
With ever-growing datasets, we’ve seen emerging memory technologies like Intel Optane Persistent Memory (PMem) come in to fill gaps between memory and storage. So naturally, this introduces a need for more creative ways to optimize memory usage. For example, some databases may consider data placement based on hot vs. cold data or placement solely based on the data structures. Still, there are always downsides and exceptions to those rules.
MemkeyDB, a PMem enabled version of Redis, introduces optimized data placement solutions on DRAM and PMem. This article introduces memkeydb, the memory allocator memkind, and how an appropriate memory:storage ratio is maintained.
Functionality
MemkeyDB is a version of Redis that uses both DRAM and PMem to store data. The PMem is used in App Direct mode configured to KMEM DAX, meaning it is not persistent, but it simply acts as a large data pool available to the application as system DRAM. MemkeyDB functions just like Redis: persistence is still based on logging (AOF) and snapshotting (RDB). The main changes are the additions of an algorithm that decides where to put a given allocation – in DRAM or PMem, and using Memkind instead of jemalloc as an allocator, which simplifies that process.
By using PMem with Redis, users can expand their databases and application capacities without physically scaling out to more servers. In situations where DRAM is constrained, using PMem in app direct mode can add more than 3 TB per socket in addition to the accessible DRAM, saving money, operating costs, and time
Memkind Allocator
In this PMem enabled version of Redis, we can already see that controlling data placement between DRAM and PMem will be crutial. The Antirez’s version of Redis uses jemalloc to allocate DRAM for the application. To use the two types of memory with a single allocator, we replaced jemalloc with memkind.
The Memkind allocator is based on jemalloc and introduces the concept of memory ‘kinds’. Separate “malloc” calls are used to allocate from these different kinds of memory – DRAM, PMem, and other memory kinds as well.
Additionally, this memkind allocator takes care of potential challenges when freeing memory. For example, the memkind allocator can identify which memory was used for a given pointer and free it properly. Thus, we can simplify code modification and only modify the “allocation” part for a given structure.
For structures set to always allocate to DRAM, a good practice is to pass this information to the Memkind allocator still. Specifying the allocation will speed up execution and eliminate the need to identify where the original memory location was.
It’s important to note that the features Memkind offers MemkeyDB are only available when the PMem is provisioned in DAX KMEM mode. This mode simplifies changes in the Memkeydb source code since it natively supports Copy-on-Write functionality used during replication, logging, and snapshotting. Copy-on-Write is not supported in other DAX modes, only DAX KMEM mode.
Dynamic Threshold Mechanism
In MemkeyDB, we’ve introduced a Dynamic Threshold Mechanism which monitors allocation statistics of DRAM and PMem and balances the utilization of each media to be close to the target ratio value configured for the application by the infrastructure integration team.
There are a few strategies we could have used for memory allocation:
- Locality: hot/cold indicators to determine where to store their data
- Size: large allocations goto PMem, and smaller ones go to DRAM. To take advantage of the larger PMem capacity
- Usage: specifying certain types of structures to store specifically to DRAM or PMem
We saw flaws in each of those ideas, though.
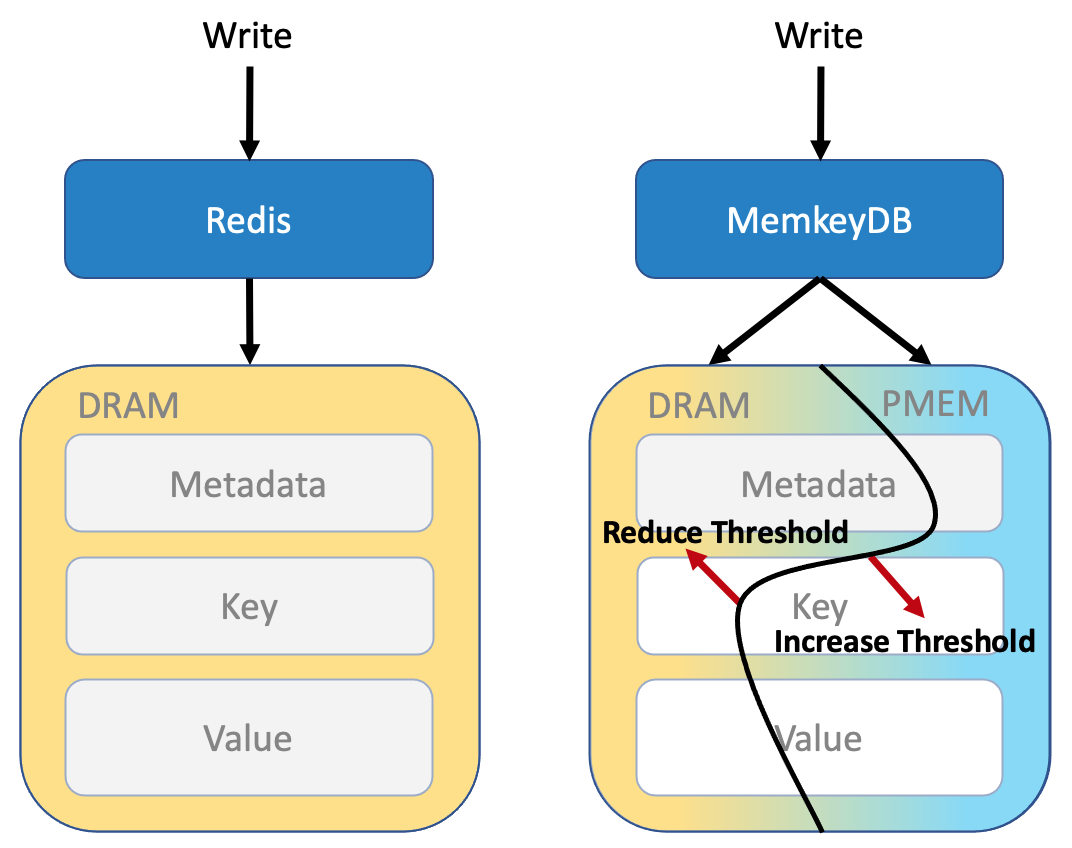
We ended up with a strict size criterion. Whether it’s a key, value, list, node or any other structure, each allocation above a certain size threshold goes to PMem. All others go to DRAM. To take this one step further, we made the threshold dynamic meaning, the application monitors the usage of both types of memory, calculates the current ratio, compares it to the ratio defined by the user, and, if necessary, adjusts the threshold to get back to the desired ratio. For example, suppose the calculation shows that DRAM is consuming too much in relation to PMem. In that case, the application reduces the dynamic threshold, and more allocations start to go to PMem, thus improving the ratio. The rate at which the threshold changes depends on whether and how fast the current ratio improves for the target ratio.
Aside from user data for storing keys and values, applications typically use many internal structures that are frequently allocated and deallocated, e.g., when a new client connects to the Redis server. Since these structures are temporary, they don’t affect the DRAM/PMem ratio. However, for performance reasons, it’s always worth it to allocate them to DRAM.
Metadata structures used for describing user data have the potential to influence performance when stored on PMem. Thus some default settings have been set on specific Redis structures:
- Redis object structures (robj) are always stored in DRAM (except embedded strings)
- The Main Redis Hashtable is stored in DRAM by default. However, there is a configuration option that allows for changing the placement of the main hashtable to PMem if preferred.
Compatibility
The changes in the source code are small, limited to a few places and easily adaptable to various Redis releases. They have been ported to more than 10 of the most popular versions of Redis on the market, starting with Redis 3.2 and ending with Redis 6.0.9. Using Memkeydb instead of Redis does not require any changes to the other layers, as all existing commands and features work as they should. In addition, it is possible to migrate data between Redis and Memkeydb using typical replication features or a snapshot file.
Conclusion
With our initial performance runs showing that MemKeyDB on PMem has performance numbers nearly the same as DRAM for most cases, this comes down to a discussion of the total cost of ownership. Having a larger capacity of cheaper memory and using it in a solution like Redis allows you to maintain the required SLA and lower the TCO.
Additionally, thanks to the larger memory capacity available on a single node, adding more nodes and communicating over the network to scale Redis to a larger capacity is no longer necessary.