- Performance Improvement Opportunities with NUMA Hardware
- NUMA Hardware Target Audience
- Modern Memory Subsystem Benefits for Database Codes, Linear Algebra Codes, Big Data, and Enterprise Storage
- Memory Performance in a Nutshell
- Data Persistence in a Nutshell
- Hardware and Software Approach for Using NUMA Systems
If you are reading this, you may be thinking: Can I use Intel's non-uniform memory access (NUMA) hardware and the related tools and strategies to solve my current problem? The answer depends on the problem you are facing and if you can make decisions about choosing/changing your hardware, your software, or both.
If you can make decisions about choosing/changing your hardware:
- Do you have an existing, diverse workload, but little control over the software?
- Do you have an existing, specific workload, but little control over the software?
- Do you have an existing, specific workload, with software you can change?
- Are you putting together new hardware and software to solve an important problem that has not be addressable until now?
If you can make decisions about writing/modifying software, there are different questions:
- Must the software run on a range of hardware configurations?
- Must the software run on a specific hardware configuration?
- Do you have control over the specific hardware configuration?
The following sections summarize how answers to these questions intersect with the new memory hardware trends:
- Diverse workload
- Specific workload
- Modifiable software or software that runs on a range of hardware configurations
- Software that runs on a specific hardware configuration
- Modifiable software and hardware
Diverse Workload
- Multi-Channel DRAM (MCDRAM) & High-Bandwidth Memory (HBM) – If your workload already runs well on Intel® Xeon Phi™ products, it will continue to run well. The higher bandwidth means a significantly higher L2 cache miss rate can be tolerated.
- Future 3D XPoint™ Technology – If your workload is currently I/O bound, the 3D XPoint solid state drives (SSDs) and persistent memory file system may eliminate this bottleneck. You may also be able to fit more non-I/O-bound processes on the I/O-bound system without increasing the paging and other I/O.
- Intel® Omni-Path Fabric (Intel® OP Fabric) – Intel OP Fabric supports a greater diversity of programming models than older fabrics.
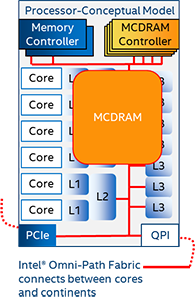
Specific Workload
- MCDRAM & HBM – It is easier to make the measurements needed for this decision than when supporting diverse workloads; otherwise the issues are the same. If you decide to have a mixture of Intel® Xeon® and Intel Xeon Phi products and write software to exploit both products simultaneously, remember that Intel Xeon products work best with software with complex control flows, whereas Intel Xeon Phi products work best with vectorized software when most memory accesses hit the caches.
- Future 3D XPoint Technology – Workloads with few write access misses of the on-processor caches may cope with the slower write performance, and workloads where the large capacity can be exploited to reduce I/O may also benefit.
- Intel OP Fabric – Intel OP Fabric works well with software that requires many cores aimed at many different areas of a large data set. If your software takes excessive time to move data between MPI nodes, adding a partitioned global address space (PGAS) framework may alleviate this bottleneck.
Modifiable Software or Software That Runs on a Range of Hardware Configurations
Fortunately, the techniques needed to get the most benefit out of these hardware technologies do not require you to make otherwise useless changes to your programs. Instead, the techniques improve the performance on a wide range of past, present, and future hardware.
- MCDRAM & HBM – You can modify most workloads to use cache-aware or cache-oblivious algorithms to fit in the large caches provided by/with these technologies. These techniques do not permeate the software, and can be used for optimizing accesses in a wide range of hardware configurations.
- Future 3D XPoint Technology – You can modify most workloads to use cache-aware or cache-oblivious algorithms to fit in the large caches that may be provided by/with this technology. These techniques do not permeate the software, and may be used for optimizing accesses in a wide range of hardware configurations.
- Intel OP Fabric – Frameworks or libraries such as heterogeneous streams (hStreams) make it practical to exploit the characteristics of whatever hardware configuration your software runs on.
Software That Runs on a Specific Hardware Configuration
- MCDRAM & HBM – If your software can be parallelized and has few misses of the L2 caches (perhaps because it uses cache-aware or cache-oblivious algorithms), the high bandwidth of MCDRAM and HBM memory enables your program to use more cores effectively than if the traffic had to go to dual inline-memory modules (DIMMs).
- Future 3D XPoint Technology – In addition to the techniques for adapting to any hardware configuration, the extra capacity of 3D XPoint devices may enable using a different algorithm or keeping, rather than recomputing, temporary data. This may save time.
- Intel OP Fabric – It is easier to write software with hard-to-implement data sharing using the PGAS that the Intel OP Fabric enables than using MPI messaging.
Modifiable Software and Hardware
- MCDRAM & HBM – If your software can be parallelized and has few misses of the L2 caches (perhaps because it uses cache-aware or cache-oblivious algorithms), the high bandwidth of MCDRAM and HBM memory enables your program to use more cores effectively than if the traffic had to go to DIMMs .
- Future 3D XPoint Technology – 3D XPoint technology may provide the ability to store lots of data near cores, and to keep it without writing it to disk.
- Intel OP Fabric – Intel OP Fabric lets you quickly and easily move data to where it is needed, and to easily access data that is rarely used.
Summary
The previous article, Performance Improvement Opportunities with NUMA, introduced new memory subsystem hardware technologies that affect performance. This article shows that most applications can benefit in some way from these technologies. The next article, Modern Memory Subsystem Benefits for Database Codes, Linear Algebra Codes, Big Data, and Enterprise Storage, starts describing how to apply these technologies to various application types.
About the Author
Bevin Brett is a Principal Engineer at Intel Corporation, working on tools to help programmers and system users improve application performance. The systems Bevin discusses here are a far cry from the 4-KB core memory, 40-KHz, PDP-11 machines he first programmed.