Introduction
This article describes the Data Plane Development Kit (DPDK) eventdev library. It shows you what functionality the eventdev library was designed for, and how your application can benefit from using the eventdev library.
The eventdev library allows a DPDK application to use event-driven methods to operate. Event driven means that the work to be done by the system is represented in separate units called events. Each event represents a single task or item which can be scheduled using the eventdev library. To make it simple to understand, imagine that an event represents a single network packet; this is a very common usage of event-driven programming in DPDK.
Similar to the DPDK ethdev or cryptodev libraries, the eventdev library code uses a model to allow different back end drivers to perform scheduling. These back end drivers (called Poll Mode Drivers or PMDs) perform the actual event scheduling work. A well-designed generic application can run using a variety of PMDs.
The event-driven model is used, as it often provides better load balancing for the work performed by the system. The following graphic shows the eventdev library in action:
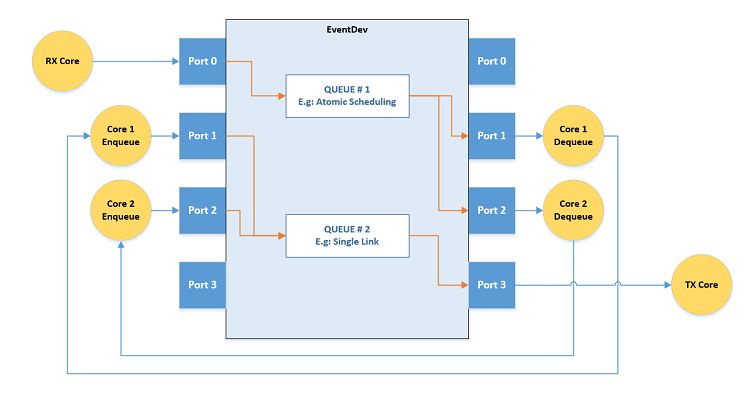
Partitioning of Workload
In order to design an application in an event-driven way, the processing workload must break down into multiple stages. Each stage should be a logical step in the overall task of processing the input to the output. The power in partitioning the workload is that each step can be performed by a different CPU core, allowing the events to be load-balanced over the available CPU cores, and using the full capacity of the system.
Each of the logical stages of processing are represented in the eventdev. These logical stages allow the DPDK eventdev library to perform scheduling of the events, performing load balancing after each stage. As a result, the workload being processed will scale to the number of CPU cores dedicated to the work; previously, any large workload could cause a single core to become the event processing bottleneck.
From a performance and cache-locality perspective, it may seem that the pipeline strategy that eventdev employs causes more overhead than gain; however, there is often a gain in predictability and performance when using all the CPUs in the system equally. Without the eventdev approach there is often an imbalance in work available to each CPU, resulting in the overall system performance becoming sub-optimal, as some CPUs have idle time, while others are over-subscribed.
Eventdev API Components
The eventdev itself is a DPDK library, and exposes a public API to the DPDK application. An application can choose whether it requires the functionality from the eventdev library, and if so it includes the API to use the eventdev infrastructure. It is not a problem if the application does not require eventdev. DPDK itself does not force the use of eventdev; it is made available to a user when it is a good fit for their use case.
The eventdev API itself breaks down into a number of components:
- Event Device
- Event Queue
- Event Port
- Port to Queue Links
Event Device
The event device represents one device capable of scheduling events. Similar to a single DPDK Ethernet device, each device is given its own numeric ID value to identify it.
Event Queue
A queue represents a logical stage of a processing pipeline. An application typically creates a small number of queues, with each queue representing one stage of work for the application to perform (see Partitioning of Workload above, for details).
Event Port
An event port is how any CPU lcore communicates with an event device. Each port is used by one CPU lcore, so an application with eight cores using the eventdev will have eight ports.
Port to Queue Links
In order for events from a queue to become available at a port they must be linked. When an application links a queue to a port, the application is asking the eventdev to schedule events from the queue to that particular port.
The Eventdev Sample App
DPDK libraries often come with a sample application—eventdev is no exception. The sample application for the eventdev library showcases what a fully functioning DPDK application looks like if it is built around the pipeline processing model.
The eventdev sample application as shown in the rest of this article is a generic application that uses the eventdev library and the software (SW) PMD in order to perform the scheduling. As such, the sample application is titled the eventdev_pipeline_sw_pmd sample app. The code for this sample application is contained in the DPDK source code, and is available from DPDK release 17.08-rc1 onwards.
In order to run the sample application, a PMD must be used to perform the event scheduling work. For this tutorial, we will use the Eventdev SW PMD, which is a software implementation of the scheduling work. The SW PMD can perform event scheduling on any CPU or platform supported by DPDK.
Basic Usage of the Sample App
The eventdev sample application is configurable, allowing the user to specify many attributes of what type of setup the application should emulate. In this case, type of setup means how many queues and ports the application should use (see the earlier section Eventdev API Components above, for details on event ports and queues).
The app takes a standard approach to designing an eventdev-based DPDK application. The sample application must be told which PMD to use, so part of the command line to start the sample application informs DPDK what eventdev PMD to load:
./build/eventdev_pipeline_sw_pmd --vdev event_sw0
In this sample app particular cores fulfill specific purposes, and the remaining cores function as worker cores. A list of the main roles of the cores in this application is as follows:
- RX Core: Receives packets from a network card
- Sched Core: Core performing the event scheduling
- TX Core: Transmits packets to the network card
- Worker Core: Cores available to the application to perform useful work
Each of the roles above must be assigned a specific core (or set of cores) to perform its function. If a particular role is the only task running on a core, that core exclusively performs that role. If multiple roles (for example, RX and Scheduler) are set for a specific core, it performs both functions. From a performance point of view, a dedicated core for scheduling is desired. If the application does not have at least one core specified for each role, the application will fail to start, with a message similar this one:
Core part of pipeline was not assigned any cores. This will stall the pipeline, please check core masks (use -h for details on setting core masks):
rx: 0
tx: 0
sched: 0
workers: 0
EAL: Error - exiting with code: -1
Cause: Fix core mask
To assign a set of cores to a specific role, an argument can be provided to the sample application. The arguments to the sample app are core masks, and each role has its own core mask.
-r 0x1 # set RX role coremask to only lcore 1
-t 0x2 # set TX role coremask to only lcore 2
-e 0x4 # set Scheduler coremask to only lcore 3
-w 0xf0 # set worker cores to lcore 5,6,7,8
Finally, a fully working command line to run the eventdev sample app is:
./build/eventdev_pipeline_sw_pmd --vdev event_sw0 --
-r 0x1 -t 0x2 -e 0x4 -w 0xf0
Expected output is as follows:
EAL: Detected XX cores:
EAL: ... various EAL messages
Config:
ports: 4
workers: 4
packets: 33554432
Queue-prio: 0
qid0 type: atomic
Cores available: XX
Cores used: 7
Eventdev 0: event_sw
Stages:
Stage 0, Type Atomic Priority = 128
Advanced Usage of the Sample App
The sample application allows configuration to emulate different pipelines. The configuration is performed using command-line arguments when launching the application as there is no interactive prompt. The usage of the command-line arguments is as follows:
Usage: eventdev_demo [options]
Options:
-n, --packets=N Send N packets (default ~32M), 0 implies no limit
-f, --atomic-flows=N Use N random flows from 1 to N (default 16)
-s, --num_stages=N Use N atomic stages (default 1)
-r, --rx-mask=core mask Run NIC rx on CPUs in core mask
-w, --worker-mask=core mask Run worker on CPUs in core mask
-t, --tx-mask=core mask Run NIC tx on CPUs in core mask
-e --sched-mask=core mask Run scheduler on CPUs in core mask
-c --cq-depth=N Worker dequeue ring depth (default 16)
-W --work-cycles=N Worker cycles (default 0)
-P --queue-priority Enable scheduler queue prioritization
-o, --ordered Use ordered scheduling
-p, --parallel Use parallel scheduling
-q, --quiet Minimize printed output
-D, --dump Print detailed statistics before exit
In order to design a particular pipeline, the following switches are often used:
--n0 Removes number of packets limit, the application continues forever
-s4 Set the number of stages in the pipeline, for example 4 stages
-W1000 Set the number of cycles each event will take to process on the CPU
-c32 Set the depth of the worker dequeue
The above switches allow running the sample application with a variety of configurations. Setting the application to run forever allows long-term performance analysis, gaining more accurate insight. Setting different pipeline lengths allows the sample app to emulate a specific application workload. By causing the worker CPUs to spend a given number of cycles on each event we cause artificial load on the system, resulting in more realistic system behavior. The worker queue depth is a knob that tunes performance and ideal load balancing. It should be set as high as possible so that it results in acceptable load-balanced traffic.
Use Ctrl+C to stop the application, and each worker’s statistics are printed:
Port Workload distribution:
worker 0 : 13.1 % (23450532 pkts)
worker 1 : 12.9 % (23065448 pkts)
worker 2 : 12.8 % (22817455 pkts)
worker 3 : 12.6 % (22427380 pkts)
worker 4 : 12.3 % (22009860 pkts)
worker 5 : 12.2 % (21761200 pkts)
worker 6 : 12.1 % (21594812 pkts)
worker 7 : 12.0 % (21469786 pkts)
Statistics of Eventdev PMDs
The statistics provided by the application are shown earlier in this article. If the behavior of the eventdev PMD is to be observed, there is a command-line argument that dumps all the statistics of the PMD:
-D Dump statistics of the application on quit
The output of the eventdev SW PMD is quite verbose, providing many details of the state of the device. Below are the output statistics when running the eventdev SW PMD with a two-stage atomic pipeline and four worker cores using the following command line:
./build/eventdev_pipeline_sw_pmd --vdev event_sw0 -- \
-r 0x1 -t 0x2 -e 0x4 -w 0xf0 -n0 -c32 -s2 -n100000000 -D
EventDev: ports 6, qids 3
rx 300002372
drop 0
tx 300001657
sched calls: 1574543
sched cq/qid call: 2356411
sched no IQ enq: 96017
sched no CQ enq: 9938
inflight 1152, credits: 2944
Port 0
rx 46196017 drop 0 tx 46196049 inflight 32
Max New: 4096 Avg cycles PP: 193 Credits: 32
Receive burst distribution:
0:97% 1-4:0.27% 5-8:0.26% 9-12:0.31% 13-16:1.67%
rx ring used: 0 free: 4096
cq ring used: 32 free: 0
Port 1
rx 44454196 drop 0 tx 44454228 inflight 32
Max New: 4096 Avg cycles PP: 192 Credits: 32
Receive burst distribution:
0:98% 1-4:0.27% 5-8:0.26% 9-12:0.30% 13-16:1.55%
rx ring used: 0 free: 4096
cq ring used: 32 free: 0
Port 2
rx 44049832 drop 0 tx 44049864 inflight 32
Max New: 4096 Avg cycles PP: 194 Credits: 32
Receive burst distribution:
0:98% 1-4:0.27% 5-8:0.26% 9-12:0.30% 13-16:1.53%
rx ring used: 0 free: 4096
cq ring used: 32 free: 0
Port 3
rx 65301351 drop 0 tx 65301495 inflight 144
Max New: 4096 Avg cycles PP: 192 Credits: 32
Receive burst distribution:
0:96% 1-4:0.24% 5-8:0.27% 9-12:0.30% 13-16:3.39%
rx ring used: 102 free: 3994
cq ring used: 32 free: 0
Port 4 (SingleCons)
rx 0 drop 0 tx 100000021 inflight 0
Max New: 4096 Avg cycles PP: 0 Credits: 37
Receive burst distribution:
0:81% 1-4:1.19% 5-8:0.63% 9-12:0.75% 13-16:16.87%
rx ring used: 0 free: 4096
cq ring used: 16 free: 112
Port 5
rx 100000976 drop 0 tx 0 inflight 0
Max New: 1200 Avg cycles PP: 0 Credits: 16
Receive burst distribution:
0:-nan%
rx ring used: 0 free: 4096
cq ring used: 0 free: 8
Queue 0 (Atomic)
rx 100000976 drop 0 tx 100000976
Per Port Stats:
Port 0: Pkts: 25537160 Flows: 13
Port 1: Pkts: 24761228 Flows: 11
Port 2: Pkts: 24652123 Flows: 25
Port 3: Pkts: 25050465 Flows: 62
Port 4: Pkts: 0 Flows: 0
Port 5: Pkts: 0 Flows: 0
-- iqs empty --
Queue 1 (Atomic)
rx 100000864 drop 0 tx 100000660
Per Port Stats:
Port 0: Pkts: 20658889 Flows: 21
Port 1: Pkts: 19693000 Flows: 26
Port 2: Pkts: 19397741 Flows: 10
Port 3: Pkts: 40251030 Flows: 65
Port 4: Pkts: 0 Flows: 0
Port 5: Pkts: 0 Flows: 0
iq 2: Used 204 Free 307
Queue 2 (Directed)
rx 100000532 drop 0 tx 100000021
Per Port Stats:
Port 0: Pkts: 0 Flows: 0
Port 1: Pkts: 0 Flows: 0
Port 2: Pkts: 0 Flows: 0
Port 3: Pkts: 0 Flows: 0
Port 4: Pkts: 0 Flows: 0
Port 5: Pkts: 0 Flows: 0
iq 2: Used 511 Free 0
As we can see, the output is quite verbose, and provides a lot of detail on the state of the PMD. There are three main sections of the output—the device, the ports, and the queues. The device section shows device statistics like total RX, total TX, and number of events currently in flight in the eventdev. The port section contains a number of statistics to inspect the state of each port. Of particular interest is the inflight count and receive burst distribution, as these numbers often indicate how efficiently the scheduler is performing. Finally, the queue section presents statistics on the state of each queue, detailing the number of events and flows that are currently being handled.
Conclusion
In this article we introduced the eventdev library. The concepts of the eventdev library (device, ports, and queues) were described, and we put that knowledge to use by designing and running the sample application. Advanced usages where shown; for example, how to configure a pipeline to emulate a specific application workload, and how to dump detailed statistics to the terminal for further investigation. I hope this article has been of interest to you, and if you have any questions please comment below.