With the wide use of artificial intelligence (AI) technology in the iQIYI video business, the demand for computing power is growing rapidly to support deep learning (DL) in the cloud. The goal of the deep learning cloud platform team is to improve the efficiency of deep learning application deployment, reduce the running cost of the cloud platform, help algorithms and business teams to quickly apply applications and services, and let AI achieve real productivity.
By improving the performance of the inference service on CPUs and migrating the service from GPUs to CPUs to take advantage of the large number of CPU servers in the cluster, the team was able to optimize the CPU-based deep learning inference service and save computing resources.
Deep Learning Inference Service and Optimization Process
Overview of the Deep Learning Inference Service
Deep learning inference services usually refer to deploying trained deep learning models to the cloud and providing the gRPC/HTTP interface request. The functions implemented internally by the inference service include model loading, model version management, batch processing, multi-path support, and service interface encapsulation, as shown in figure 1 below:

Figure 1: Deep learning Inference service workflow
The deep learning inference services commonly used in the industry are TensorFlow* and Amazon Elastic Inference*. Currently, the iQIYI deep learning cloud platform, Jarvis*, provides automatic inference service deployment based on TensorFlow serving. The supported deep learning frameworks and tools include TensorFlow, Caffe*, Caffe2*, MXNet*, and TensorRT. The platform also supports the latest Intel® Distribution of OpenVINO™ toolkit and PyTorch*. In addition, the business team is able to customize specific deep learning service containers and manage services through application engine based on docker.
Optimize Inference Service Workflow
The service optimization process, shown in figure 2, is a process of iteratively moving toward optimization goals.
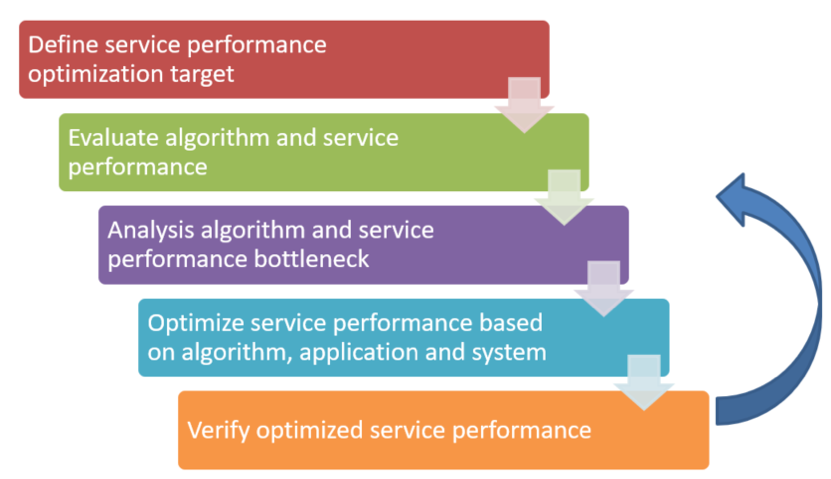
Figure 2. Service optimization process
To optimize the deep learning inference service, the type of service and the main performance metrics first need to be clarified in order to determine the goal of the service optimization. From the perspective of system resources, deep learning services can be divided into computationally intensive or input/output (I/O) intensive services. For example, convolutional neural network (CNN)-based image/video algorithms usually have high computational requirements, and therefore are computationally intensive services. The search and recommendation algorithms that rely on big data have a high feature dimension and a large amount of data and are usually I/O intensive services. From the perspective of quality of service, it can be divided into latency-sensitive services and large-throughput type services. For example, online services usually require lower request response time, and are mostly latency-sensitive services, while offline services are large-throughput type services of batch processing. The goals and methods of deep learning service optimization vary with different service types.
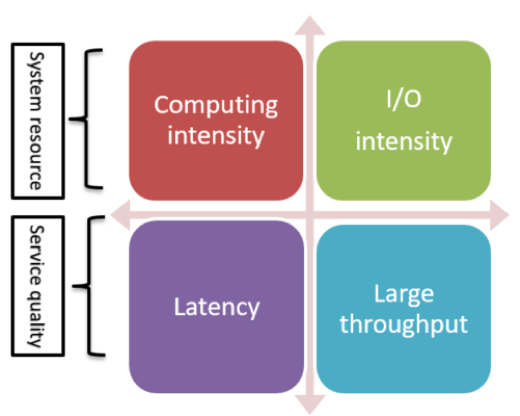
Figure 3. Deep learning inference service
Evaluate the Performance of Deep Learning Inference Service
The main performance metrics of the deep learning service include response latency, throughput, and model accuracy, as shown in figure 4. Latency and throughput are the two main metrics for inference services. After the key metrics are clarified, the service scale can be analyzed and then the performance requirements of each service can be calculated.
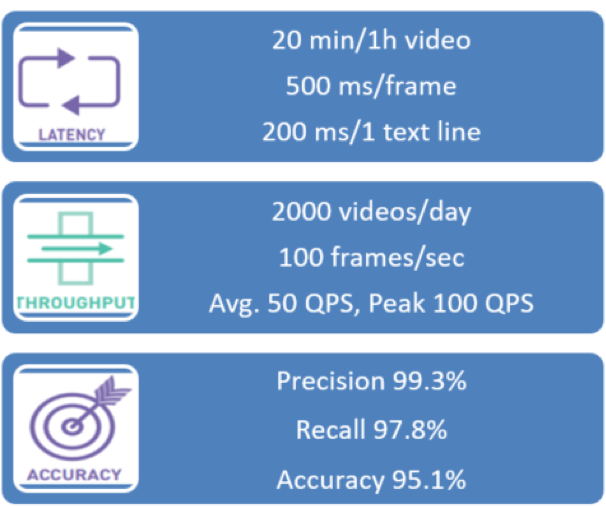
Figure 4. Deep learning inference service performance metrics
Deep Learning Inference Service Optimization on CPU
Methods for Deep Learning Optimization on the CPU
The method of deep learning inference service optimization on the CPU can be divided into system level, application level, and algorithm level. Each level also has corresponding performance analysis tools, as shown below:
Deep Learning Service Optimization Methods and Tools
| Optimization Methods | Profiling Tools |
|---|---|
| Algorithm | |
| Hyper-parameter setting Model structure optimization ow precision model |
TensorBoard* Visual DL |
| Application | |
| Multiprocessing concurrency Asynchronization |
Intel® VTune™ dtrace, strace plockstat, lockstat |
| System | |
| Compiler Option Intel® Math Kernel Library for Deep Neural Networks (Intel® MKL-DNN) Intel® Distribution of OpenVINO™ toolkit |
perf, sar, numactl iostat, vmstat, blktrace Intel® VTune™ |
System-level optimization works to accelerate computing in both the hardware and the platform. The methods include compiler acceleration based on SIMD instruction, parallel computing acceleration based on OMP-based math library, and deep learning acceleration SDK provided by hardware vendors.
Application-level optimization primarily improves the pipelining and concurrency for specific applications and services. The usual deep learning services include not only inference, but also data preprocessing, postprocessing, and network request response. Good concurrency design can effectively improve the end-to-end performance of the server.
The algorithm-level optimization focuses on the deep learning model itself and uses methods such as hyperparameter setting, network structure clipping, and quantization to reduce the size and computational intensity of the model, thereby accelerating the inference process.
Optimize at the System Level
For the system-level optimization on the CPU, the Intel® Math Kernel Library for Deep Neural Networks (Intel® MKL-DNN) and Intel® Distribution of OpenVINO™ toolkit were used. Both methods include the acceleration with SIMD instruction.
Math library optimization has official support for the common deep learning frameworks (TensorFlow, Caffe, MXNet, PyTorch, etc.). Using TensorFlow as an example, download the update for Intel® Optimization for TensorFlow* or build it directly from the GitHub* source code using the parameters below. Refer to the Intel Optimization for TensorFlow Installation Guide.
The usage on Linux is as follows:
Open Anaconda prompt and use the following instruction
conda install tensorflowBuild Tensorflow from source with Intel® MKL
bazel build --config=mkl -c opt --copt=-mavx --copt=-mavx2 --copt=-mfma --copt=-mavx512f --copt=-mavx512pf --copt=-mavx512cd --copt=-mavx512er //tensorflow/tools/pip_package:build_pip_packageIntel® Distribution of OpenVINO™ toolkit optimization method first transforms the native deep learning model, generates the Intermediate Representation(IR), and then calls the Inference engine for model loading and inference service encapsulation. The specific process is as follows in figure 5. For detailed usage, please refer to section 3.
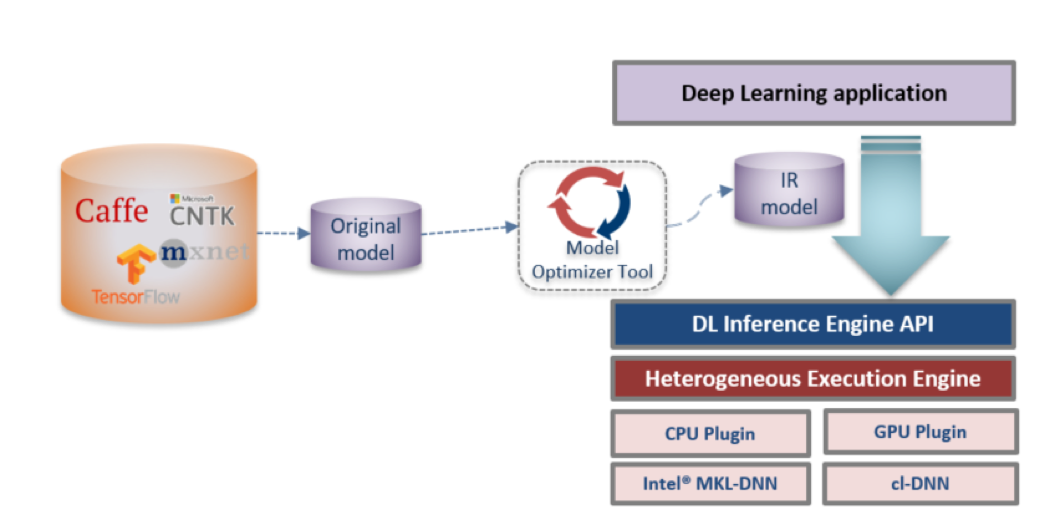
Figure 5. Intel® Distribution of OpenVINO™ toolkit Inference optimization process
Choosing an Optimization Method
A comparison of the two optimization methods is shown below:
Comparison of Intel® Optimized Frameworks and Intel® Distribution of OpenVINO™ Toolkit
| Using Intel® MKL-DNN Optimized Framework | Intel® Distribution of OpenVINO™ Toolkit |
|---|---|
| Pros | |
| Easy to use, no need to modify model Including math library/OpenMP*/Intel® Advanced Vector Extensions (Intel® AVX) optimization Improve performance on both training and inference Support commonly used framework Support model quantization & optimization |
Including math library/OpenMP*/Intel® Advanced Vector Extensions (Intel® AVX) optimization Support more flexible model optimization Support multiple platform optimization: Intel® CPU and GPU processors/Intel® Movidius™ Vision Processing Units (VPUs)/Intel® FPGA Support model quantization & optimization |
| Cons | |
| Optimized performance is not as good as Intel® Distribution of OpenVINO™ toolkit API Only support Intel® CPU optimization |
Only support inference optimization Need to transform the model with Model Optimizer Need to learn Intel® Distribution of OpenVINO™ toolkit API |
Based on the characteristics of the two optimization methods, in practice, the MKL-DNN-based optimization method can be used first to test the service performance. If the service requirements are met, it can be directly deployed. For services with higher performance requirements, you can then try the Intel Distribution of OpenVINO toolkit optimization method.
Optimizing System Performance
The following factors can affect performance for the two system-level optimization methods above:
-
OpenMP* Parameter Settings
Both inference optimization methods use parallel computing acceleration based on OpenMP*, so the configuration of the parameters greatly impacts performance. The recommended configuration for the parameters are as follows:
- OMP_NUM_THREADS = “number of CPU cores in container”
- KMP_BLOCKTIME = 10
- KMP_AFFINITY=granularity=fine, verbose, compact,1,0
-
Number of Deployed CPU Cores
Batch-size impacts the performance of inference services. Online services are generally small batch jobs, and offline services are usually large batch-size jobs.
- For small batch-size jobs such as online service, increasing the number of CPU cores gradually weakens the inference throughput. In practice, 8-16 core CPUs are recommended for service deployment.
- When batch-size is large like in offline service, the inference throughput can increase linearly with the increase of the number of CPU cores. It is recommended to use CPUs with more than 20 cores.
-
CPU Type
Different generations of CPU may have different performance accelerations, depending on the SIMD instruction set. For example, the Intel® Xeon® Gold 6148 has an average inference performance of about two times that of the Intel® Xeon® E5-2650 v4, with the same number of cores, mainly due to the upgrade of the 6148 SIMD instruction set from Intel® Advanced Vector Extensions 2 (Intel® AVX2) to the Intel® Advanced Vector Extensions 512 (Intel® AVX-512).
-
Input Data Format
Many deep learning frameworks, except for TensorFlow, that are used for the input of image-based algorithms recommended using data in an NCHW (Number of images in a batch, Channels, Height, Width) format as input. The original TensorFlow framework supports the NHWC(channels_last) format for CPUs by default. Intel® Optimization for TensorFlow* can support two input data formats. For these two data formats detail info, please refer to the TensorFlow guide on data formats.
Using the two optimization methods above, it is recommended to use NCHW as the input format to reduce the overhead caused by memory data rearrangement in the inference process.
-
Non-Uniform Memory Access (NUMA) Configuration
Configuring non-uniform memory access (NUMA) on the same node usually offers a 5%-10% improvement in performance compared to using different nodes for NUMA-based servers.
Optimize the Application
For application-level optimization, first run a performance analysis testing all aspects of the application end-to-end, find the performance bottleneck of the application, and then implement appropriate optimizations. Performance analysis and testing can be done by adding a timestamp log or by using a timing performance analysis tool such as VTune™ Amplifier. Optimization methods include concurrency and pipeline design, data prefetching and preprocessing, I/O acceleration, and other specific acceleration methods such as encoding and decoding, using libraries or hardware, frame extraction, feature embedding, etc.
As an example, for video quality assessment service the VTune Amplifier can be used for bottleneck analysis and to optimize the service with multi-thread/process concurrency.
The basic process of the video quality assessment service is shown in figure 8. The application reads in a video stream and decodes, frames, and preprocesses it through OpenCV which has been integrated into the Intel Distribution of OpenVINO toolkit. The processed code stream is then passed into the deep learning network, and finally, the set of results are used to grade the video quality and determine the type of the video.
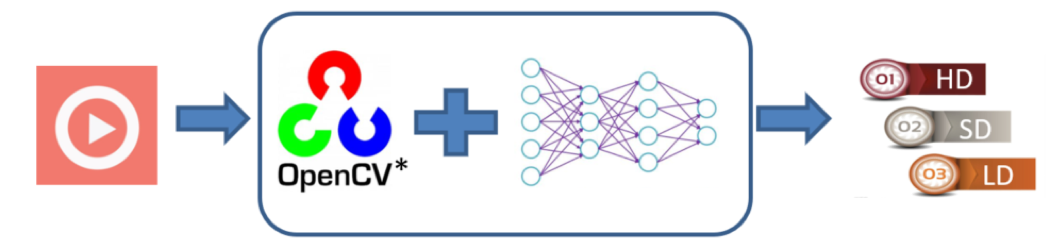
Figure 6. Video quality evaluation process
Figure 7 shows the original application thread fetched by the VTune Amplifier. As shown below, the OpenCV single decoding thread is always busy (brown), while the OpenMP inference thread is often in a wait state (red). The bottleneck for the entire application is in the decoding and preprocessing section of OpenCV.
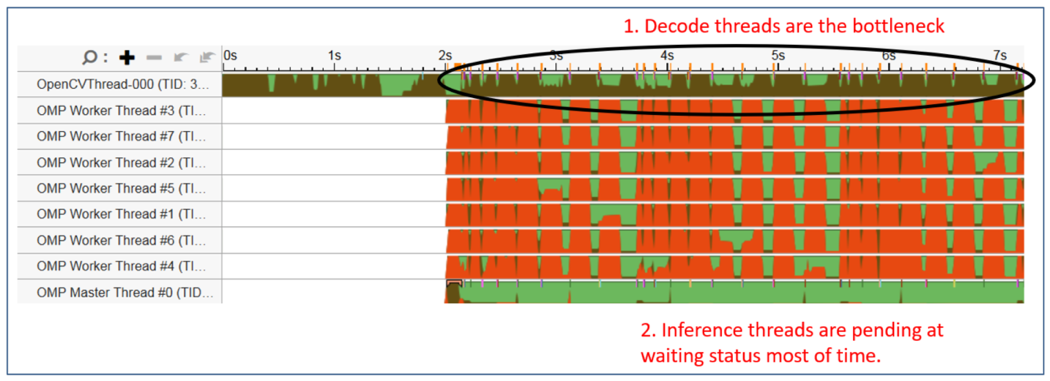
Figure 7. Threads status before application optimization
Figure 8 shows the optimized service thread state. The video stream is decoded concurrently and preprocessed using batch. The processed data is then transferred to the OpenMP threads using batch, optimizing the service.
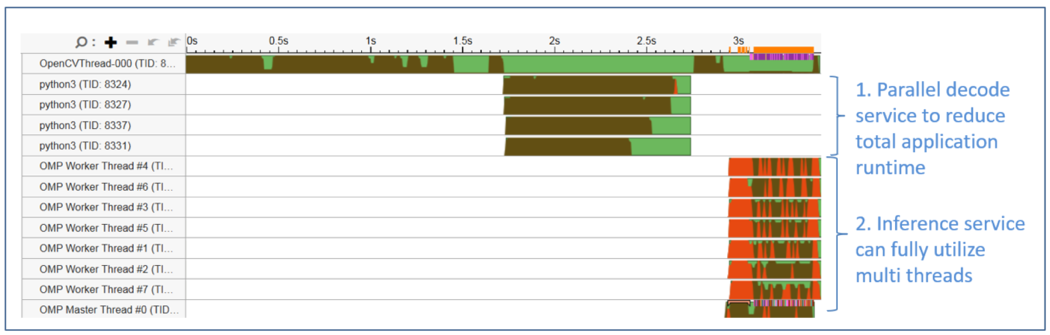
Figure 8. Threads status after parallel optimization of application
After the above simple concurrency optimization, the processing time of the 720-frame video stream is reduced from 7 seconds to 3.5 seconds; the performance is doubled. In addition, the overall performance of the service can be further improved through pipeline design, dedicated decoding hardware acceleration, and other methods.
Optimize the Algorithm
Common algorithm optimization methods improving the performance of inference include batch-size adjustment, model pruning, model quantization, and so on. Model pruning and quantization involve adjusting the model structure and parameters, which usually require algorithm engineers to confirm the model accuracy requirements.
Impact of Batch-size on Inference Efficiency
The basic principle of batch-size selection is to select a small batch-size for latency-sensitive services and a large batch-size for throughput-sensitive services.
Figure 9 shows the effect of choosing a different batch-size on inference service throughput and latency. Test results show that when the batch-size is small, increasing the batch-size appropriately (for example, batch-size from 1 to 2) has less impact on the latency, but can quickly improve the performance of the throughput; when the batch-size is large, increasing its value (for example, from 8 to 32) does not improve throughput, but greatly affects the service latency performance. Therefore, in practice, it is necessary to optimize the selection of batch-size according to the number of CPU cores and service performance requirements of the deployed service node.
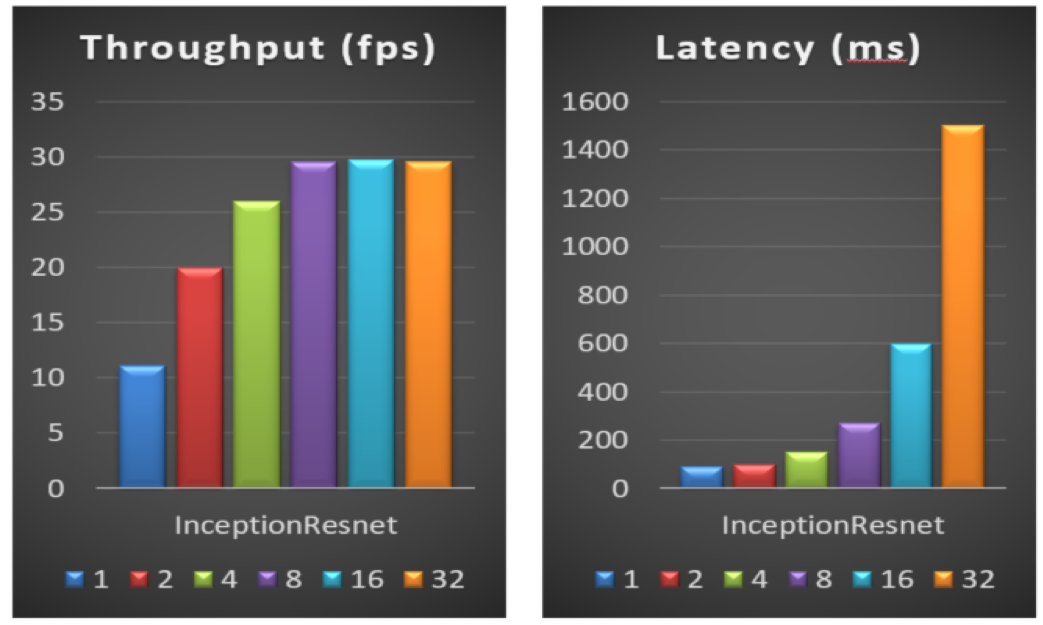
Figure 9. Performance with different batch-size on an Intel® Xeon® processor E5-2650v4
Use Intel® Distribution of OpenVINO™ Toolkit to Accelerate Model Inference
Overview of the Intel® Distribution of OpenVINO™ Toolkit
The Intel Distribution of OpenVINO toolkit provides a quick and effective way to accelerate deep learning model inference from edge-to-cloud platforms on Intel® hardware including CPUs, integrated GPUs, FPGA, and VPU. This section uses the DeepLabV3+ model as an example to discuss the Intel Distribution of OpenVINO toolkit.
As shown in the structure below, the Intel® Deep Learning Deployment Toolkit (Intel® DLDT) is used for model inference and OpenCV for video and image processing. The Intel® Media SDK can be used to accelerate the video/audio codec and processing in the pipeline of a video/image AI workload.
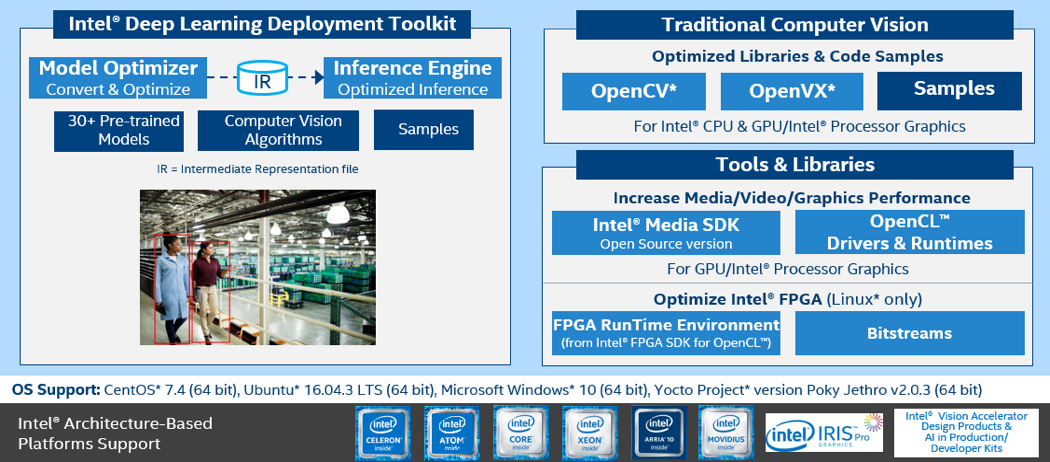
Figure 10. Overview of the Intel® Distribution of OpenVINO™ toolkit
Using the Intel® Distribution of OpenVINO™ Toolkit
The Python* program of Model Optimizer (MO) is used under the command line interpreter for offline model conversion from popular frameworks to intermediate representation (IR). Commands to convert TensorFlow* model by Model Optimization:
If the model files do not have standard extensions, you can use –framework {tf, caffe, kaldi, onnx, mxnet} option to specify the framework type explicitly.
For example, the following commands are equivalent:
python3 mo.py --input_model /usr/models/model.pbpython3 mo.py --framework tf --input_model /usr/models/model.pbThe IR file generated will be loaded by the Inference Engine (IE) for runtime model inference. Currently, Intel Distribution of OpenVINO toolkit supports Caffe*, TensorFlow*, MXNet*, ONNX*, and Kaldi*; for a more detailed usage of the MO, refer to the online documents and user guide.
Program with IE for C++ or Python API can be used to implement and optimize cross-platform runtime inference. The inference engine supports optimization based on Intel hardware including CPUs, integrated GPUs, VPU, FPGA and Intel® Gaussian & Neural Accelerator (Intel® GNA) through low-level performance libraries. For instance, on the CPU side, the Intel DLDT replies upon Intel® MKL-DNN to bring performance gains for layer implementation of network topology during the inference process. Recently, the OpenVINO™ has been open sourced, user can add and rewrite custom defined classes and re-build the source code to generate a customized deep learning deployment toolkit.
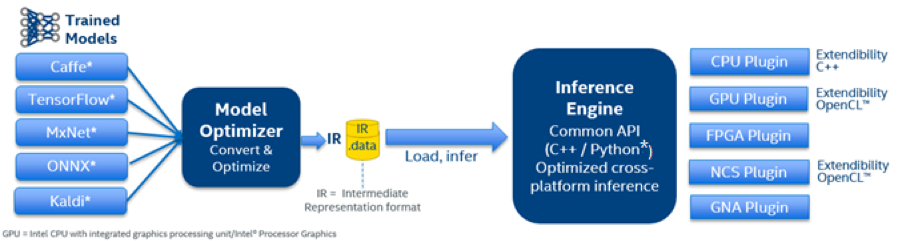
Figure 11. Structure of Intel® Deep Learning Deployment Toolkit
The Intel Distribution of OpenVINO toolkit also provides heterogeneous computing, asynchronous inference mode, INT8 model inference, and throughput stream mode to meet the real requests for AI/DL project development and to achieve higher performance optimization.
Intel® Distribution of OpenVINO™ Toolkit Commercial Use Case
Deep learning neural network inference has been widely used for intelligent image, text and voice recognition and detection for industrial and commercial applications.
iQIYI shows a great example of DL usage: the non-blocking of live comments. Live comments are real-time comments displayed on top of videos. The smart video platform can make the comments that overlap with portraits in the video frame stay in the background instead of blocking them.

Figure 12. The effect picture of non-blocking smart live comments
This functionality can be implemented through image matting on each single video frame through the inference of a semantic image segmentation model. Compared with traditional computer vision algorithms, the convolutional neural network inference method can provide more accurate results and easier deployment for various complex textures and scenes, for example, similar colors of foreground and background. It’s a flexible solution that developers can fine-tune to balance the inference performance and accuracy.
The DeeplabV3+ model, known as Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution, and Fully Connected CRFs, can be used to achieve the expected functionality. Additional information on the DeeplabV3+ model, which supports encoder-decoder structures containing atrous spatial pyramid pooling (ASPP) modules and the Xception Convolution structure, can be referenced in the Deeplab Inference Guide.
To optimize the inference workload with the Intel Distribution of OpenVINO toolkit, readers can follow the script in the GitHub* Case Repository.
The idea is to use the model cutting features of Model Optimizer to cut-off preprocessing part of the model. The main workload with MobilenetV2 will be reserved for inference while other operations can still be implemented by TensorFlow. The steps to use deeplabV3+ with the Intel Distribution of OpenVINO toolkit are shown below:
-
Model Optimize Commands:
python mo_tf.py --input_model ./model/DeeplabV3plus_mobileNetV2.pb --input 0:MobilenetV2/Conv/Conv2D --output ArgMax --input_shape [1,513,513,3] --output_dir ./model -
Run Inference Engine sample:
Python infer_IE_TF.py -m ./model/DeeplabV3plus_mobileNetV2.xml -I ./test_img/test.jpg -d CPU -l ${INTEL_CVSDK_DIR}/deployment_tools/inference_engine/samples/intel64/Release/lib/libcpu_extension.so
According to iQIYI’s work on the Intel® Xeon® platform, the Intel Distribution of OpenVINO toolkit offers a very significant boost of speed for various CNN FP32 models applied in AI video projects.
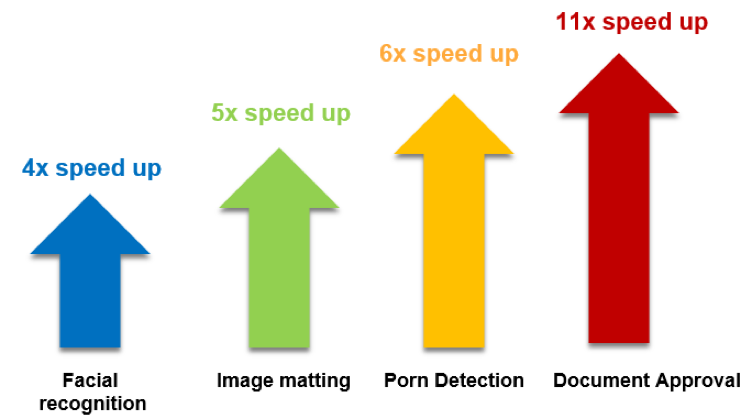
Figure 13. Performance improvement of CNN FP32 models applied in AI video projects (performance data provided by iQIYI)
According to above chart, the performance of the deeplabV3 model for image matting can be improved five times, and the performance of text detection model for documents have 11 times speed up with the Intel Distribution of OpenVINO toolkit on Intel® Xeon® processors.
According to the tests completed by iQIYI on their own application development environment, the performance of different FP32 deep learning neural networks can be improved from 4 to 9 times by using the Intel Distribution of OpenVINO toolkit on Intel® Xeon® E5 processors. Furthermore, when using Intel® Xeon® Gold 6148 processor users can achieve another 2x speedup (performance data provided by iQIYI).
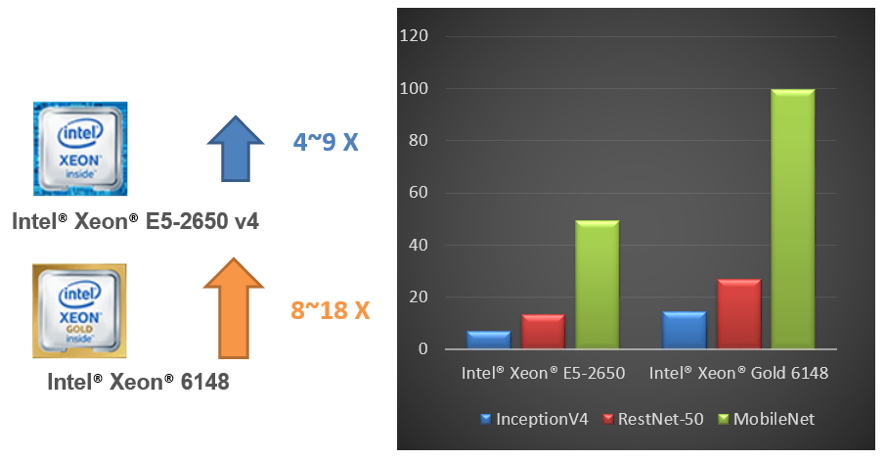
Figure 14. Performance on Intel® Xeon® and Intel® Xeon® Gold with OpenVINO™ (performance data provided by iQIYI)
Summary and Outlook
The system-level optimization method introduced above has already been applied in over ten applications and algorithms in iQIYI deep learning cloud platform, deploying thousands of cores. The average performance is improved 4-11 times (Refer to figure 15).
For deep learning inference service optimization, the deep learning cloud platform also plans to add more heterogeneous computing resources such as VPU and FPGA, to accelerate specific tasks. At the same time, in terms of service flexibility, scheduling optimization and the automatic selection of parameters, iQIYI plans to further optimize the service to more fully utilize the computing resources available and make the deep learning inference services ready sooner.
About the Authors
Lei Zhang
Lei Zhang is a senior Software Engineer in Infrastructure and Intelligent Content Distribution Business Group at iQIYI. His major job now is to develop the Deep Learning Cloud platform to facilitate the algorithm training and deployment, meanwhile to optimize the performance for deep learning models and applications. He has eight years of experience on Linux* system and driver software development. Lei holds a Master of Science degree in EE from Zhejiang University.
Feng Dong
Feng Dong is a Researcher, leading Intelligent Acceleration Team at Intelligent Platform Division (IPD), IIG, iQIYI. Feng's responsibility includes the acceleration of AI models and AI services on different hardware platforms such as CPU, GPU and FPGA. Prior to iQIYI, Feng was a Senior Staff Engineer at Lattice Semiconductor (acquired Silicon Image). Feng's main interests are in Hardware/Software Co-design and Optimization. Feng holds a Master of Science degree in Computer Systems Organization from Shanghai Jiao Tong University and has more than 10 years of experience in the semiconductor industry.
Yuping Zhao
Artificial Intelligence Technical Specialist, Sales and Marketing Group, Intel. Yuping is responsible technical support and consultant for Intel's data center AI solution in PRC. Yuping is experienced in AI and HPC, especially in application optimization on Intel® architecture. Prior to joining Intel, she worked as a senior technical consultant for HP and Lenovo, responsible for technical consulting for HPC and cloud solutions. Yuping holds a Master’s degree of computer science from University of Science and Technology Beijing, PRC.
Fiona Zhao
Fiona Zhao is a Technical Consulting Engineer, Intel Architecture Graphics and Software and provides technical supports of Intel artificial intelligent and computer vision products, including Intel OpenVINO Inference Engine, Intel MediaSDK and Intel MKL-DNN. Enabling worldwide strategic customers and partners to be successful on Intel® architecture by professional algorithm optimization, program tuning and performance accelerating solutions. Prior to Inference Engine support, Fiona was focused on math libraries for linear algebra, image processing and machine learning. Fiona holds a Master of Science degree in Software Engineer from Southampton University.
Ying Hu
Ying Hu is a Senior Technical Consulting Engineer, Intel Architecture Graphics and Software and provides technical expertise in Intel software tools, Intel AI frameworks and high-performance libraries on Intel® architectures. She joined Intel 15 years ago and has rich experience in enabling global developers, enterprise users, engineers & researchers to use Intel software including MKL/MKL-DNN, IPP/DAAL in Machine learning, Deep Learning, HPC etc. She holds PhD on Pattern Recognition and Intelligent System.
Jason Wang
Jason Wang is Technical Account Manager of Intel Sales and Marketing Group. He is responsible for evangelizing and winning Intel AI/Cloud solutions for some major CSP customers in China. As trusted technical advisor, Jason demonstrates how Intel based products and solutions solve customer’s business and technical problems. Prior to joining Intel, Jason worked for Dell as senior solution architect for CSP customers. Before that, he was principal software engineer of EMC. Jason holds a master’s degree in computer science from Southwest Jiaotong University.
Related Links
GitHub* repository for Intel® MKL-DNN
Intel® Optimization for TensorFlow* installation guide
Intel® Distribution of OpenVINO™ toolkit
GitHub* repository for OpenCV and DLDT