Overview
The Intel® Distribution of OpenVINO™ toolkit support on Raspberry Pi* only includes the inference engine module of the Intel® distribution of OpenVINO™ toolkit.
The model downloader and model optimizer are not supported on this platform but work.
The inference engine requires optimized models. Optimized models processed through the Model Optimizer are available in the full desktop version. These models consist of intermediate representation (IR) or a .bin and .xml file.
Requires
- OpenVINO™ toolkit installed on supported system with GNU Linux* distribution.
- Instructions for installation of OpenVINO toolkit on GNU Linux
- The latest OpenVINO toolkit inference engine installed on Raspbian.or Raspberry Pi OS.
Obtain Optimized models
There are multiple ways you can obtain the optimized models.
Download Pre-Trained models
Download pre-trained models from the Intel® Open Source Technology Center.
Select the link that corresponds to your release.
Click on the open_model_zoo to browse the pre-trained models.
Use Pre-Trained Models From A Full Install
Use the pre-trained models from a full Intel Distribution of OpenVINO toolkit install on one of the supported platforms.
For more information about the location of the pre-trained models in a full install, visit the Pretrained Models.
Transfer Downloader and Optimizer and Run on Raspberry Pi*
Download and optimize the models on Raspbian using the Model Downloader and Model Optimizer.
Transfer Model Optimizer and Model Downloader to the Raspberry Pi from a full install.
See Get Started.
Run Optimizer on Desktop and Transfer to Raspberry Pi
Run Model Optimizer on the desktop or full install, transfer files to the Rasbperry Pi.
Model Downloader and Model Optimizer
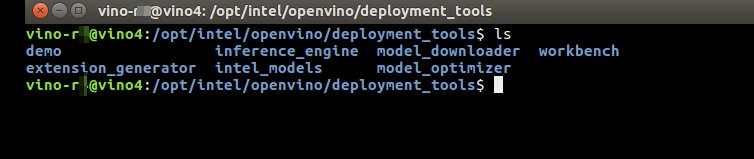
Model Downloader
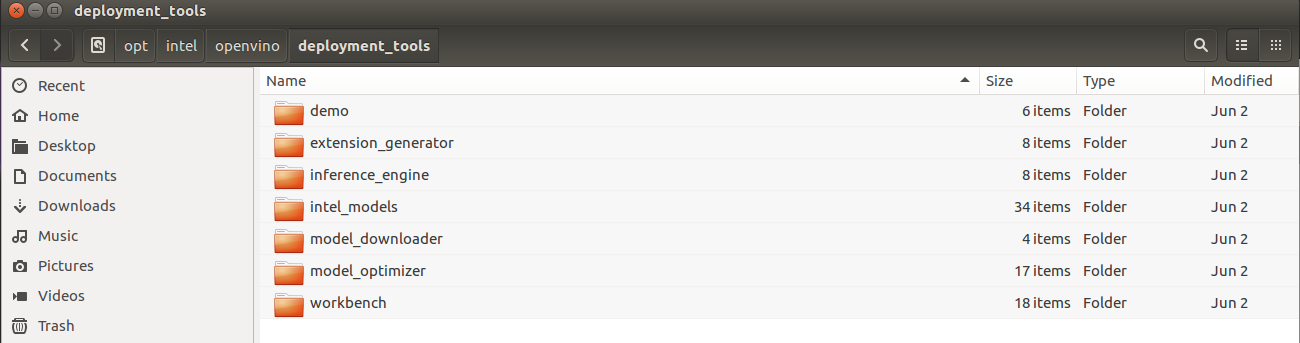
Where it Is
For the latest full install, the Downloader is located here:
The Model Downloader contains a collection of pre-trained models along with the download location for each one displayed. This way, you can easily find those downloads.
What it Is
The Model Downloader provides a command line interface for developers to download various publicly available open source pre-trained Deep Neural Network (DNN) models, in a variety of problem domains.
For more information about the model downloader, visit Model Downloader Essentials.
Note: Although the Model Downloader is written in Python*, you can use the models that you download with any of the programming languages supported by the Intel Distribution of OpenVINO toolkit.
Model Optimizer
Where it is
For the latest full install, the optimizer is located here:
What it is
Model Optimizer is a cross-platform command-line tool that facilitates the transition between the training and deployment environment, performs static model analysis, and adjusts deep learning models for optimal execution on end-point target devices.
Deep Learning Framework
Model Optimizer process assumes you have a network model trained using a supported deep learning framework. The visual below illustrates the typical workflow for deploying a trained deep learning model.
How it Works


For more detailed information about the model optimizer, visit the Model Optimizer Developer Guide.
Get Started
Equipment Needed to Get Started
Hardware
- Raspberry Pi 3B+
- Raspberry Pi 3A+
Software
- Raspbian 9 (Stretch) OS
- OpenVINO inference engine software from Intel Open Source Technology Center
- Completed full or host install of OpenVINO toolkit
Prerequisites
To run the converted or optimized models that are downloaded in this article with the benchmark_app, build benchmark_app.
ARMv7
Create a build directory.
Build the benchmark app on the Raspberry Pi.
Build the sample.
Benchmark_app is found in the samples directory.
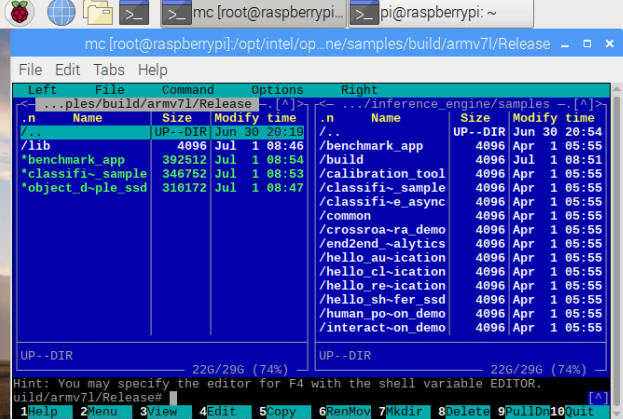
Figure 1. Location of benchmark_app.
Transfer Model Downloader and Model Optimizer to Raspberry Pi
From a completed full or host install of OpenVINO toolkit - transfer the directories to the Raspberry Pi.
There are several ways you can do this:
- You could create an archive
- You might use Nextcloud* to transfer the files
- Your preference may be scp to copy the files (not recommended by OpenSSH developers, 8.0 release notes (April 2019), "The scp protocol is outdated, inflexible and not readily fixed. We recommend the use of more modern protocols like sftp and rsync for file transfer instead.")
- You might use sftp or rsync.
- You could use the transfer files option in your VNC Viewer. RealVNC* used here
Once the model_downloader and model_optimizer directories are transferred to the Raspberry Pi, you are ready to begin.
The Model Downloader does not just download models to convert with the model optimizer, but also includes pre-trained models. The download location of these models is displayed upon downloading.
Use the Model Downloader (downloader.py) included with OpenVINO toolkit found in the model_downloader directory.
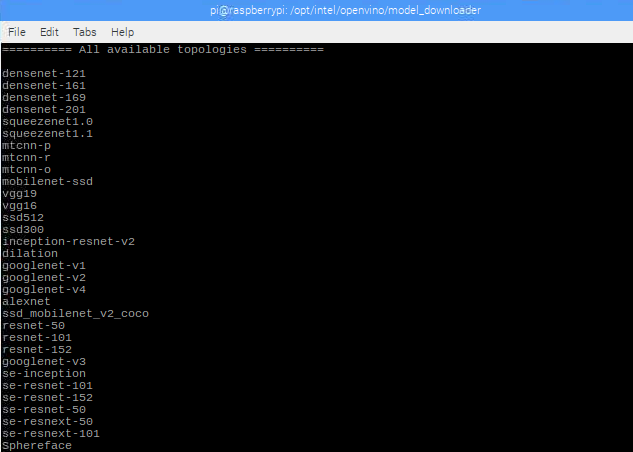
A list of all the models can be displayed by running:
Troubleshooting: If you receive a No module named 'yaml' error, try:
Troubleshooting: If you need pip try:
Results:
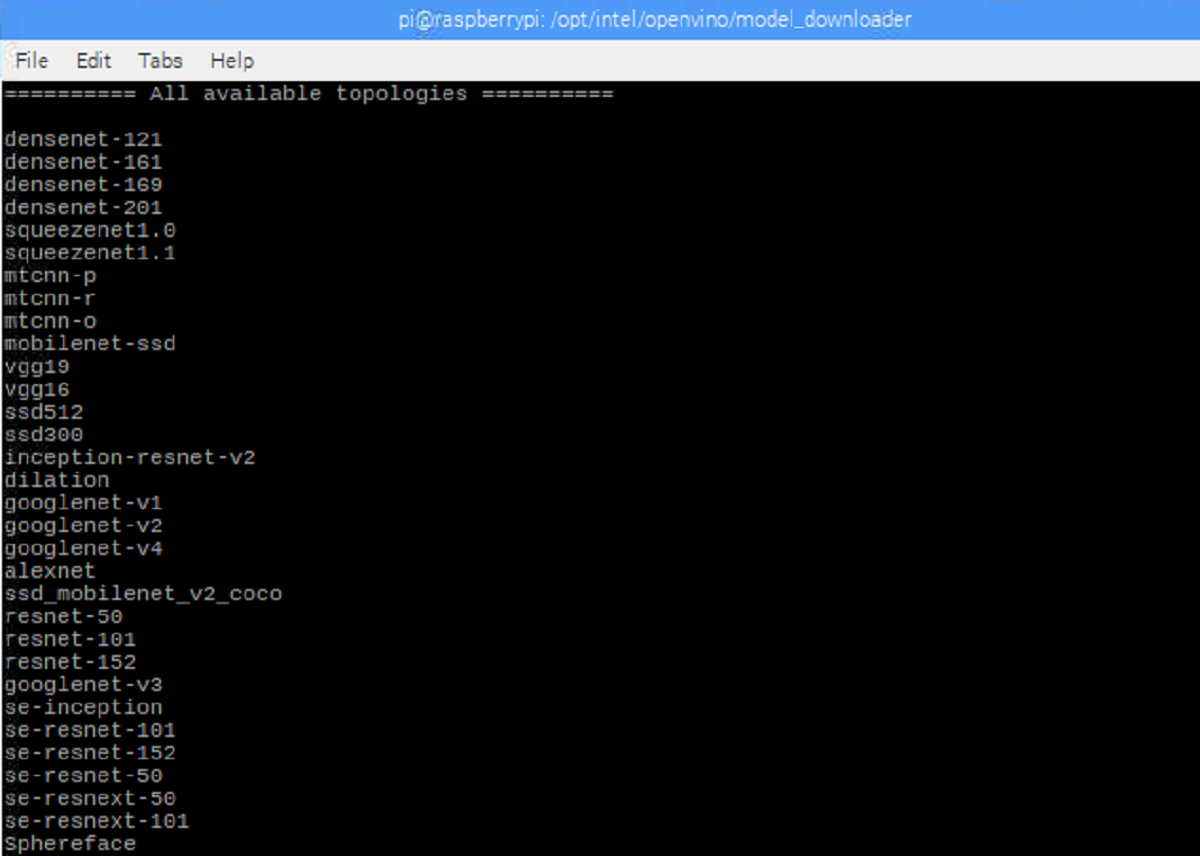
Details about the models are found in:
Fields include but are not limited to:
- name
- description
- model
- model_hash
- weights
- weights_hash
- model_optimizer_args
- framework
Downloader Example 1 - Squeezenet 1.1
Lists topologies details for squeezenet1.1.
# PUBLIC TOPOLOGIES # - name: "squeezenet1.1" description: "SqueezeNet v1.1 (https://github.com/DeepScale/SqueezeNet/tree/master/SqueezeNet_v1.1)" model: https://raw.githubusercontent.com/DeepScale/SqueezeNet/a47b6f13d30985279789d08053d37013d67d131b/SqueezeNet_v1.1/deploy.prototxt model_hash: d041bfb2ab4b32fda4ff6c6966684132f2924e329916aa5bfe9285c6b23e3d1c weights: https://github.com/DeepScale/SqueezeNet/raw/a47b6f13d30985279789d08053d37013d67d131b/SqueezeNet_v1.1/squeezenet_v1.1.caffemodel weights_hash: 72b912ace512e8621f8ff168a7d72af55910d3c7c9445af8dfbff4c2ee960142 output: "classification/squeezenet/1.1/caffe" old_dims: [10,3,227,227] new_dims: [1,3,227,227] model_optimizer_args: "--framework caffe --data_type FP32 --input_shape [1,3,227,227] --input data --mean_values data[104.0,117.0,123.0] --output prob --input_model --input_proto " framework: caffe license: https://github.com/DeepScale/SqueezeNet/blob/master/LICENSE
Run this command from the model_downloader directory:
You may be prompted to enter your password. Example:
[sudo] password for vino-r4:
Download begins.
###############|| Start downloading models ||############### ...100%, 9 KB, 18879 KB/s, 0 seconds passed ========= squeezenet1.1.prototxt ====>/opt/intel/openvino/model_downloader/classification/squeezenet/1.1/caffe/squeezenet1.1.prototxt
Downloads weights and location.
###############|| Start downloading weights ||############### ...100%, 4834 KB, 4061 KB/s, 1 seconds passed ========= squeezenet1.1.caffemodel ====> /opt/intel/openvino/model_downloader/classification/squeezenet/1.1/caffe/squeezenet1.1.caffemodel
Downloads topologies in tarballs and post processing.
###############|| Start downloading topologies in tarballs ||############### ###############|| Post processing ||############### ========= Changing input dimensions in squeezenet1.1.prototxt =========
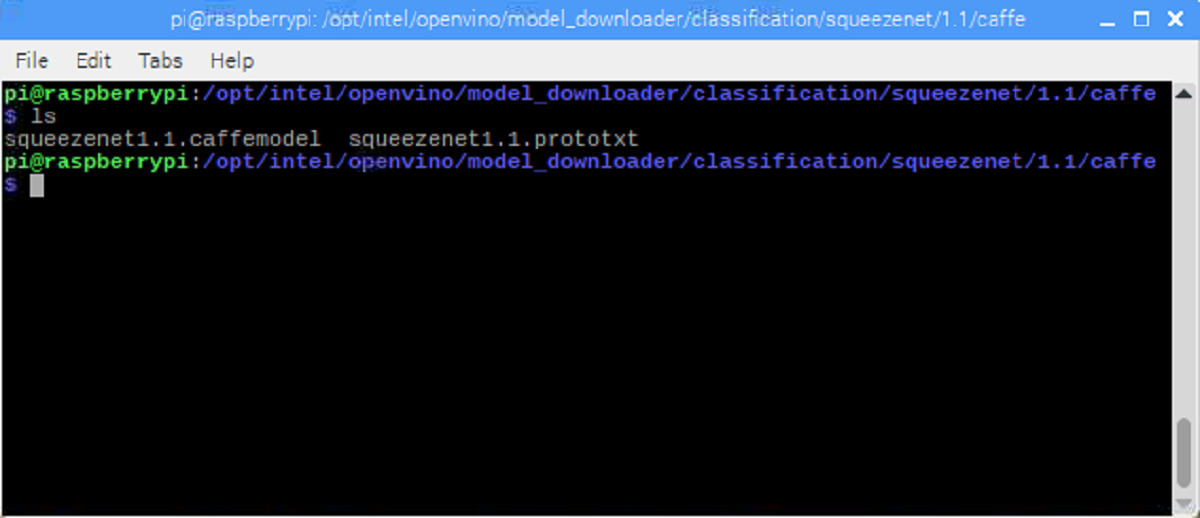
Model Optimizer - Convert to Floating Point 16 (FP16)
Use the Model Optimizer to produce an Intermediate Representation (IR) of the network, which can be read, loaded, and inferred with the Inference Engine. The Inference Engine offers a unified API across a number of supported Intel® platforms. The Intermediate Representation is a pair of files describing the model:
- .xml - Describes the network topology
- .bin - Contains the weights and biases binary data
These can be set to either Single Precision (FP32) by default or add the --datatype flag to indicate Half-Point Precision (FP16). Change to the model_optimizer directory on your system.
Optimizer Example 1 - Squeezenet 1.1
Install prerequisites:
install_prerequisites.sh is the main file, called by individual scripts.
- install_prerequisites.sh
- install_prerequisites_caffe.sh
- install_prerequisites_tf.sh
- install_prerequisites_mxnet.sh
- install_prerequisites_kaldi.sh
- install_prerequisites_onnx.sh
Use the install_prerequisites.sh for all of the following:
- caffe
- tf
- mxnet
- kaldi
- onnx
Edit install_prerequisites.sh. Open a terminal or editor to edit this file.
Before:
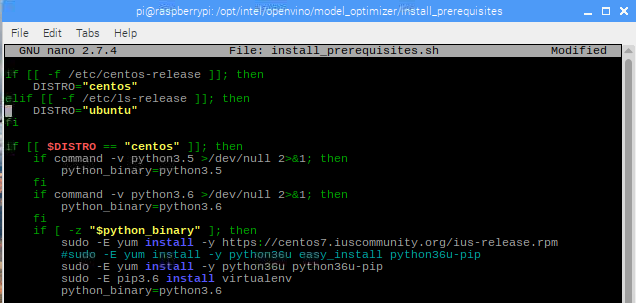
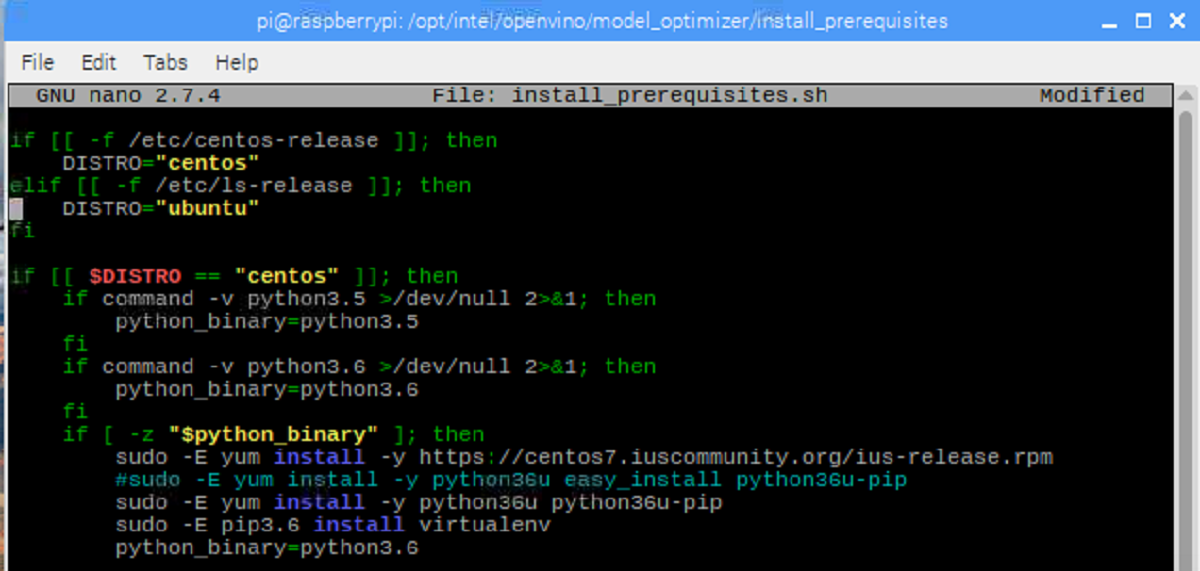
Line 53. Change lsb-release to os-release.
Line 54. Change ubuntu to raspbian.
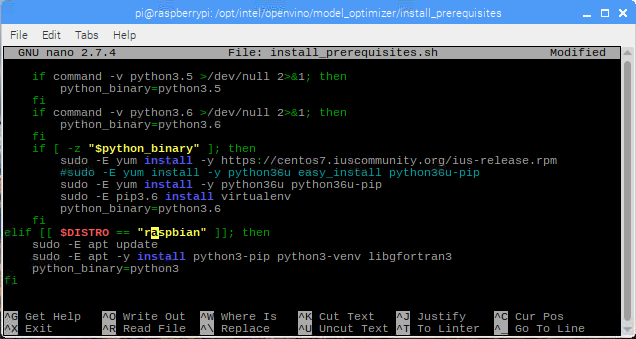
After:
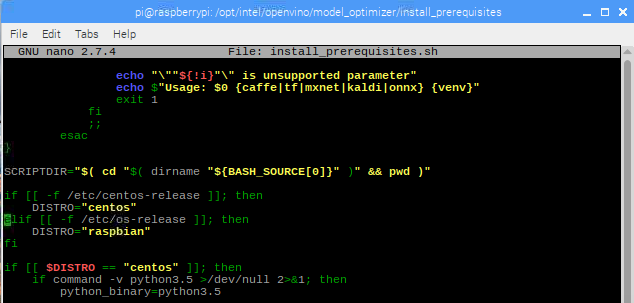
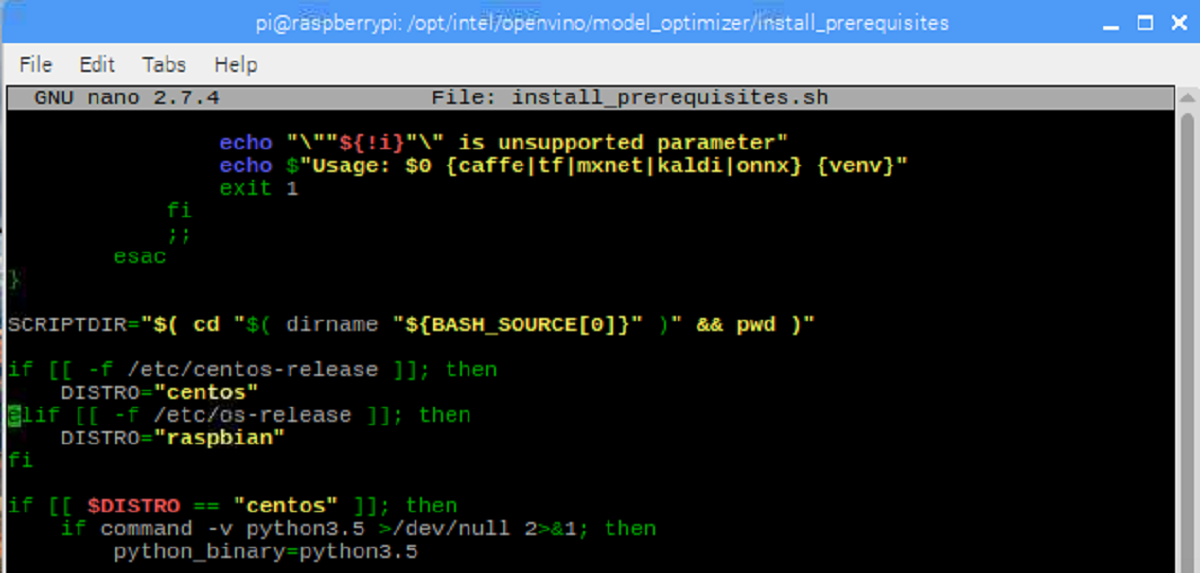
Line 71. Change ubuntu to raspbian.
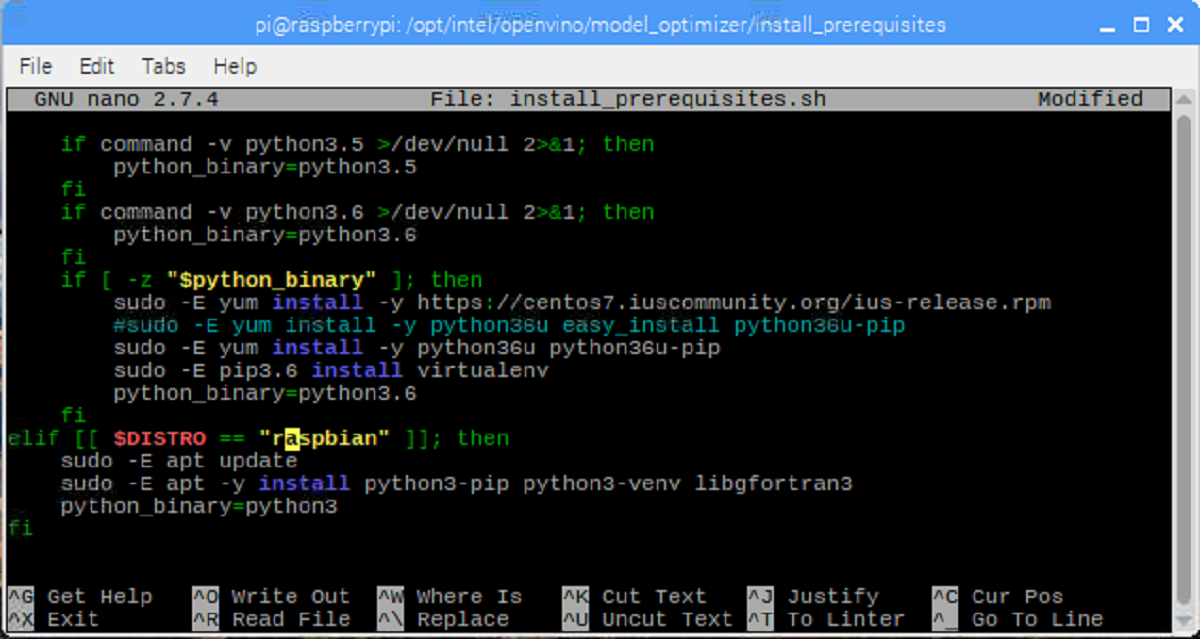
ctrl+x ctrl+c
Save when prompted.
Note: If using nano, use the command ctrl+w to search for the word ubuntu.
Run this command from install_prerequisites directory:
Now, you are ready to use the model optimizer. This is the command format:
Example command:
Results:
root@raspberrypi:/ python3 mo.py --input_model /opt/intel/openvino/model_downloader/classification/squeezenet/1.1/caffe/squeezenet1.1.caffemodel --data_type=FP16 Model Optimizer arguments: Common parameters: - Path to the Input Model: /opt/intel/openvino/model_downloader/classification/squeezenet/1.1/caffe/squeezenet1.1.caffemodel - Path for generated IR: /opt/intel/openvino/model_optimizer/. - IR output name: squeezenet1.1 - Log level: ERROR - Batch: Not specified, inherited from the model - Input layers: Not specified, inherited from the model - Output layers: Not specified, inherited from the model - Input shapes: Not specified, inherited from the model - Mean values: Not specified - Scale values: Not specified - Scale factor: Not specified - Precision of IR: FP16 - Enable fusing: True - Enable grouped convolutions fusing: True - Move mean values to preprocess section: False - Reverse input channels: False Caffe specific parameters: - Enable resnet optimization: True - Path to the Input prototxt: /opt/intel/openvino/model_downloader/classification/squeezenet/1.1/caffe/squeezenet1.1.prototxt - Path to CustomLayersMapping.xml: Default - Path to a mean file: Not specified - Offsets for a mean file: Not specified Model Optimizer version: 1.5.12.49d067a0 Please expect that Model Optimizer conversion might be slow. You are currently using Python protobuf library implementation. However you can use the C++ protobuf implementation that is supplied with the OpenVINO toolkitor build protobuf library from sources. Navigate to "install_prerequisites" folder and run: python -m easy_install protobuf-3.5.1-py($your_python_version)-win-amd64.egg set PROTOCOL_BUFFERS_PYTHON_IMPLEMENTATION=cpp For more information please refer to Model Optimizer FAQ (/deployment_tools/documentation/docs/MO_FAQ.html), question #80. [ SUCCESS ] Generated IR model. [ SUCCESS ] XML file: /opt/intel/openvino/model_optimizer/./squeezenet1.1.xml [ SUCCESS ] BIN file: /opt/intel/openvino/model_optimizer/./squeezenet1.1.bin [ SUCCESS ] Total execution time: 51.59 seconds. root@raspberrypi:/opt/intel/openvino/model_optimizer#
You can move the optimized models or not. Note where the models are when running the application.
Run an Application Using the Optimized Model and Intel® Neural Compute Stick 2 (Intel® NCS2)
Use the Benchmark App.
./armv7l/Release/benchmark_app -m /opt/intel/openvino/deployment_tools/inference_engine/samples/squeezenet1.1.xml -d MYRIAD -i /home/pi/Desktop/car.png
8 steps:
After running the app with the optimized model, 8 steps are completed with results for latency and throughput. Your results may vary.
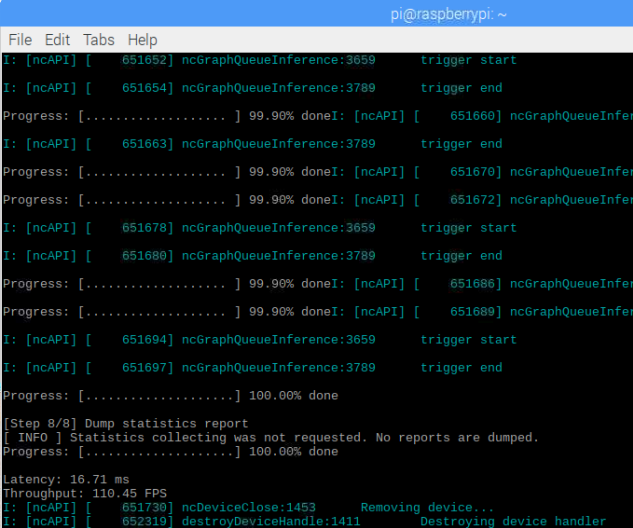
Troubleshooting Make sure to use the built applications in the build directory in /opt and not the inference_engine_samples_build directory, if you ran the build samples script.
Additional Example: Download Pre-Trained Models on Raspbian using the Model Downloader
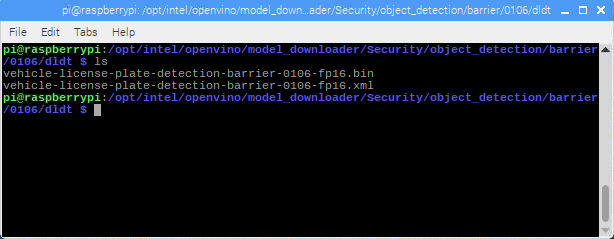
Downloader Example 2 - Vehicle License Plate Detection Barrier FP16
Run this command to download the FP16 pre-trained model for vehicle license plate detection:
###############|| Start downloading models ||############### ...100%, 93 KB, 1527 KB/s, 0 seconds passed ========= vehicle-license-plate-detection-barrier-0106-fp16.xml ====> /opt/intel/openvino/model_downloader/Security/object_detection/barrier/0106/dldt/vehicle-license-plate-detection-barrier-0106-fp16.xml
###############|| Start downloading weights ||############### ...100%, 1256 KB, 4470 KB/s, 0 seconds passed ========= vehicle-license-plate-detection-barrier-0106-fp16.bin ====> /opt/intel/openvino/model_downloader/Security/object_detection/barrier/0106/dldt/vehicle-license-plate-detection-barrier-0106-fp16.bin ###############|| Start downloading topologies in tarballs ||############### ###############|| Post processing ||###############
Download pre-trained models