Introduction
To get good performance on your pre-trained model for inference, some inference optimizations are required. This article will guide you how to optimize a pre-trained model for better inference performance, and also analyze the model pb files before and after the inference optimizations.
Those optimizations include:
- Converting variables to constants
- Removing training-only operations like checkpoint saving
- Stripping out parts of the graph that are never reached
- Removing debug operations like CheckNumerics
- Folding batch normalization ops into the pre-calculated weights
- Fusing common operations into unified versions
Prerequisites
This article uses a published tutorial in the format of a Jupyter Notebook. Readers might need to get the samples listed below with the related oneAPI AI Analytics toolkit installation.
Inference Optimization Tutorial
For hands-on exercises, please follow the README for that published tutorial. This article also guides readers to go through the results from the previous run.
Introduce the Benchmark
The ssd_inception_v2 pre-trained model from download.tensorflow.org is used in this article, and we leverage an inference benchmark script from the LPOT project to measure the performance of the pre-trained model.
Run the Benchmark with the Original Pre-trained Model
By running the command below with the downloaded benchmark script and the ssd_inception_v2 pre-trained model, users should be able to get performance throughput from this original pre-trained model.
$python tf_savemodel_benchmark.py --model_path pre-trained-models/ssd_inception_v2_coco_2018_01_28/saved_model --num_iter 200 --num_warmup 10 --disable_optimize
Here are output examples of performance throughput.
[{tf_savemodel_benchmark.py:144} INFO - Throughput: 15.671910
Throughput: 15.67 fps
Note : We disable the optimization features from the benchmark script to get the actual performance number from the original model.
Optimize the Original Pre-trained Model
Users have different options to optimize their pretrained model, and those options includes The Intel® Low Precision Optimization Tool (Intel® LPOT), and tools from TensorFlow GitHub.
The optimization from those options includes:
- Converting variables to constants
- Removing training-only operations like checkpoint saving
- Stripping out parts of the graph that are never reached
- Removing debug operations like CheckNumerics
- Folding batch normalization ops into the pre-calculated weights
- Fusing common operations into unified versions
We recommend using LPOT for pre-trained model optimization on Intel architectures.
Intel® Neural Compressor
The Intel® Neural Compressor (INC) is an open-source Python library that delivers a unified low-precision inference interface across multiple Intel-optimized Deep Learning (DL) frameworks on both CPUs and GPUs.
INC also provides graph optimizations for fp32 pre-trained models with more optimizations (such as common subexpression elimination) than the TensorFlow optimization tool optimize_for_inference.
Here are related to INC codes to convert a unfrozen saved model pb file into a optimized model pb file.
The unfrozen save model pb file is under "pre-trained-models/ssd_inception_v2_coco_2018_01_28/saved_model", and the optimized save model pb file is under "pre-trained-models/ssd_inception_v2_coco_2018_01_28/optimized_model".
Users could refer to fp32 optimization for more details.
Fp32 optimization feature from LPOT is required, so users must use LPOT v1.4 or greater.
Tools from TensorFlow GitHub
TensorFlow GitHub provides tools for freezing and optimizing a pre-trained model. Freezing the graph can provide additional performance benefits. The freeze_graph tool, available as part of TensorFlow on GitHub, converts all the variable ops to const ops on the inference graph and outputs a frozen graph. With all weights frozen in the resulting inference graph, you can expect improved inference time. After the graph has been frozen, additional transformations by using optimize_for_inference tool can help optimize the graph for inference.
We also provide a wrapper python script for those tools from TensorFlow GitHub, and the wrapper python script "freeze_optimize_v2.py" provides the same functionality as freeze_graph.py and optimize_for_inference.py from TensorFlow GitHub.
A freeze_optimize_v2.py wrapper python script for inference optimization is used in this article, and Intel is working on upstreaming this script to the TensorFlow GitHub. The input of this script is the directory of the original saved model, and the output of this script is the directory of the optimized model. By running the command below, users can get the optimized model pb file under the output_saved_model_dir.
$python freeze_optimize_v2.py --input_saved_model_dir=pre-trained-models/ssd_inception_v2_coco_2018_01_28/saved_model --output_saved_model_dir=pre-trained-models/ssd_inception_v2_coco_2018_01_28/optimized_model
Due to a limitation of convert_variables_to_constants_v2 function in TensorFlow, freeze_optimize_v2.py doesn't support graphs with embedding or control flow related ops.
Run the Benchmark with the Optimized Pre-trained Model
Then users need to re-run the benchmark with the optimized model pb file using the following command, and users should be able to see the improved performance throughput with the optimized model.
$python tf_savemodel_benchmark.py --model_path pre-trained-models/ssd_inception_v2_coco_2018_01_28/optimized_model --num_iter 200 --num_warmup 10 --disable_optimize
The diagram below is the output result from our previous run on Intel® Xeon SKX machines.
There is a 1.66X speedup from the optimized model in this run as shown in the diagram below.

The only difference is the model optimization, and users could achieve this 1.6X speedup in the same inference workload. Users should be able to see the speedup number on their environment by running the published tutorial mentioned above.
Analyze the Original and Optimized Pre-trained Model PB Files
To further show readers the difference between the original and optimized model PB files, we use a PB file parser to analyze those pb files.
Original pre-trained PB file
The PB file parser will get the call count number of different TensorFlow operations in the PB file. Here is the table of original pre-trained pb files. The top 5 call counts hotspots are Const, Identity, Relu6, FusedBatchNorm , and Conv2D.
| Op_type | Call Count |
|---|---|
| Const | 396 |
| Identity | 386 |
| Relu6 | 77 |
| FusedBatchNorm | 77 |
| Conv2D | 77 |
| ConcatV2 | 10 |
| AvgPool | 7 |
| MaxPool | 5 |
| DepthwiseConv2dNative | 1 |
Here is the call count breakdown pie chart, and Conv2D as a heavy computation ops only takes 7.4% of call counts.
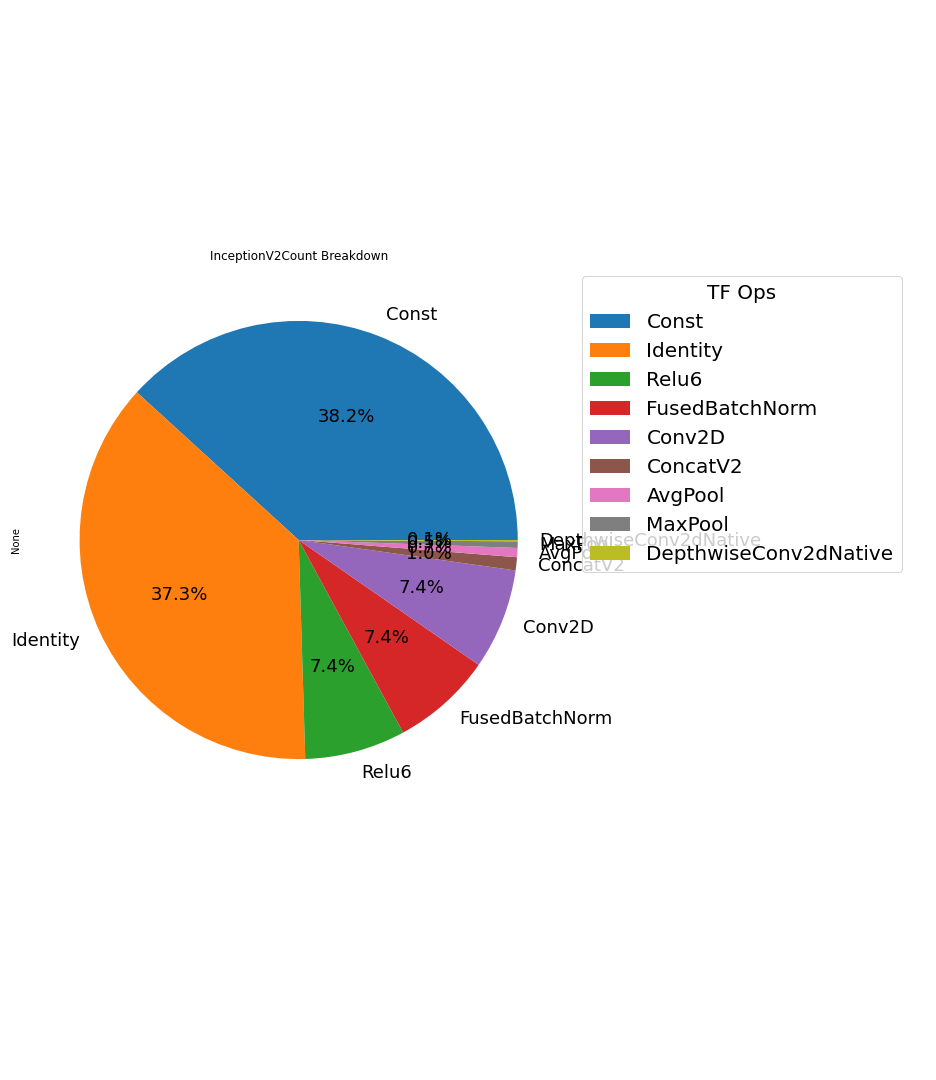
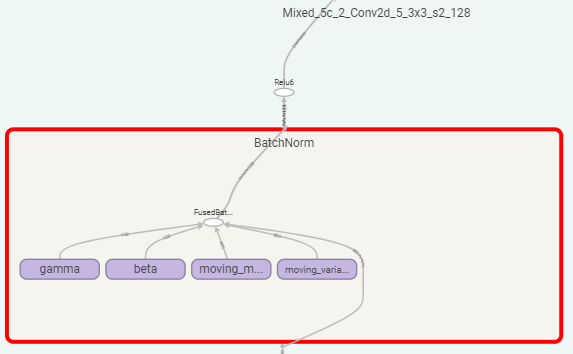
Therefore, we reviewed the first top four hotspots, and we found that BatchNorm indeed contains some training-specific ops as in the diagram below. Further inference optimization for BatchNorm is needed.
Optimized pre-trained PB file
After inference optimization, we saw simpler BatchNorm operations as in the diagram below. It works as a BiasAdd instead in this optimized model pb file.
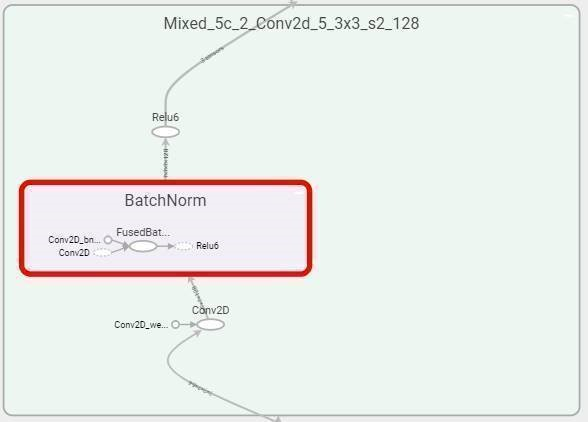
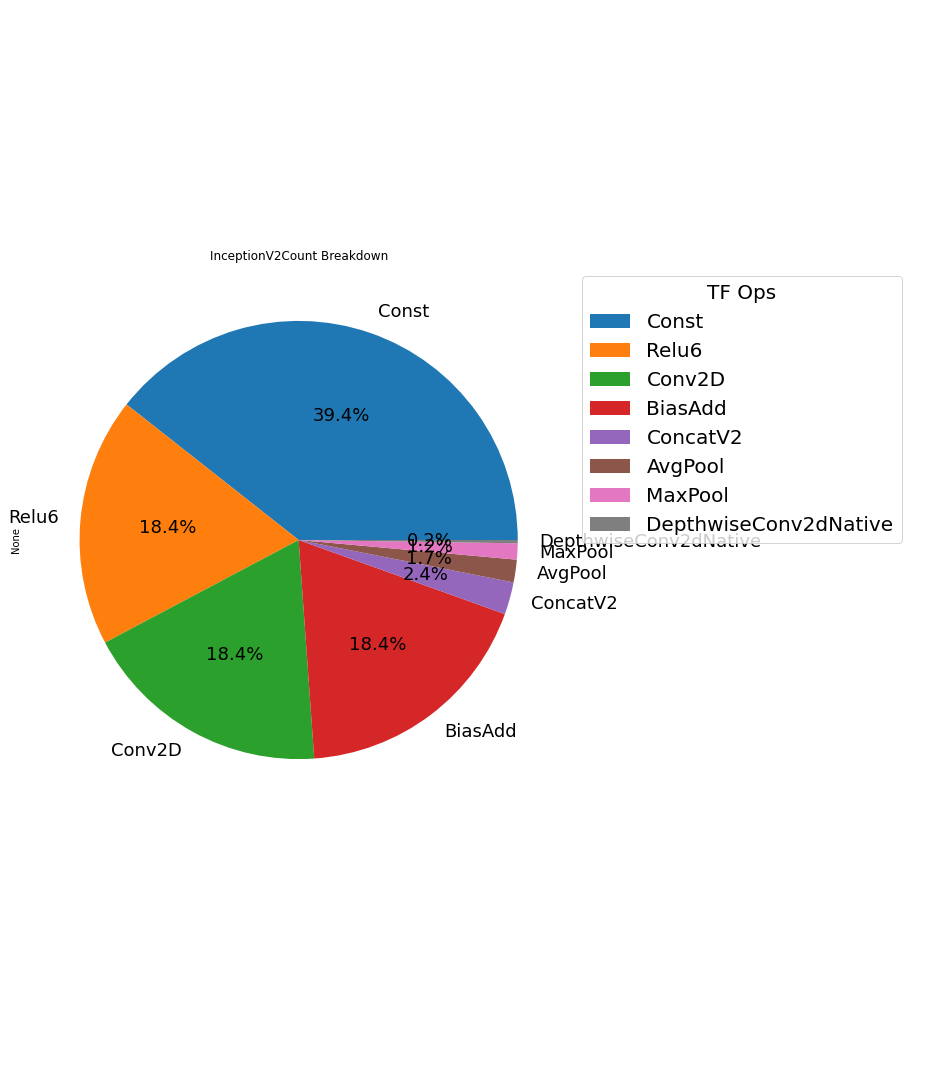
Here is the table of optimized pre-trained pb file, and FusedBatchNorm is indeed optimized and replaced with BiasAdd.
| Op_type | Call count |
|---|---|
| Const | 165 |
| Relu6 | 77 |
| BiasAdd | 77 |
| Conv2D | 77 |
| ConcatV2 | 10 |
| AvgPool | 7 |
| MaxPool | 5 |
| DepthwiseConv2dNative | 1 |
Here is the call count breakdown pie chart, and we also saw Conv2D as a heavy computation ops takes more percentage of call counts than original pb file.
Conclusion
By benchmarking and analyzing with the ssd_inception_v2 pre-trained model, users can understand that inference optimization is essentially for inference performance. By using the provided inference optimization method, users can easily get a good inference speedup by just modifying the pre-trained model.