Introduction
Persistent memory is byte-addressable. This property—which allows us to directly persist our data structures without serialization—is key to simplifying code complexity dealing with data persistence. For the application, this code simplification means fewer instructions to execute in both the read and write paths, improving overall performance.
In this article, we take a look at how the software architecture of the famous Apache Cassandra* distributed database was transformed in order to use persistent memory. With persistent memory, Cassandra does not need to split the data model into the performance-optimized part, which is stored in DRAM, versus the persistent part, which is stored on disk. Persistent memory allows Cassandra to have a single unified data model.
Transforming the Apache Cassandra* Architecture
First, let’s take a high-level look at the main components in the original (unmodified) version of the Cassandra architecture. For the sake of simplicity, only one instance of Cassandra—as well as a single client—is considered. Nevertheless, the case for multiple instances or clients does not change the fundamentals presented here since the internal logic of each instance remains the same.
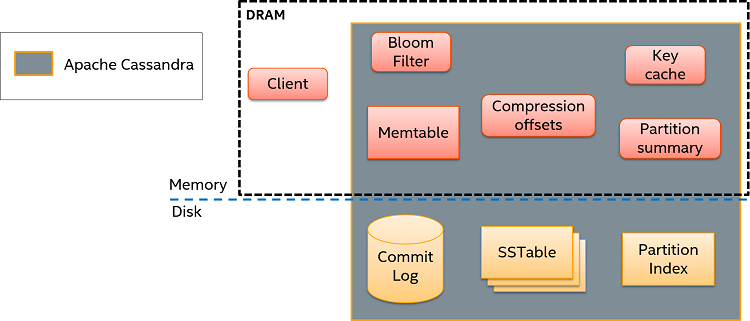
Figure 1. Main components of the Original Apache Cassandra* architecture.
Due to performance considerations in write-heavy workloads, writes in Cassandra are stored only on the Memtable data structure in memory, doing eventual flushing operations in order to synchronize with the sorted strings tables (SSTables) stored on disk. In order to avoid possible data losses due to node crashes, Cassandra also writes all operations to a log on disk (Commit Log), which can be used for recovery if needed. As it is possible to see, even if writing to an unstructured log is somewhat faster than directly updating the SStables on disk, writes to Cassandra still involve a write operation to disk.
In the case of reads, paths in the original Cassandra are even more complex. First, Cassandra uses the Bloom Filter to determine if the key we want to read is likely to be in this instance (false positives are possible, but not false negatives). Next, it looks in the key cache. If we are lucky and the key is there, Cassandra then accesses the Compression offsets in order to know where it should go and look for the requested data on the SSTable files. If the key is not in the key cache, however, Cassandra needs to perform an extra read to disk in order to find the key’s related information in the Partition Index.
Once the data is read from the corresponding SSTables, the Memtable is explored in case there are recent writes not yet flushed to disk. If that is the case, the data read from the Memtable is merged with the data read from the SSTable before returning it to the client. Both read and write paths are presented in Figure 2. For more information regarding the Cassandra architecture, as well as other details (like how replication works in Cassandra), you can read this introductory article.
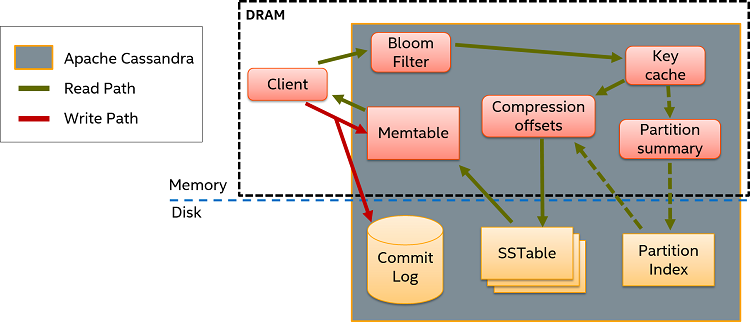
Figure 2. Read and write paths in the Apache Cassandra* architecture.
Figure 3 presents the persistent-memory version of Cassandra. In this case, only one data structure is used.
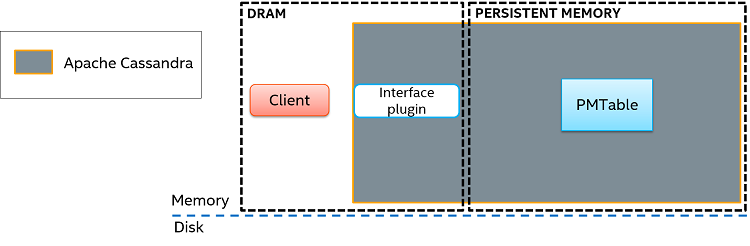
Figure 3. Main components of the persistent-memory version of the Apache Cassandra* architecture.
In the case of a write operation to the new Cassandra, only a single write to the PMTable data structure is needed. Since the structure resides on persistent memory already, no logging or any other write to disk is necessary. Likewise, a read operation involves only a single read to PMTable. If the requested keys are found in the table, the data is returned to the client.
This significant reduction in the number of components is what gives us shorter read and write code paths. In addition, there are other advantages gained by using persistent memory, especially regarding data serialization (as we will see next).
The Devil is in the Details
No need for serialization
One of the main challenges in designing applications, including Apache Cassandra, to handle data persistence is designing the data model. On the one hand, we want to have rich and powerful data structures adapted to the needs of the application by taking full advantage of what DRAM has to offer (byte addressability and speed). On the other hand, we want to provide persistence (so no data is lost). Due to the limitations of block storage (presented in the figures as “disk”) regarding data access granularity (block access) and speed (orders of magnitude slower than DRAM), serialization of data objects is required. This introduces a big design constraint since now we need to carefully design our data structures to avoid high overheads during serialization and deserialization phases.
The revolutionary aspect of persistent memory is that it is byte-addressable and fast (close to DRAM) without sacrificing persistence, all possible thanks to the Intel® 3D XPoint™ Memory Technology. By putting our data structures on persistent memory, we can achieve persistence without serialization. This, however, does not come at no cost. Due to the nature of persistent memory (more on that below), traditional volatile code does not work out of the box. Some coding effort is still necessary.
Need for code transformation
At the core of the NVM Programming Model (NPM) standard, developed by key players in the industry through the Storage and Networking Industry Association (SNIA), we have memory-mapped files. Using a special file system, processes running in user space can (after opening and mapping a file) access this mapped memory directly (through loads and stores) without involving the operating system. Programming directly against memory-mapped files, however, is not trivial. Data corruption can happen if CPU caches are not flushed before a sudden loss of power. To avoid that, programmers need to design their data structures in such a way that temporary torn-writes are allowed, and they need to make sure that the proper flushing instructions are issued at exactly the right time. Too much flushing is not good either because it impacts performance.
Fortunately, Intel has developed the Persistent Memory Developer Kit (PMDK), an open-source collection of libraries—implemented in C/C++—and tools that provide low-level primitives as well as useful high-level abstractions to help persistent memory programmers overcome these obstacles. Intel has also implemented Persistent Collections for Java* (PCJ), an API provided for persistent-memory programming in Java emphasizing persistent collections. For more information, you can read the following introductory article to PCJ.
The transformation of Cassandra, which is written in Java, is done using PCJ. Next, an example is presented showcasing the cell class, which is the basic object storing data for a particular row. To learn more, please refer to the source code.
A transformed cell
First, let’s look at the class BufferCell, used to buffer cell objects in volatile memory:
...
public class BufferCell extends AbstractCell
{
private static final long EMPTY_SIZE = ObjectSizes.measure(new BufferCell(ColumnMetadata.regularColumn("", "", "", ByteType.instance), 0L, 0, 0, ByteBufferUtil.EMPTY_BYTE_BUFFER, null));
private final long timestamp;
private final int ttl;
private final int localDeletionTime;
private final ByteBuffer value;
private final CellPath path;
...
public ByteBuffer value()
{
return value;
}
...
As you can see, this is just a regular Java class. The class BufferCell extends (inherits) from another class, called AbstractCell, and then defines its fields named Tiemstamp, ttl, localDeletionTime, value, and path. The data proper is stored in the field value, which is a ByteBuffer. To return the value, the method value() simply returns this field.
Let’s compare the above class to the class PersistentCell, which, in the new Cassandra, is used to store cell objects in persistent memory:
public final class PersistentCell extends PersistentCellBase implements MSimpleCell
{
private static final FinalObjectField<PersistentCellType> CELL_TYPE = new FinalObjectField<>();
private static final ByteField FLAGS = new ByteField();
private static final LongField TIMESTAMP = new LongField();
private static final IntField LOCAL_DELETION_TIME = new IntField();
private static final IntField TTL = new IntField();
private static final ObjectField<PersistentImmutableByteArray> VALUE = new ObjectField<>();
private static final ObjectField<PersistentImmutableByteArray> CELL_PATH = new ObjectField<>();
private static final ObjectField<PMDataTypes> DATA_TYPE = new ObjectField<>();
public static final ObjectType<PersistentCell> TYPE =
ObjectType.fromFields(PersistentCell.class,
CELL_TYPE,
FLAGS,
TIMESTAMP,
LOCAL_DELETION_TIME,
TTL,
VALUE,
CELL_PATH,
DATA_TYPE);
...
public byte[] getValue()
{
PersistentImmutableByteArray bArray = getObjectField(VALUE);
return (bArray != null) ? bArray.toArray() : null;
}
...
The first noticeable difference is in the declaration of fields. We go, for example, from int ttl in the volatile class to IntField TTL in the persistent one. The reason for this change is that, in this case, TTL is not a field but a meta field. Meta fields in PCJ serve only as a guidance to PersistentObject (all custom persistent classes need to have this class as an ancestor in their inheritance path), which is going to access the real fields as offsets in persistent memory. PersistentCell passes this information up to PersistentObject by constructing the special meta field TYPE, which is passed up the constructor chain by calling super(TYPE,…). This need for meta fields is just an artifact of persistent objects not being supported natively in Java.
You can see how meta fields work by looking at the getValue() method. Here, we do not have direct access to the field. Instead, we call the method getObjectField(VALUE), which will return a reference to a location in persistent memory where the field is stored. VALUE is used by PersistentObject to know where, in the layout of the object in persistent memory, the desired field is located.
How to Run
The patch to enable Cassandra for persistent memory is open source and available. To build Cassandra using this patch, you need PCJ, PMDK, and Java 8 or above. You will also need the ant compiler.
Currently there are two versions of the patch, and both require the use of the following version of Cassandra from GitHub*: 106691b2ff479582fa5b44a01f077d04ff39bf50 (June 5, 2017). You can get this version by doing this (inside your local cloned Cassandra repository):
$ git checkout 106691b2ff479582fa5b44a01f077d04ff39bf50To apply the patch, move the file to the root directory of the repository and run this:
$ git apply –index in-mem-cassandra-1.0.patchIn order to build Cassandra, you need to include the PCJ libraries in the project (JAR and so files). First, create a JAR file for the PCJ classes:
$ cd <PCJ_HOME>/target/classes
$ jar cvf persistent.jar lib/
Now copy persistent.jar and libPersistent.so to Cassandra’s library path:
$ cp <PCJ_HOME>/target/classes/persistent.jar <CASSANDRA_HOME>/lib/
$ mkdir <CASSANDRA_HOME>/lib/persistent-bin
$ cp <PCJ_HOME>/target/cppbuild/libPersistent.so <CASSANDRA_HOME>/lib/persistent-bin/
Finally, add the following line to the configuration file <CASSANDRA_HOME>/conf/cassandra-env.sh so Java knows where to find the native library file libPersistent.so (which is used as a bridge between PCJ and PMDK):
JVM_OPTS="$JVM_OPTS -Djava.library.path=$CASSANDRA_HOME/lib/persistent-bin"
After that, you can build Cassandra by simply running ant:
$ ant
. . .
BUILD SUCCESSFUL
Total time: ...
For the last step, we create a configuration file called config.properties for PCJ. This file needs to reside on the current working directory when launching Cassandra. The following example sets the heap’s path to /mnt/mem/persistent_heap and its size to 100 GB (assuming that a persistent memory device—real or emulated using RAM—is mounted at /mnt/mem):
path=/mnt/mem/persistent_heap
size=107374182400
Be aware that if the file config.properties does not exist, Cassandra will use as defaults /mnt/mem/persistent_heap and 2 GB. You can now start Cassandra normally. For more information, please refer to the readmes provided with the patches.
Summary
In this article, I described how the software architecture of the famous Apache Cassandra distributed database was transformed to use persistent memory. First, the high-level architectural changes were shown. After that, some details of this transformation were discussed—specifically, those related to serialization and code transformation. After that, I showed an example of code transformation by comparing the classes BufferCell (from the original Cassandra) and PersistentCell (from the new Cassandra). I finished the article showing how you can download and run this new persistent-memory-aware Cassandra.
About the Author
Eduardo Berrocal joined Intel as a Cloud Software Engineer in July 2017 after receiving his PhD in Computer Science from the Illinois Institute of Technology (IIT) in Chicago, Illinois. His doctoral research interests were focused on (but not limited to) data analytics and fault tolerance for high-performance computing. In the past he worked as a summer intern at Bell Labs (Nokia), as a research aide at Argonne National Laboratory, as a scientific programmer and web developer at the University of Chicago, and as an intern in the CESVIMA laboratory in Spain.
Resources
- Introduction to Apache Cassandra’s Architecture
- The Non-Volatile Memory (NVM) Programming Model (NPM)
- The Persistent Memory Development Kit (PMDK)
- Persistent Collections for Java
- Code sample: Introduction to Java API for Persistent Memory Programming
- Link to code to enable Cassandra for persistent memory
- Java (Oracle) download page
- Apache Ant
- Apache Cassandra GitHub repository
- How to emulate Persistent Memory