Introduction
High-speed packet processing applications can be very resource-intensive. One way software engineers and architects can make their application more performant is to split their packet processing pipeline across multiple threads. However, this can lead to increased pressure on cache and memory resources. Therefore, keeping the application’s memory footprint as small as possible relative to the data plane traffic is key to making a performant application. This paper provides one technique to optimize the memory usage of multithreaded packet processing applications that should increase the performance of memory-bound applications; if an application is not memory bound, it should nevertheless reduce its memory requirements.
Reference Application
This paper is based on research conducted using the Reference Dataplane v18.10.0 of a virtualized cable modem termination system from Intel. The vCMTS application is a Data Over Cable Service Interface Specification (DOCSIS) media access control (MAC) data plane pipeline based on DOCSIS 3.1 specifications and the Data Plane Development Kit (DPDK) packet processing framework. The purpose of this application is to provide a tool for characterization of vCMTS data plane packet processing performance and power-consumption on Intel® Xeon® platforms. Download the vCMTS reference data plane from the Access Network Dataplanes site at 01.org. This version of vCMTS is based on DPDK 18.08, but the theory behind the methods described in this paper can be applied to applications that use earlier versions of DPDK or other packet processing libraries such as the Cisco* Vector Packet Processing (VPP) framework. The features used in this paper were initially added to DPDK 16.07.2.
The downstream portion of this application uses a multithreaded pipeline design. The pipeline is split into two parts: the upper and lower MAC, which run on separate threads. These must be run on sibling hyper-threads – two threads running on one physical core – or the L2 caching efficiency will be lost. Refer to the vCMTS downstream packet processing pipeline in Figure 1. The upstream portion of vCMTS at the time of this paper does not use a multithreaded model; this paper focuses on the downstream portion as its reference application.

Figure 1: vCMTS downstream upper and lower MAC
Ring Versus Stack
DPDK uses message buffers known as mbufs to store packet data. These mbufs are stored in memory pools known as mempools. By default, mempools are set up as a ring, which creates a pool with a configuration similar to a first-in, first-out (FIFO) system. This model can work well for multithreaded applications where the threads span multiple cores. However, for applications where the threads are on the same core, it can cause unnecessary memory bandwidth, and some of the hyper-threading efficiency may be lost. In applications where the threads are running on the same core, the ring mempool will end up cycling through all the mbufs. This results in CPU cache misses on almost every mbuf allocated when the number of mbufs is large, such as in the case of vCMTS.
DPDK also allows users to set up their mempools in a stack configuration, which creates a mempool that uses a last-in, first-out (LIFO) configuration.
Mempools also have a mempool cache, which allows “warm” buffers to be recycled, providing better cache efficiency where buffers are allocated and freed on the same thread. Mempool caches are always set up using a LIFO configuration to improve the performance of the mempool cache. Each thread used by a DPDK application has its own mempool cache for each mempool. As the packets are received by one thread and transmitted by another thread, mbufs will never be freed and allocated on the same thread, which renders the mempool cache system redundant in this case.
Movement of buffers in the ring mempool model (shown in Figure 2):
- The application tries to populate the network interface cards (NICs) receive (RX) free list from thread 0’s mempool cache.
- Mbufs are never freed on thread 0, so the mempool cache will be replenished directly from the mempool.
- The application then allocates mbufs from the mempool cache.
- When the mbufs are freed from the transmitting (TX) NIC, they are held in a mempool cache on thread 1.
- When thread 1’s mempool cache is full, the application will start to return mbufs to the mempool, as mbufs are never allocated on thread 1.
This is a poor model for this application, as the thread 0 mempool cache always contains the “coldest” mbufs and the thread 1 mempool cache is always full. If the mempool is large, the CPU will be unable to retain the whole mempool in CPU cache, and it will be pushed to memory. In this model, the application will quickly cycle through the entire mempool, resulting in large memory bandwidth as the mbufs fall in and out of the CPU’s cache.
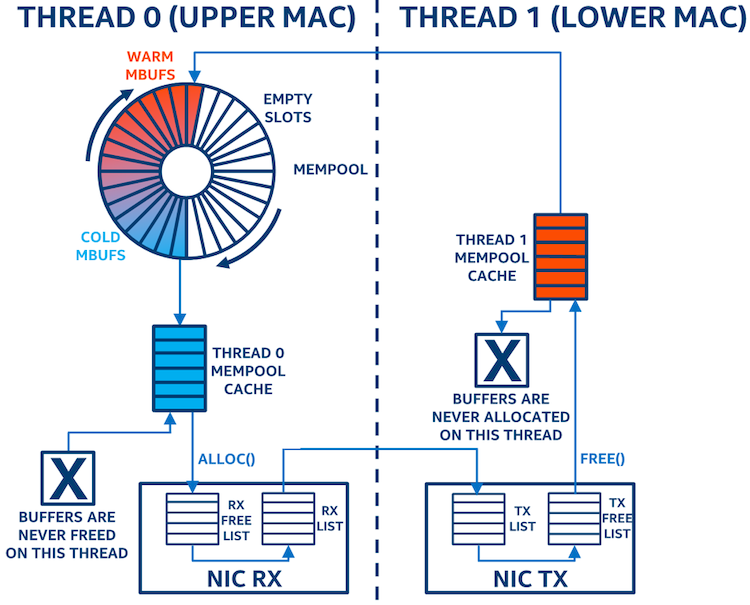
Figure 2: Buffer movement when using ring mempool configuration
Movement of buffers in the stack mempool model (shown in Figure 3):
- The application will allocate mbufs to the NICs RX free list from the mempool.
- When the mbufs are freed from the transmitting NIC, they are freed back to the mempool.
This model is better, as it is more streamlined1. The mempool has been changed to perform as a stack, and the redundant mempool caches have been disabled. The mbufs are allocated to the NIC straight from the mempool and are then freed straight back to the mempool, not held on thread 1. Note that freeing and allocating from the stack mempool may be slightly more expensive, due to the need to do locking on the mempool because of multithreaded access. The locking penalties are minimized because the locks are confined to the one core. (If the threads were on separate cores, the locking cost would be more significant.) The overall benefits of reusing “warm” mbufs outweighs the additional locking costs.
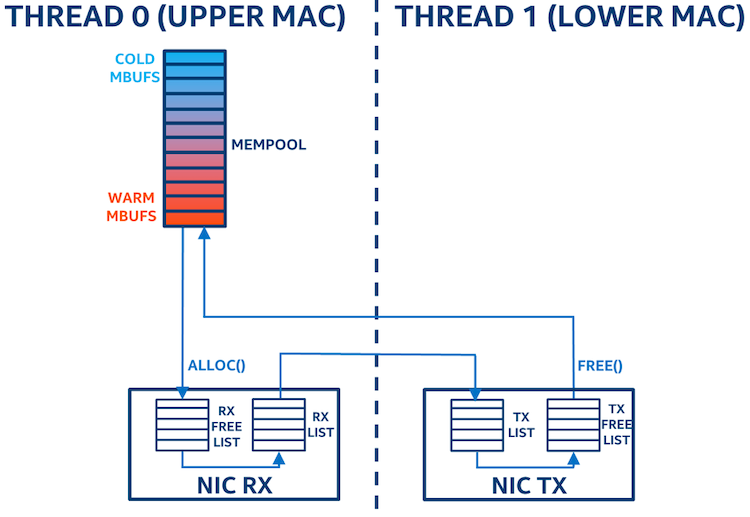
Figure 3: Buffer movement when using stack mempool configuration
Another method attempted was to reduce the memory footprint of the mempools while still using a ring configuration was to reduce the number of mbufs in the mempool (mempool size). Analysis showed that during normal operation about 750 mbufs were in flight in vCMTS – but at times the application could require up to 20,000 mbufs. This meant that reducing the size of the mempool and disabling the mempool cache was not an option, because at times the application may need a number of mbufs that is several orders of magnitude larger than the number needed during normal operation. If those mbufs are not available, the application may perform unpredictably.
When the application uses the stack model, the CPU should be able to keep most of the mbufs required by the application “warm” in the CPU cache, and fewer of them should be evicted from the CPU cache to memory. This is because it will be the same few mbufs reused over and over again from the mempool during normal operation, which will drastically reduce memory bandwidth.
Code Changes Required to Shift from Ring to Stack Mempools
The code modifications required to change an existing DPDK application that uses ring mempools to one that uses stack mempools are relatively minor, as the heavy lifting is done by the DPDK libraries.
- Change the DPDK common base configuration (dpdk/config/common_base).
- CONFIG_RTE_DRIVER_MEMPOOL_STACK needs to be set equal to “y” (“CONFIG_RTE_DRIVER_MEMPOOL_STACK=y”) This ensures that the DPDK stack mempool driver gets compiled. The stack mempool driver is compiled by default, but it’s worth verifying that it is on, especially if you are modifying an existing application.
- “CONFIG_RTE_MBUF_DEFAULT_MEMPOOL_OPS” needs to be set to ‘ “stack” ’ (‘CONFIG_RTE_MBUF_DEFAULT_MEMPOOL_OPS=”stack” ‘) This sets the default mempool type to stack.
- Fully rebuild DPDK after these changes.
- Next, modify the DPDK application itself. Although the default mempool type has been set to stack, it is still advisable to set the mempool type to stack within your application to ensure that the mempool is behaving as expected. While this paper provides guidance for modifying code in three different scenarios, detailed instructions for performing code changes are beyond its scope.
- “rte_mempool_create_empty”: The reference application for this paper used the “rte_mempool_create_empty” function to create its mempools. This means that the “rte_mempool_set_ops_byname” function can be used to set the options for these mempools. This function can only be used on an unpopulated mempool, i.e., just after using the create empty function to create the mempool. Once the mempool is created, ensure that the mempool cache is disabled (i.e., equal to zero). View an example code snippet for this scenario in Figure 4.
- “rte_mempool_create”: If your application creates its mempools using “rte_mempool_create” you may have to change to “rte_mempool_create_empty”. As of this writing, no process exists for changing the type of a mempool after it has been populated, which is done as part of this function; there is no similar function to set the type of the mempool.
- “rte_pktmbuf_pool_create”: If your application uses “rte_pktmbuf_pool_create” change this function to “rte_pktmbuf_pool_create_by_ops” which is almost identical but has an additional parameter for setting the mempool type.
//Create Mempool using variables from the application, cache size should be 0
rte_mempool_create_empty(p->name, p->pool_size, p->buffer_size, p->cache_size, sizeof(struct rte_pktmbuf_pool_private), p->cpu_socket_id, 0);
//Set options for the mempool (Change to stack)
ret = rte_mempool_set_ops_byname(app->mempool[i], "stack", NULL);
//If set options unsuccessful send panic signal
if (ret)
rte_panic("%s mempool set ops error\n", p->name);
Figure 4: Stack mempool creation example code snippet (rte_mempool_create_empty)
In vCMTS, configuration options were added to the application to make it easier to change the mempool type between stack and ring for validation and benchmarking purposes.
- Files to be modified are $MYHOME/vcmts/vcmtsd/docker/docker-image-vcmtsd/config/vcmts-ds.cfg (downstream) and $MYHOME/vcmts/vcmtsd/docker/docker-image-vcmtsd/config/vcmts-us.cfg (upstream).
- These files have configuration options for each mempool under “[MEMPOOLX]” where X is the mempool ID. Configure two mempools in the downstream and four in the upstream.
- Under each mempool is a “type” option that can be either “type = stack” to set up the mempools in a stack configuration or “type = ring” to set up the mempools in a ring configuration. The default mempool type for vCMTS is stack.
- When using ring mempools, mempool cache must be used. Do this by setting the “cache_size” option equal to “256.” When using stack mempools, disable the mempool cache by setting the “cache_size” option equal to “0.”
- Once these configuration options are changed, the Docker* image used to run the vCMTS downstream instances must be rebuilt using the “build_docker_vcmtsd_feat” or “build_docker_vcmtsd_perf” commands.
View examples of a complete stack and ring configuration in Figures 5 and 6.
[MEMPOOL0]
cpu = 0
type = stack
cache_size = 0
Figure 5: vCMTS stack mempool configuration
[MEMPOOL0]
cpu = 0
type = ring
cache_size = 256
Figure 6: vCMTS stack mempool configuration
Test Methodology
The tests were run on a system set up with the following configuration:
- Dual Intel® Xeon® Gold 6148 processors, each with 20 cores, for a total of 40 cores, run at 2.4GHz
- Twelve 8GB dual in-line memory modules (DIMMs) of DDR4 memory
- Four Intel® Ethernet Converged Network Adapter (Intel® Ethernet CNA) X710-DA4 10GbE
- System OS: Ubuntu* 18.04
- Traffic generator was run on a separate system
This system configuration is supported by the reference application vCMTS. For this test, only a single socket from the dual socket system was used, and only downstream instances were run. The memory bandwidth was measured while the system was running 1, 2, 4, 8, or 12 instances of the vCMTS downstream application. The tests were run using a cable internet mix (iMix) packet capture (pcap) to simulate real network traffic. The pcap used for these tests is provided in the vCMTS package (ds_cable-imix2_300cms_4ofdm.pcap). The packet size distribution of this cable iMix is 3% 68 Byte, 1% 932 Byte, and 96% 1520 Byte. The memory bandwidth was measured using the Intel® Performance Counter Monitor (Intel® PCM) memory tool. The application was run for a few minutes at a constant traffic rate, and the memory bandwidth was recorded after it had stabilized.
Results
Four sets of tests were conducted using vCMTS for this paper:
- Cyclic Redundancy Check (CRC) off, Intel® Advanced Encryption Standard New Instructions (Intel® AES-NI) software encryption on at 5Gbps traffic rate on each instance
- CRC on, Intel AES-NI software encryption on at 5Gbps traffic rate on each instance
- CRC off, Intel AES-NI software encryption on at 6.3Gbps traffic rate on each instance
- CRC on, Intel AES-NI software encryption on 5.5Gbps traffic rate on each instance
All tests were conducted with Intel AES-NI software encryption turned on. This encryption was done using the DPDK Cryptodev API, which is based on the Intel® Multi-Buffer Crypto for IPSec library. vCMTS also supports the use of cryptographic accelerators such as Intel® QuickAssist Technology (Intel® QAT). CRC is similar to a checksum for packets and takes extra processing to generate and check, so tests were performed with and without it, as an application may decide to use or not to use it.
The first two tests were conducted at 5 Gigabits per second to allow a comparison between CRC on and off; the last two tests were conducted at the highest zero packet loss (ZPL) traffic rate that could be achieved by that test setup. In all tests, the memory bandwidth was converted from Gigabytes per second to Gigabits per second, and the overall throughput of the system was also graphed as part of the results.
Figure 7 shows the first test, in which CRC was off, Intel AES-NI software encryption was on, and it ran at 5 Gigabits per second traffic rate. There was a significant drop in memory bandwidth for the stack configuration (shown in yellow and orange) versus the ring configuration (shown in blue). The total traffic throughput of all the vCMTS instances is shown in green as a point of reference, calculated by multiplying the traffic rate by the instance count. The largest drop in memory bandwidth (95%) was seen in a single instance. As the number of instances increase, the drop in memory bandwidth is less significant. Two instances showed an 88% drop, four instances experienced an 81% drop, eight instances had a 63% drop, and 12 instances recorded a 42% drop. As the number of instances is increased, more pressure is placed on the CPU’s limited L3 shared cache resources. Therefore, more mbufs will fall out to memory from CPU cache, resulting in lower drop percentages. The average drop in memory bandwidth was 74%, which is a very significant improvement. On the graph, the minimum drop is noted as 33%. This was for the drop in read memory bandwidth for the 12 instance test, and the maximum drop was 97% for the drop in write memory bandwidth for the single instance test. The drop numbers discussed above reference the drop in memory bandwidth for read and write memory bandwidth combined. The minimum and maximum drop numbers noted on the graphs in all the tests refer to the drops associated with the read and write numbers individually.
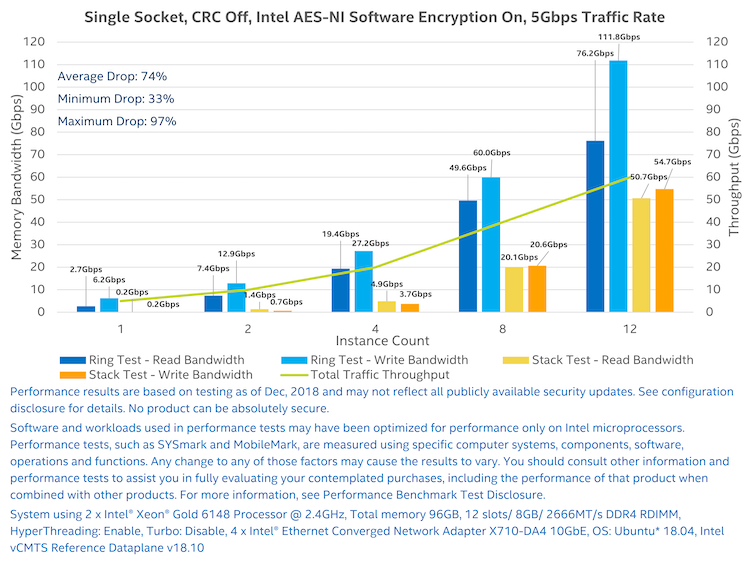
Figure 7: Ring versus stack test result with CRC off
Figure 8 shows the second test, which had all the same conditions as the first test except CRC was turned on. It is clear that there was a significant drop in memory bandwidth for the stack configuration (shown in yellow and orange) versus the ring configuration (shown in blue). 1 instance showed a 96% drop, 2 instances a 91% drop, 4 instances an 87% drop, 8 instances a 65% drop, and 12 instances a 44% drop. The average drop in memory bandwidth was 77%, which is another very significant improvement.
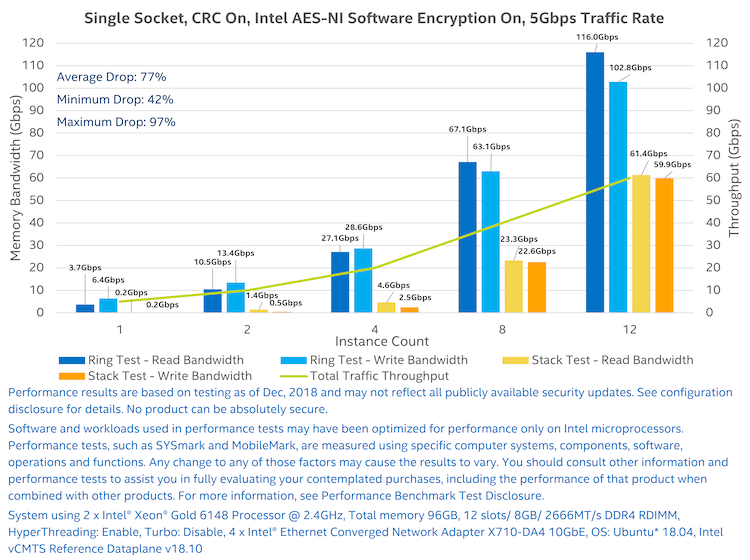
Figure 8: Ring versus stack test result with CRC on
Figure 9 shows the third test, which had CRC off, Intel AES-NI encryption on, and was run at the highest zero packet loss traffic rate of 6.3 Gigabits per second. It is clear that there was a significant drop in memory bandwidth for the stack configuration (shown in yellow and orange) versus the ring configuration (shown in blue). At 1 instance there was a 94% drop, 2 instances an 87% drop, 4 instances a 78% drop, 8 instances a 61% drop, and 12 instances a 46% drop. The average drop in memory bandwidth was 73%, which is another very significant improvement.
Figure 9: Ring versus stack test result – Zero Packet Loss, CRC Off
Figure 10 shows the fourth test, which had all the same conditions as the third test except CRC was turned on. As a result of this, the zero packet loss traffic rate was lower, so this test was conducted using a 5.5 Gigabits per second traffic rate. It is clear that, once again, there was a significant drop in memory bandwidth for the stack configuration (shown in yellow and orange) versus the ring configuration (shown in blue). At 1 instance there was a 95% drop, 2 instances a 91% drop, 4 instances an 84% drop, 8 instances a 76% drop, and 12 instances a 48% drop. The average drop in memory bandwidth was 79%, which is another very significant improvement.
Figure 10: Ring versus stack test result – Zero Packet Loss, CRC On
For the ring model more processing is required overall to deal with a packet as the total contents of the mbufs used must be touched twice. This means more packet accesses per unit time, which probably drives the memory bandwidth up for this model.
These four tests were picked because they created different processing situations and different amounts of memory bandwidth. There are many other variables that could have been changed as part of these tests, but they were not included in this paper.
Other tests were performed to measure the highest zero packet loss traffic rate for vCMTS using ring and stack, but both rates were found to be the same. It was concluded that vCMTS was not memory bound for the amount of available memory bandwidth in the test system, however other deployment models with fewer memory channels might behave differently. If an application is memory bound, changing from ring to stack mempools may make it more performant. Tests were also performed to measure the power usage of a system using vCMTS with ring and with stack. These tests found no significant difference in power consumption.
Conclusion
It is clear that across all four tests, the drop in memory bandwidth due to the change from ring to stack was significant. The average drop across the four tests was 76%. A key benefit of this is, when high traffic rates are run, the data-plane cores are less likely to approach memory bandwidth saturation, which could degrade performance. In this case, a direct performance benefit can be achieved using stack mempool configuration for dual-threaded packet processing applications, as it reduces memory bandwidth utilization and improves the traffic rate at which memory bandwidth gets saturated. Another benefit of this change is the availability of more memory bandwidth for other applications running on the same socket. This modification should require minimal code changes to the application, so the effort would be worth the reward for this change2.
About the Author
Conor Walsh is a software engineering intern with the Architecture Team of Intel’s Network Platform Group (NPG), based in Intel Shannon (Ireland).
Resources
Maximizing the Performance of DOCSIS 3 0/3 1 Processing on Intel® Xeon® Processors
Endnotes
1 This model is more streamlined for the dual sibling hyper-threaded case; it was not tested in a scenario where the threads spanned multiple cores.
2 When vCMTS is changed to stack the system should not have to be populated with as many DIMMs of memory due to the reduced memory bandwidth and this would result in a power saving of roughly seven watts per DIMM. This claim was not verified as part of this paper but it could be a possible way to gain power savings from switching to a stack configuration.