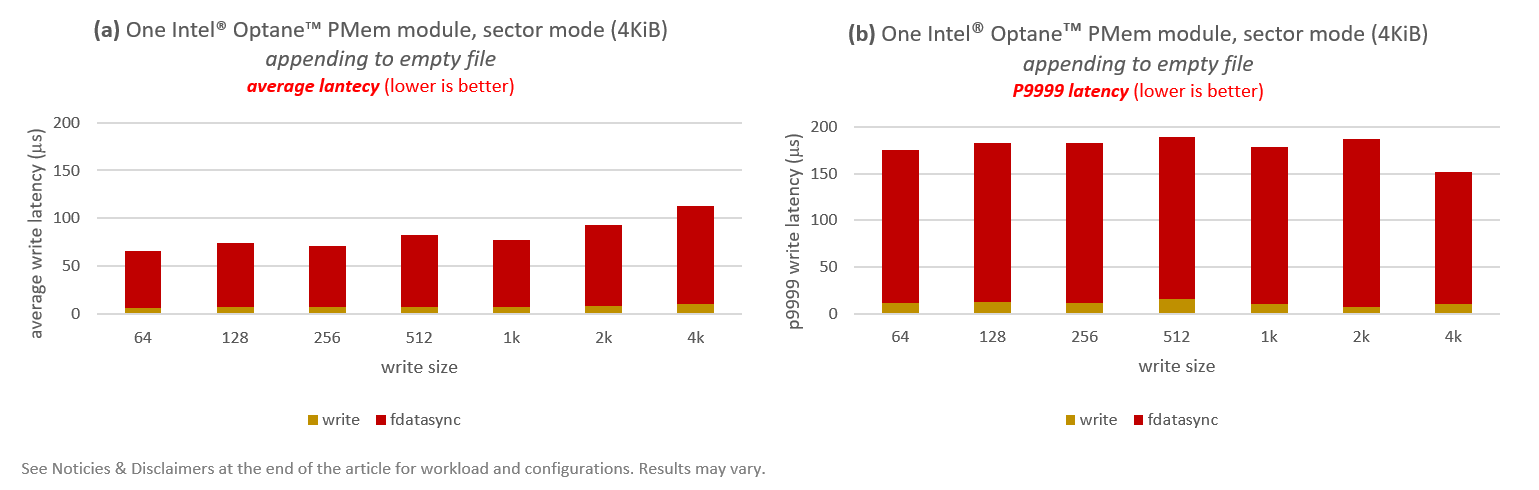
Latency numbers reported in Figure 2 are split into write and fdatasync–every write is always synchronized to make sure data is persistent at the end of the operation. The first observation is that the majority of time is spent in fdatasync. This is not surprising given that the page cache is used in sector mode, i.e., write always writes to DRAM, and it is the job of fdatasync to flush everything down to persistent media.
In terms of performance, we can see that the average latencies (2a) float around 65-90µs except for 4KiB, which has an average latency of 113µs. P9999 latencies (2b) add an extra 40-110µs to the average, giving us >150µs latencies for all write sizes. Although these numbers are not terrible, they are not satisfactory for technology like PMem (as we will below).
If we look at perf data for the write() call (see Figure 3) to see where we are spending the time in the kernel, we can see that we are spending a significant amount of time handling the metadata related to extending the size of the file. That is, handling inode metadata.
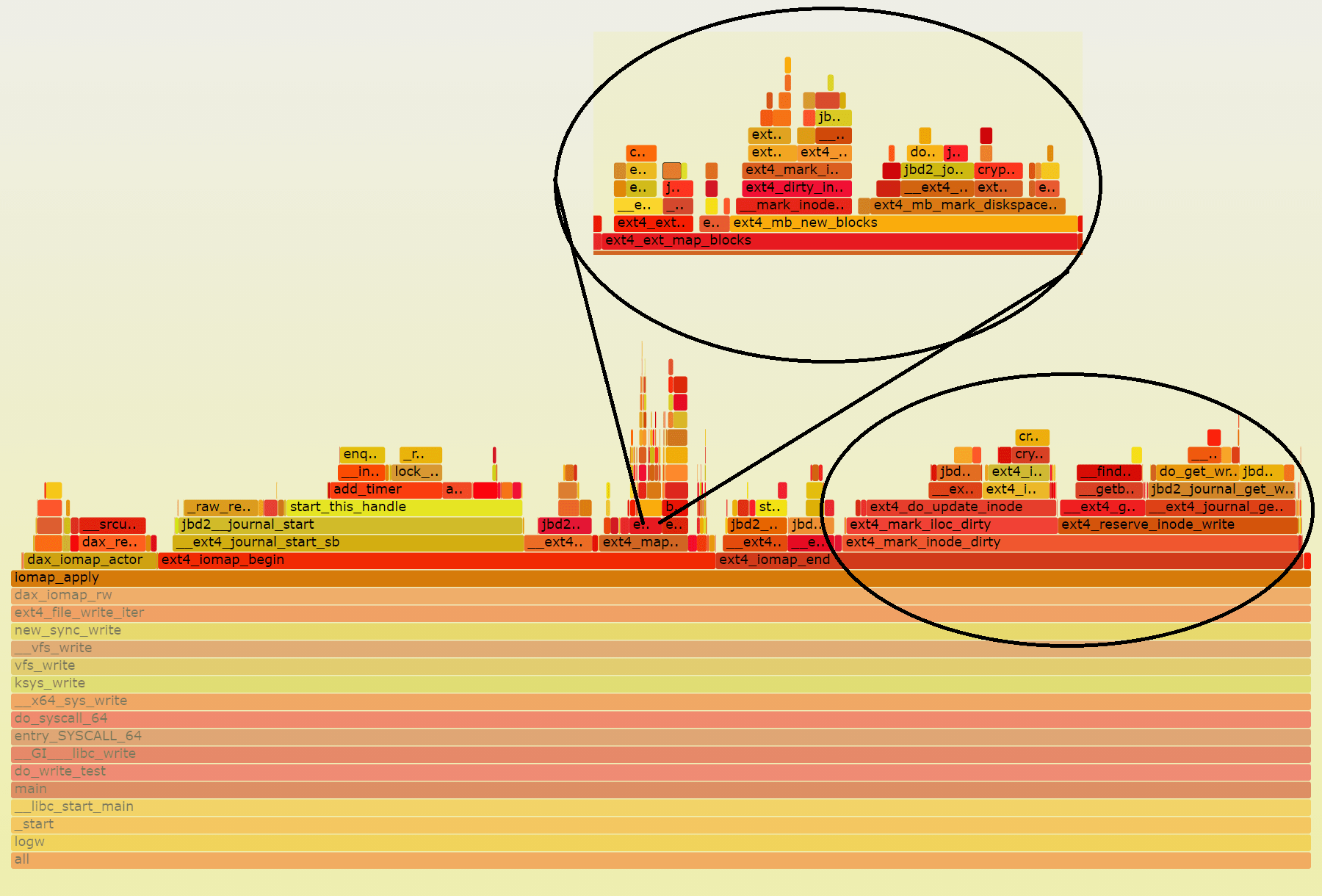
If we divide the time spent on the function iomap_apply() between time spent writing data—dax_iomap_actor()—and time spent handling metadata—ext4_iomap_begin() and ext4_iomap_end()—we can see that we spent 10.2% in the former and 88.1% in the latter.
The perf part corresponding to the fdatasync() call (not shown here for the sake of brevity) is similar. There, we spent 95% of the time waiting for updates to the filesystem journal.
Preallocating the File with fallocate
We can improve things by preallocating the file with fallocate. This alleviates the overhead related to metadata management somewhat.
Note: Preallocating the file used for the WAL is not uncommon. For example, Microsoft SQL implements a circular virtual log residing in a fixed-length physical file. The DB truncates old entries not needed anymore for a successful DB-wide rollback. Only when pressure to the log is high and the file is about to fill up does the DB extent the size of the file “physically”. For more information, you can read Microsoft’s SQL Server Transaction Log Architecture and Management Guide.
To preallocate, use posix_fallocate():
if (posix_fallocate (fd, 0, (off_t) ALLOC_FILE_SIZE) < 0) {
perror ("posix_fallocate");
exit (1);
}
The main loop for these experiments is the same as the one used for Figure 2.
Results are shown in Figure 4.
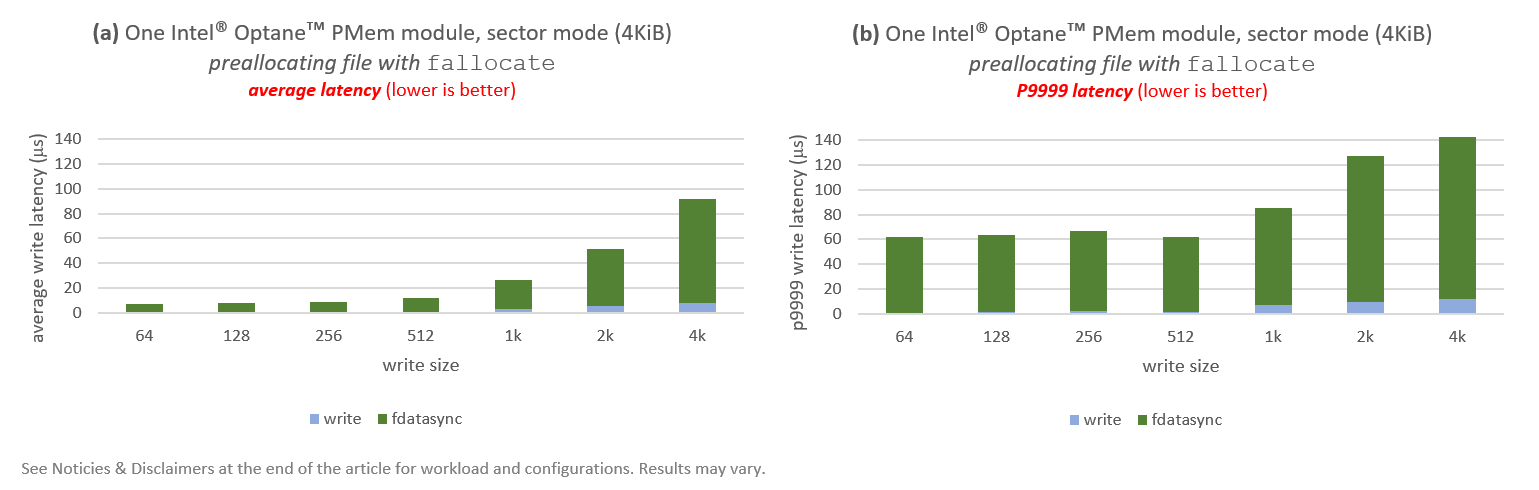
We can see that the performance improvement is significant in the case of average latencies. For example, preallocation gives us 9.5x improvement for writes of 64B and 128B, 8x for 256B, 3x for 1KiB, around 1.8x for 2KiB, and 1.2x for 4KiB. The bigger relative gains are for smaller writes: average latencies stay below 10µs for 64B and 128B. Nevertheless, latencies are still too high for 2KiB and 4KiB writes. Also, all P9999 latencies are never below 60µs for all write sizes, going above 100µs or large write sizes (2KiB and 4KiB).
Looking at perf data again (Figure 5), we can see that we are still spending some amount of time zeroing newly allocated, but never used before, blocks in the file. Preallocation with fallocate is a purely metadata operation, so the file system still needs to ensure that physical blocks assigned to a file—and never used before—are zeroed before being used to avoid data leakage between users.
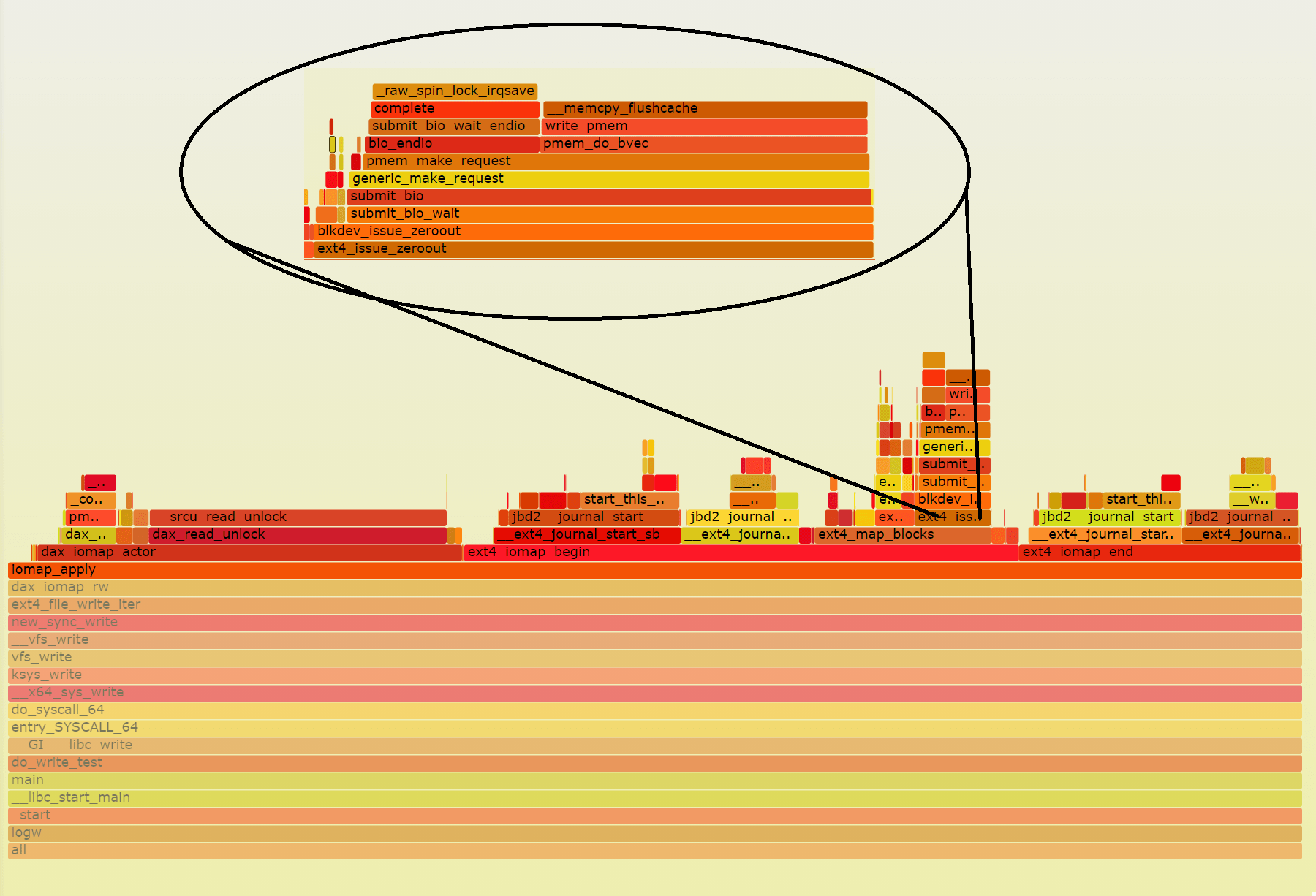
If we divide the time spent on the function iomap_apply() between time spent writing data—dax_iomap_actor()—and time spent handling metadata—ext4_iomap_begin() and ext4_iomap_end()—we can see that we spent 32.8% in the former and 64.6% in the latter. Better than before, but still not ideal.
The perf part corresponding to the fdatasync() call (not shown here for the sake of brevity) shows that we spent 11.3% of the time waiting for updates the filesystem journal.
Preallocating the File with dd
We can improve things even further by preallocating the file with dd. In this case, we are not merely reserving space for the file but physically writing data to it. By doing this, we can avoid the zeroing operation inside the kernel.
$ dd if=/dev/urandom bs=4k count=30000000 of=/mnt/pmem0s/file
As opposed to fallocate, which is an almost instantaneous operation, dd will take some time to complete. This is because dd is physically writing bytes to the media.
Note: Preallocating a file only has to be done once. DBs can use multiple log files and rotate them. For example, metadata in the header of a log file can indicate if that particular file is the “active tail of the log” or not. When the tail of the log gets full, the DB can rotate to another unused file and mark it as the current tail of the log while, at the same time, checkpoint and deactivate the previous one.
The main loop for these experiments is again the same as the one used for Figure 2.
Results are shown in Figure 6.
This change brings the average latencies below 10µs. P9999 latencies, however, are still nearly an order of magnitude higher. With the exception of 4KiB writes (although they are still above 10µs), P9999 latencies stay around 60µs. The 4KiB case clarifies that it’s best to write in chunks matching the underlaying sector size in the BTT.
To put the PMem results in context, let’s compare them with standard NVMe SSDs that are widely used for storing WALs. In this case, let’s compare one Intel® Optane™ PMem module against one Intel® SSD DC P4510. The P4510 is a 3D NAND flash SSD drive. Results are shown in Figure 7. Realize that the size of the Y-axis is different for plots 7(a) and 7(b).
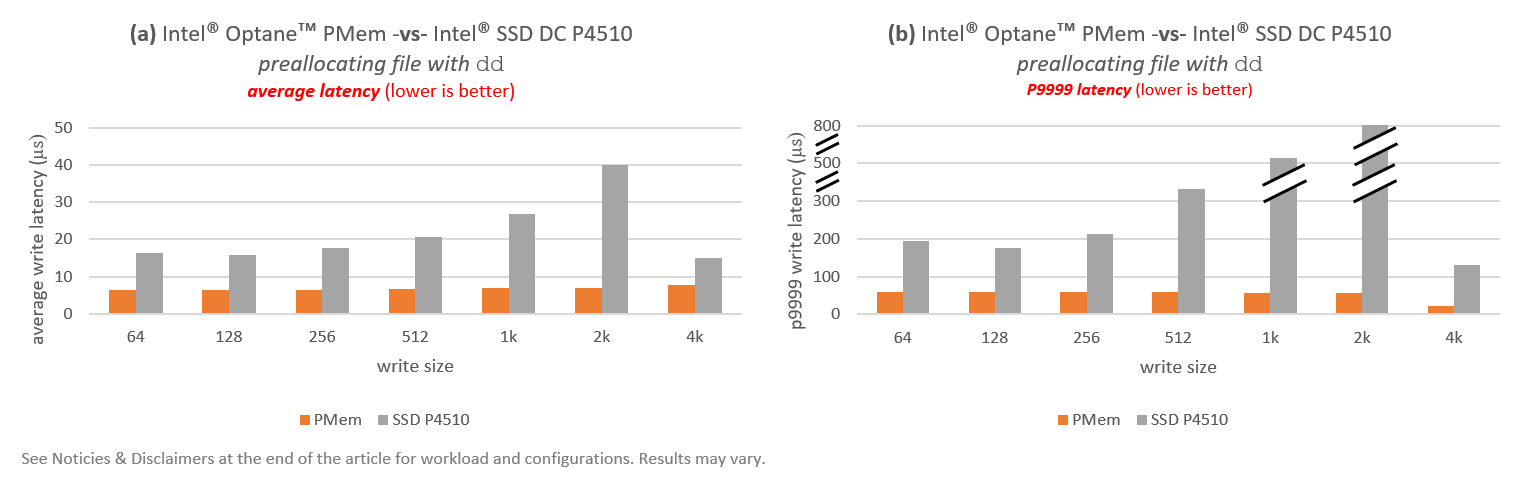
Although PMem is more performant, average latencies for PMem are only 1.9x to 5.7x faster than for flash, depending on the write size. P9999 latencies for 64B, 128B, 256B and 4KiB writes sizes are not much better, with gains between 3x to 5.88x. On the other hand, we see significant gains in P9999 latencies for write sizes 512B (6.6x), 1KiB (9.7x), and 2KiB (14.6x).
In this configuration, there’s still a lot of additional software overhead, context switching into the kernel, and interrupts. We can do better.
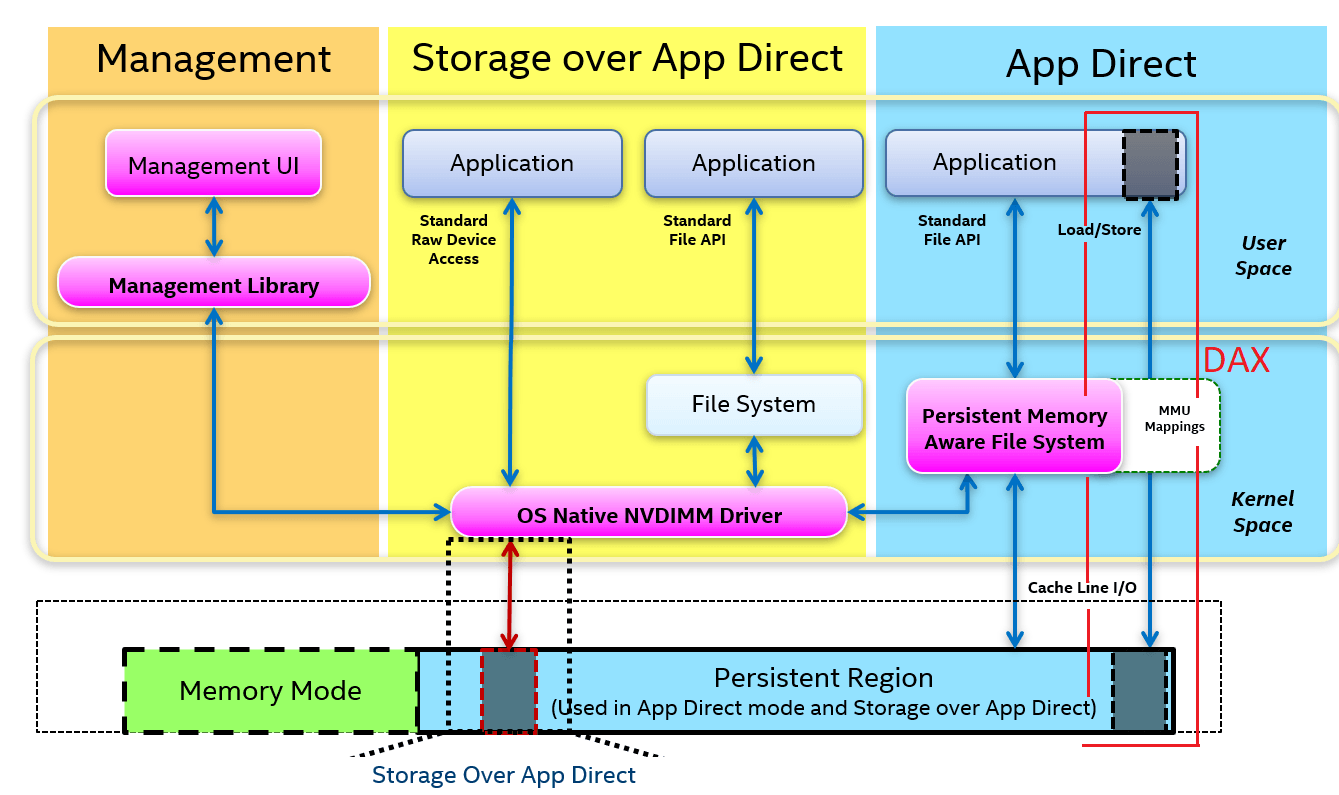
Fsdax Mode
In fsdax mode (also known as App Direct), we can implement write atomicity in user-space instead of relying on the kernel driver, thus avoiding expensive context switches to the operating system (OS).
Note: A namespace created in fsdax mode can only be used with a PMem-aware file system. Otherwise, file system metadata corruption—and data loss—could occur. PMem-aware file systems include EXT4 and XFS in Linux and NTFS in Windows.
A PMem-aware file system allows applications to directly access (DAX) a memory-mapped file residing in PMem. DAX enables applications to bypass the traditional I/O stack (page cache and block layer), allowing data access through CPU loads and stores without the need to buffer data first. DAX is the fastest possible path to the persistent media.
To create a namespace in fsdax mode, run:
# ndctl create-namespace -m fsdax -M mem --region=region0
The above command will create the special block device /dev/pmem0. To format it with the EXT4 filesystem, run:
# mkfs.ext4 /dev/pmem0
Once a file system is created in the PMem device, mount it using the DAX option:
# mount -o dax /dev/pmem0 /mnt/pmem0
With fsdax we have to implement write atomicity ourselves, but the Persistent Memory Development Kit (PMDK), an open-source collection of tools and libraries for PMem programming, includes libraries that simplify this task. In some instances, the required changes amount to just 3 or 4 lines of code (see Table 1).
This article uses the following libraries from PMDK version 1.9:
- libpmemblk provides an array of blocks in PMem, all the same size, such that updates to a single block are atomic. Libpmemblk was not designed to implement a log. Instead, it was designed to manage a cache of blocks that are read and written randomly. Nevertheless, we can use it to implement a log if we restrict all log entries to be the same size.
- libpmemlog provides a log file in PMem such that additions to the log are appended atomically. In this case, log entries can be of any size.
As mentioned previously, using these libraries doesn’t require significant code changes. Table 1 gives the equivalent lines of code between the PMDK libraries and traditional I/O.
| Operation | Traditional I/O | libpmemblk | libpmemlog |
|---|---|---|---|
| Open | open() | pmemblk_create() / pmemblk_open() | pmemlog_create() / pmemlog_open() |
| Write | write() | pmemblk_write() | pmemlog_append() |
| Flush | fdatasync() | - | - |
| Close | close() | pmemblk_close() | pmemlog_close() |
The following code snippet shows the main loop for the libpmemblk implementation:
for (i=0; i<REPS; i++){
timespec_get (&tstart, TIME_UTC);
if (pmemblk_write (pbp, buf, i) < 0) {
perror ("pmemblk_write");
exit (1);
}
timespec_get (&tend, TIME_UTC);
...
}
In the snippet above, REPS equal 30 million. The variable pbp represents the pool. Since all blocks have the same size (defined at pool creation), there is no need to specify buffer size during writes.
The following code snippet shows the main loop for the libpmemlog implementation:
for (i=0; i<REPS; i++){
timespec_get (&tstart, TIME_UTC);
if (pmemlog_append (plp, buf, bufsize) < 0) {
perror ("pmemlog_append");
exit (1);
}
timespec_get (&tend, TIME_UTC);
...
}
In the snippet above, REPS equal 30 million and the variable plp represents the pool.
DIY Sector Atomicity
Sector atomicity can also be implemented with the help of the libpmem and libpmemobj libraries. This section discusses how to do it using a watermark pointer. A high-level view is shown in Figure 9.

To achieve atomicity with a watermark pointer, the following steps must be followed during a write:
- Write the new log entry (i.e., block).
- Make sure that the whole data reaches persistent media. Depending on how the data is written (i.e., temporal versus non-temporal instructions), this could mean flushing (CLFLUSH instruction), waiting on a barrier (SFENCE instruction), or a combination of the two (if out-of-order flushing instructions, such as CLFLUSHOPT or CLWB, were used).
- Update the watermark pointer. Since pointers are 8 bytes in size, updating the pointer is atomic (remember that the x86 architecture guarantees write atomicity for 8 bytes at a time).
- Make sure that the new value for the watermark pointer reaches persistent media. As in (2), this could mean flushing, fencing, or both.
This sequence ensures that atomicity is maintained. If a crash or power failure were to happen before step (3), nothing would change in the actual log. A partially written log entry would never be integrated and considered valid. If a crash or power failure were to occur between (3) and (4), two things could happen: either the changes in (3) reach persistent media—in which case the new block will be part of the log—or the changes in (3) get lost—in which case the new block won’t be part of the log. In any case, the log’s integrity is maintained.
The following code snippet shows the main loop for the libpmem implementation:
for (i=0; i<REPS; i++) {
pmemptr += bufsize;
offset += bufsize;
timespec_get (&tstart, TIME_UTC);
pmem_memcpy (pmemptr, buf, bufsize, PMEM_F_MEM_NONTEMPORAL);
// 8 bytes (atomic)
*((size_t *)pmemaddr) = offset;
pmem_persist (pmemaddr, sizeof(size_t));
timespec_get (&tend, TIME_UTC);
...
}
In the snippet above, REPS equal 30 million. The pointer pmemaddr points to the beginning of the mapped region, and the pointer pmemptr (pmemaddr+offset) points to the end of the buffer. In this case, we are storing as water mark pointer the offset. We can’t store pmemptr since pmemaddr can change between mappings.
The following code snippet shows the main loop for the libpmemobj implementation:
for (i=0; i<REPS; i++){
timespec_get (&tstart, TIME_UTC);
pmemobj_memcpy (pop, data_ptr, buf, bufsize, PMEM_F_MEM_NONTEMPORAL);
data_ptr += bufsize;
// 8 bytes (atomic)
root_ptr->end_of_log.oid.off = pmemobj_oid (data_ptr).off;
pmemobj_persist (pop, &(root_ptr->end_of_log.oid.off), sizeof(uint64_t));
timespec_get (&tend, TIME_UTC);
...
}
In the snippet above, REPS equal 30 million. The variable pop represents the pool. As you can see, this snippet is very similar to the libpmem one. The difference here is that we don’t need to keep track of the offset anymore, since we can extract it from the “fat” persistent memory pointer. The following snippet shows the definition of the data structure used in this libpmemobj implementation:
POBJ_LAYOUT_BEGIN(test);
POBJ_LAYOUT_ROOT(test, struct root);
POBJ_LAYOUT_TOID(test, char);
POBJ_LAYOUT_END(test);
struct root {
TOID(char) data;
TOID(char) end_of_log;
};
Performance Numbers
Results are shown in Figure 10. As was the case in Figure 7, the size of the Y-axis is different for plots 10(a) and 10(b).
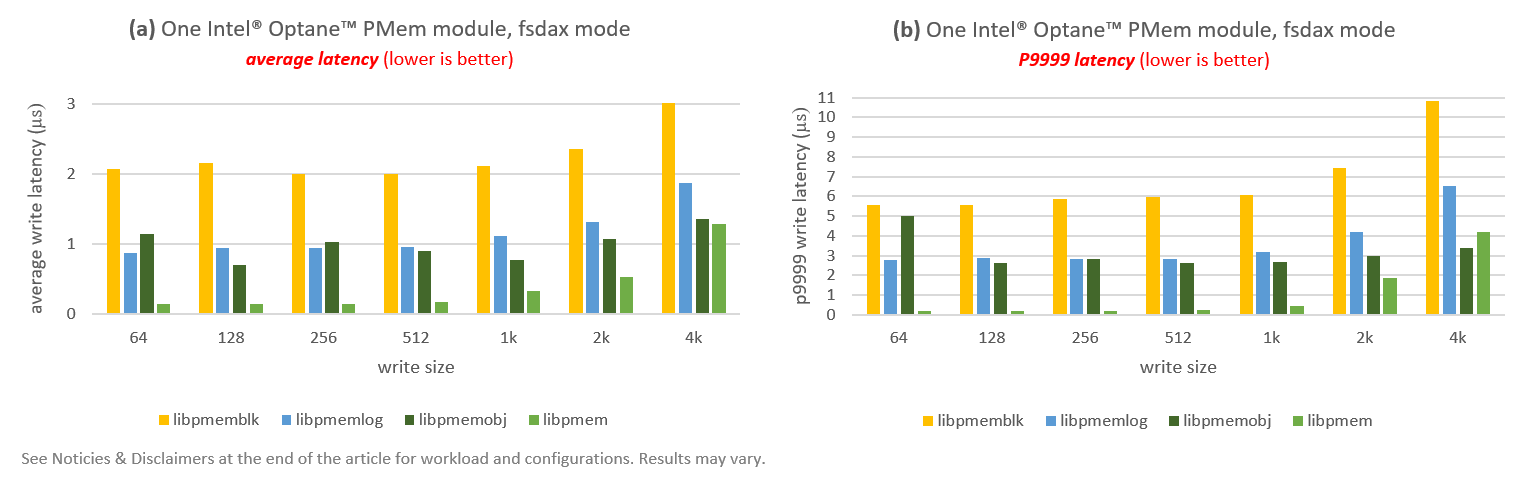
Using the PMDK libraries, we get average latencies below 3µs, and P9999 latencies below 11µs.
Note: To avoid high P9999 latencies that are a result of page faults, it is recommended to pre-fault the file before the actual run. Pre-faulting implies walking over the whole mapped file “touching” every page (i.e., touching every 4KiB or every 2MiB, depending on the page size used by the OS for our PMem device). In libpmemblk, libpmemlog, and libpmemobj, we can do this through the environment variables PMEMBLK_CONF, PMEMLOG_CONF and PMEMOBJ_CONF. For example:
$ export PMEMLOG_CONF="prefault.at_create=1;prefault.at_open=1"
For more information, you can read the manual page for the control interface of PMDK. In libpmem, we need to do it by hand. For example:
void
prefault_memory (char *mem, size_t blocksize, size_t memsize)
{
char *ptr = mem;
while (ptr < mem+memsize) {
ptr[0] = 'A';
ptr += blocksize;
}
}
Regarding which library we should use, it is clear that libpmemblk (yellow) has the highest overhead (not surprising given that libpmemblk was not designed with this particular use case in mind). The best performance comes from libpmem (light green). Libpmemobj (dark green) and libpmemlog (light blue) get close to libpmem for large write sizes (2KiB and 4KiB). If we remove libpmemblk from Figure 10, we get average latencies below 2µs and P9999 latencies below 7µs for all write sizes.
Let’s finish this section by redoing Figure 7. This time, however, let’s add the best performer for PMem in fsdax mode (libpmem). Results are shown in Figure 11. Realize that both are plotted using a logarithmic scale.
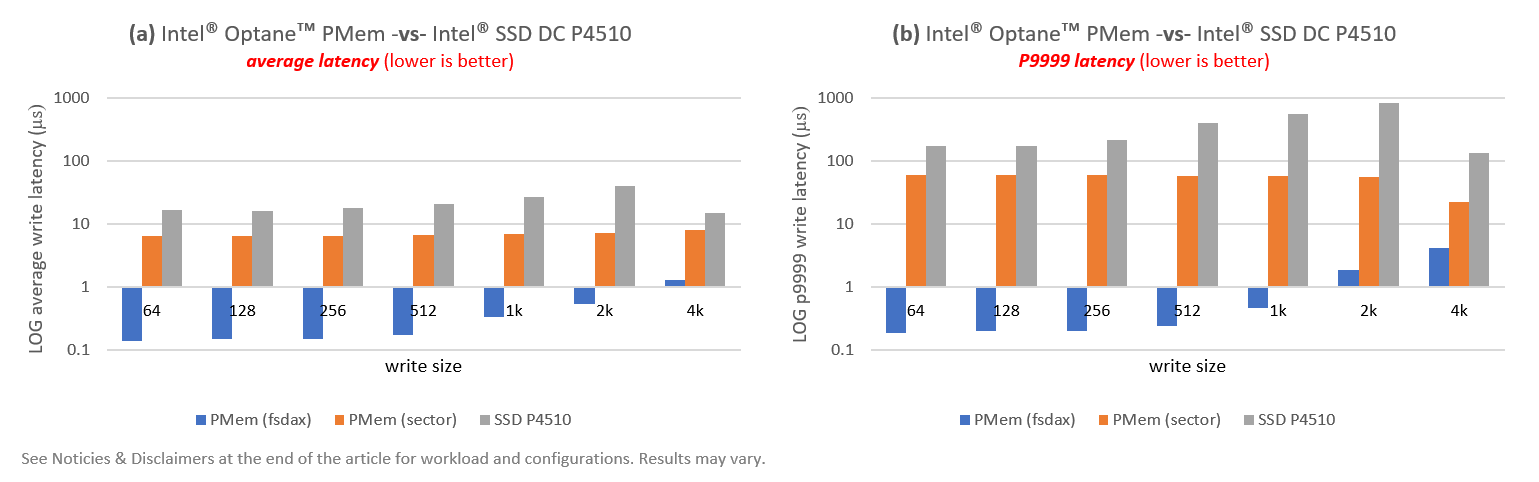
Taking a write size of 4KiB as an example, Intel® Optane™ PMem in fsdax mode is, in terms of average latency, 6.15X faster than sector mode and 11.66X faster than a flash SSD. These results are for the data point with the smallest relative gain, however. The results are even more impressive for smaller write sizes. For example, for 64B, fsdax is 45X faster than sector and 114.88X faster than flash SSD. For the rest of writes sizes, fsdax is between 13X to 43X faster than sector and between 75X to 117X faster than flash SSD depending on the write size. For the P9999 latencies we can see a similar trend but with more pronounced gains. For 4KiB, fsdax is 5.32X faster than sector and 31.26X faster than flash SSD. For smaller write sizes, fsdax is between 30X to 320X faster than sector and between 447X and 1590X faster than flash SSD depending on the write size.
Summary
This article showed different alternatives for implementing a WAL with a single Intel® Optane™ PMem module. We started exploring performance numbers for PMem configured in sector mode (Storage Over App Direct), which provides write sector atomicity through the kernel driver, and ended testing PMem configured in fsdax mode (Add Direct), which does not. Although the former makes it possible to switch from traditional HDDs and SSDs to PMem without code modifications, it incurs significant performance overheads. To take advantage of PMem’s extremely low latencies, using fsdax mode is the recommended approach. And although fsdax requires applications to implement write atomicity themselves, PMDK libraries—such as libpmemlog—let us accomplish this with minimal code changes.
Notices & Disclaimers
Performance varies by use, configuration and other factors. Learn more at www.Intel.com/PerformanceIndex. Performance results are based on testing as of dates shown in configurations and may not reflect all publicly available updates. See configuration disclosure for configuration details. No product or component can be absolutely secure.
Your costs and results may vary.
Intel technologies may require enabled hardware, software or service activation.
© Intel Corporation. Intel, the Intel logo, and other Intel marks are trademarks of Intel Corporation or its subsidiaries. Other names and brands may be claimed as the property of others.
Configuration disclosure: Testing by Intel as of November 16, 2020. 1-node, 2x Intel® Xeon® Platinum 8280L @ 2.7GHz processors, Wolfpass platform, Total memory 192 GB, 12 slots / 16 GB / 2667 MT/s DDR4 RDIMM, Total persistent memory 128G TB, 1 slot / 128 GB / 2667 MT/s Intel® Optane™ Persistent Memory modules, Intel® Hyper-Threading Technology (Intel® HT Technology): Disabled, Storage (boot): 1x TB P4500, ucode: 0x5002f01, OS: Ubuntu* Linux* 20.04, Kernel: 5.4.0-52-generic
Security mitigations for the following vulnerabilities: CVE-2017-5753, CVE-2017-5715, CVE-2017-5754, CVE-2018-3640, CVE-2018-3639, CVE-2018-3615, CVE-2018-3620, CVE-2018-3646, CVE-2018-12126, CVE-2018-12130, CVE-2018-12127, CVE-2019-11091, CVE-2019-11135, CVE-2018-12207, CVE-2020-0543