
Resource management in Kubernetes* is a hot topic, with multiple new proposals around how to improve things both in Kubernetes and container runtimes. Up until recently, the Kubernetes resource management model consisted of features that have been in place for years, including:
- The kubelet control plane and scheduler, which communicate to keep track of resources on the node
- Kubelet and its resource managers, which manage allocation for CPU, memory, and devices
- Different flavors of runtimes, such as the containerd project and CRI-O project
- Lower-level components like runc, crun, and Kata Containers*
Now, several new features are driving improvements to the resource model across Kubernetes, such as: kubelet resource managers updates, dynamic resource allocation (DRA), container runtime enhancements, Node Resource Interface (NRI) plugins, and control group (cgroup) v2 updates.
At KubeCon + CloudNativeCon Europe 2023, members of Intel, Red Hat*, NVIDIA*, and Google* joined a panel discussion to provide an overview of these proposals and share what they mean for Kubernetes users. Watch the full 36-minute session on YouTube*.
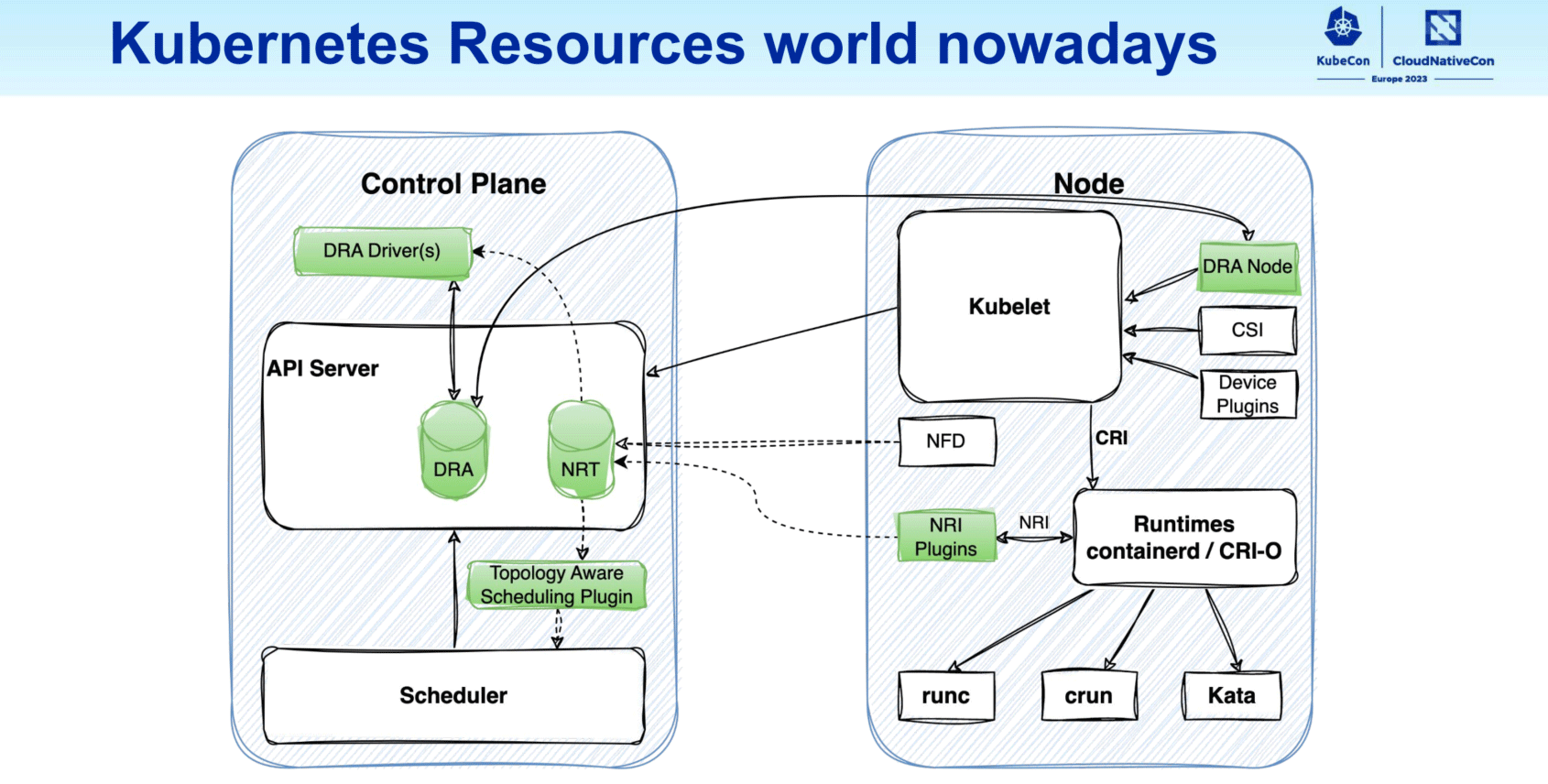
Recent proposals (in green) aim to evolve resource management in Kubernetes.
Enhancements to kubelet resource managers
As part of a recent initiative to avoid perma-beta features, the Topology Manager, CPU Manager, and Device Manager have graduated to generally available (GA).
Read more about them:
Flexibly allocate resources with DRA
Another recent improvement is dynamic resource allocation (DRA), an API introduced in Kubernetes 1.26. Before this, Kubernetes could only handle integer-countable resources, such as RAM and CPU. DRA enables users to leverage more-complex accelerators in Kubernetes, as well as devices that require additional setup parameters. Additionally, while device plugins limit users to assigning a device to one container, DRA enables GPU devices to be shared across different containers and pods so you can flexibly choose how they’re used. Using Container Device Interface (CDI) as a common specification, DRA defines how device resources look from the node all the way down to the runtime.
- Visit the DRA GitHub repo
- Watch “Device Plugins 2.0: How to Build a Driver for Dynamic Resource Allocation”
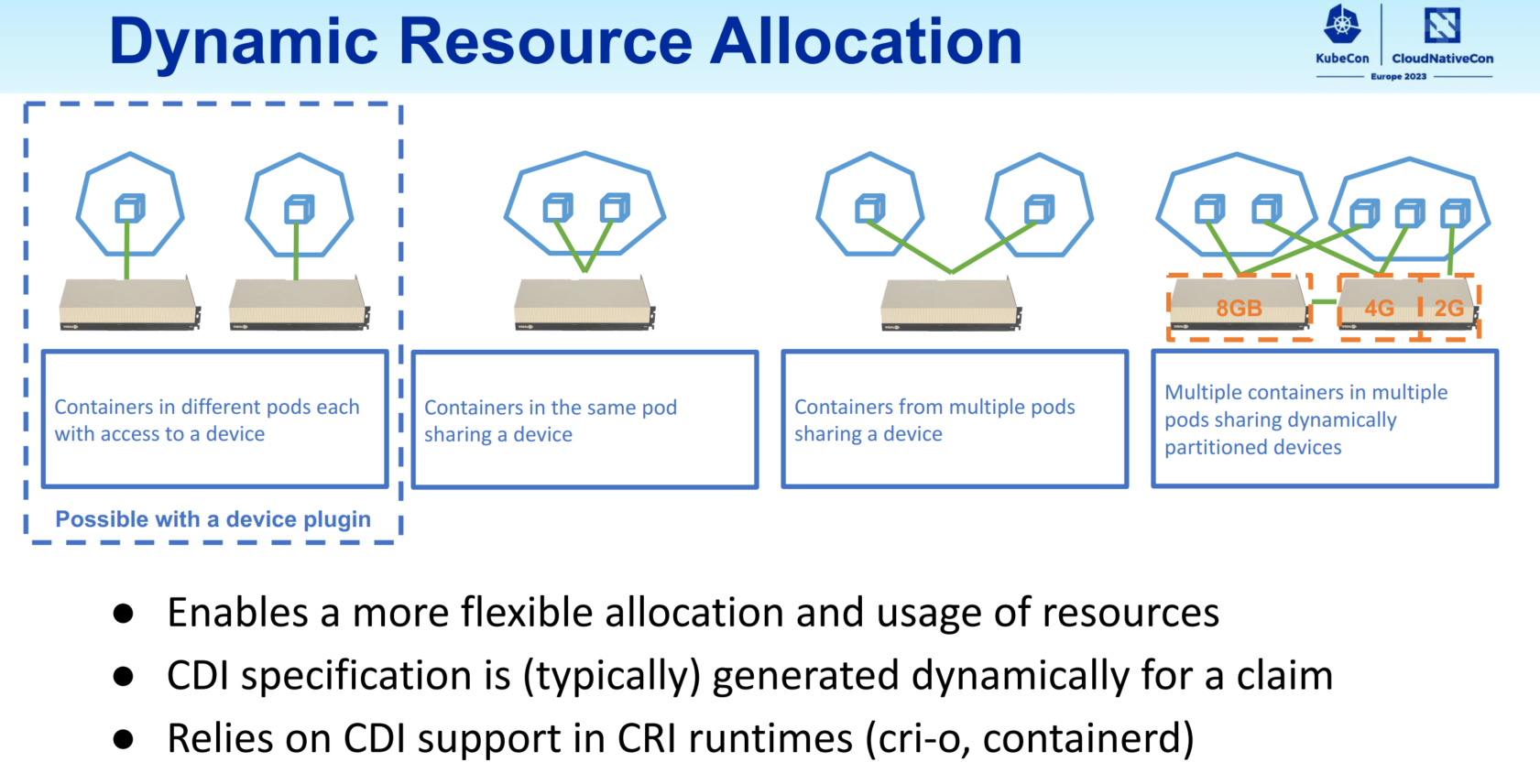
The DRA API makes it easy to enable hardware devices in Kubernetes and allocate them across containers and pods.
Driving enhancements through container runtimes
There’s a lot of talk about enhancements enabled at the node level or by the kubelet, but container runtimes are also driving new features, including:
- Open telemetry tracing enhancements that collect and correlate logs with metrics to provide a more accurate picture of how a node uses resources and helps identify problems
- Seccomp notifier support, which informs us about negative impacts of syscalls on a single node and how they impact resources
- Vertical pod order scaling support
- New features as part of containerd 1.7, including a new sandbox API that enables better management of containers as a unit, additional features around transfer service, and support for NRI
It’s not enough to enable features on the container runtime side only; Red Hat also works in upstream Kubernetes to make enhancements on the Kubernetes side to deliver end-to-end support.
Example enhancements include:
- OpenTelemetry tracing enhancements to the kubelet provide more information about the pod life cycle and garbage collectors, bundling it on a single node to help us understand how resource usage is applied to a node.
- To support the evented port lifecycle event generator (PLEG), which is used to synchronize states between workloads and containers, we enhanced the Container Runtime Interface (CRI) and added dedicated support to the container runtime.
- Updates are planned for the user namespaces and swap support to deliver dedicated support for the kubelet.
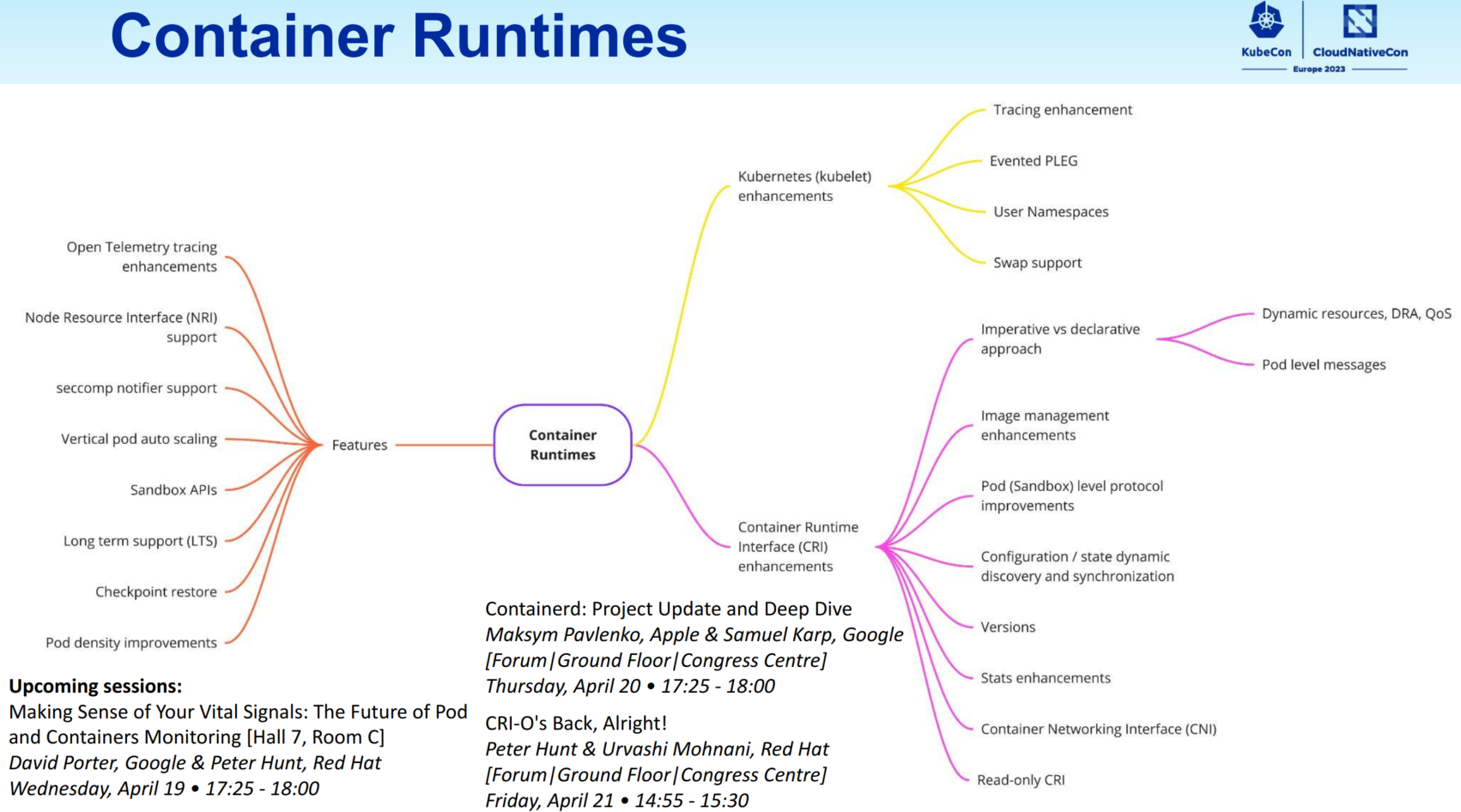
Container runtime features must be supported on the upstream Kubernetes side to create an end-to-end delivery model.
A common infrastructure for plugging custom logic into runtimes
NRI started as a subproject of containerd but has since evolved into a common infrastructure for plugging extensions into CRI runtimes, implemented in containerd 1.7 and CRI-O 1.26. NRI captures all the internal logic of your container from your runtime and allows you to adjust container properties on the fly, like resource limits and CPU memory, offering more flexibility using out-of-tree components than the kubelet or current in-tree functionality. Serving as the building block between features, NRI lets users plug custom logic from hardware vendors into their cluster and—using Node Resource Topology (NRT), which we’ll cover in the next section—share it across features such as runtimes, the scheduler extension, kubelet, and DRA.
- Go to the NRI GitHub repo
- Visit the NRI plugins GitHub repo
- Watch the talk “NRI: Extending containerd and CRI-O with Common Plugins” for more details.

NRI as implemented in containerd 1.7 and CRI-O 1.26.
Enabling topology-aware scheduling
To enable NRI, we first needed to introduce NRT to enable topology-aware scheduling. NRT is a custom resource definition (CRD)‒based API that enables topology-aware scheduling in Kubernetes. NRT is an out-of-tree component that comprises two components: the NFD-topology updater that exposes hardware topology information as custom resource instances created per node and the TAS Scheduler plugin that uses the information to make topology-aware scheduling decisions. Designed to provide more-granular information of resources, NRT delivers topology-aware scheduling across non-uniform memory access (NUMA) and shares resource capacity and availability.
After we developed NRT, our community of partners and customers helped us discover new use cases beyond topology-aware scheduling. For instance, the resource policies implemented as NRI plugins are using NRT to share internal state assignments, which in turn can be used by other components like DRA controllers or scheduler plugins.
- Check out the NRT GitHub repo
- Watch this KubeCon + CloudNativeCon Europe 2022 talk “Resource Orchestration of HPC on Kubernetes: Where We Are Now and the Journey Ahead!”
The cgroup v2 Road Map
Whether you’re leveraging devices or not, every container out there uses CPU and memory. Control group (cgroup) is what allows you to allocate CPU and memory resources to your containers. cgroup v2 recently graduated to GA in Kubernetes 1.25, offering a new platform that can enable new resource management capabilities in Kubernetes. Examples include:
- MemoryQoS is currently in alpha for Kubernetes 1.27 and provides memory guarantees to ensure your pod always has access to a minimum level of memory.
- PSI metrics for eviction provides metrics around resource shortages such as CPU pressure or memory pressure; we’re hoping to enable kubelet to take advantage of these metrics to make more-informed decisions, such as which pods to evict and how to prioritize pods based on which resources they access.
- We hope to enable IO isolation to let users set certain guarantees around resource usage when multiple pods are competing for shared IO resources on a node.
- Swap is in alpha now, and there are plans to extend support to many additional apps, such as allocating large amounts of memory that can’t fit into main RAM.
- More work is planned around network capabilities, ensuring pods have access to the network and are able to provide QS guarantees.
Watch the talk “Cgroupv2 Is Coming Soon To a Cluster Near You” for more details.
Get Involved and Leave Feedback
With the new resource management framework in place, the panel encourages you to get involved. Explore more resources, or join the Slack* channels to join the discussion and leave feedback:
- GitHub: Cloud Native Computing Foundation (CNCF) Technical Advisory Group for Runtime (TAG-Runtime)
- Slack channel #tag-runtime
- Slack channel #containerd
- Slack channel #crio
You can also get involved with the SIG Node community:
About the Presenters
Alexander Kanevskiy Principal Engineer, Cloud Orchestration Software, Intel, focuses on various aspects in Kubernetes: resource management, device plugins for hardware accelerators, cluster lifecycle, and cluster APIs. He has over 25 years of experience in areas of Linux* distributions, SCM, networking, infrastructure, release engineering, cloud orchestration, continuous integration and delivery. He’s also an active member of Kubernetes SIG-Node and CNCF TAG-Runtimes.
Swati Sehgal, Principal Software Engineer, Red Hat, works to enhance OpenShift* and its platform to deliver best-in-class networking applications, leading-edge solutions, and innovative enhancements across the stack. She’s currently serves as a cochair of Kubernetes Batch Working Group and has been actively involved in the resource management area contributing to Kubernetes and its ecosystem with focus on resource managers in kubelet, enabling topology-aware scheduling and facilitating enablement of specialized hardware on Kubernetes.
David Porter, Senior Software Engineer, Google on the Kubernetes GKE node team. His focus is on the kubelet node agent and the resource management area. He’s the primary maintainer of cAdvisor, a resource monitoring library widely used in Kubernetes; reviewer of a SIG-Node; and a recognized active member of the SIG-Node community.
Sascha Grunert, Senior Software Engineer, Red Hat, works on many different container-related open source projects, like Kubernetes and CRI-O. His passions include contributing to open source, as well as giving talks and evangelizing Kubernetes-related technologies. He joined SIG Release in the beginning of the Kubernetes 1.14 release cycle to boost the community and provide a different perspective from his daily work.
Evan Lezar , Senior Systems Software Engineer, is part of the cloud native team at NVIDIA. His focus is making GPUs and other NVIDIA devices easily accessible from containerized environments. Prior to joining NVIDIA, he worked at Amazon*, Mesosphere*, Zalando*, and Altair Engineering*.