In recent releases of the Intel® Distribution of OpenVINO™ Toolkit developers can optimize their applications using a suite of Python* calibration tools, namely convert_annotation.py, calibrate.py and accuracy_check.py . These tools are integrated into the Deep Learning Workbench Profiler (DL Workbench) to make it easier for the developer to run Deep Learning models through the toolkit's Model Optimizer, convert it to INT8, fine tune it, run inference and measure accuracy.
The DL Workbench enables developers to easily:
- Profile and visualize throughput, latency and accuracy of deep learning models on various Intel hardware architectures so they can identify and tune performance bottlenecks
- Boost performance through lowering the precision to INT8 or Winograd, especially on edge inference devices which may already be oversubscribed with heavy workloads
DL Workbench is available in the toolkit in Preview Mode, so that developers can try out its features and optimize some of the supported models. We hope you'll start using DL Workbench and provide feedback regarding needed features and improvements. Currently, DL Workbench runs on OpenVINO™ toolkit's Linux* version. In a future release Windows docker* containers will be made available. In fact there are several installation options including from Dockerfile* and also Docker* Hub.
To get started on Linux, all you have to do is
1) Download the latest Intel® Distribution of OpenVINO™ Toolkit Linux* version
2) Change directories into <openvino_install_dir>/deployment_tools/tools/workbench and run this command (after setting proxy environment variables):
./run_openvino_workbench.sh -PACKAGE_PATH <path_to_openvino*.tgz>.
3) Point a web browser which runs on the Linux system to http://127.0.0.1:5665 and voila ! You got your DL Workbench profiler.
4) Use the Get Started button and then import your model from the Import from Model Zoo button.
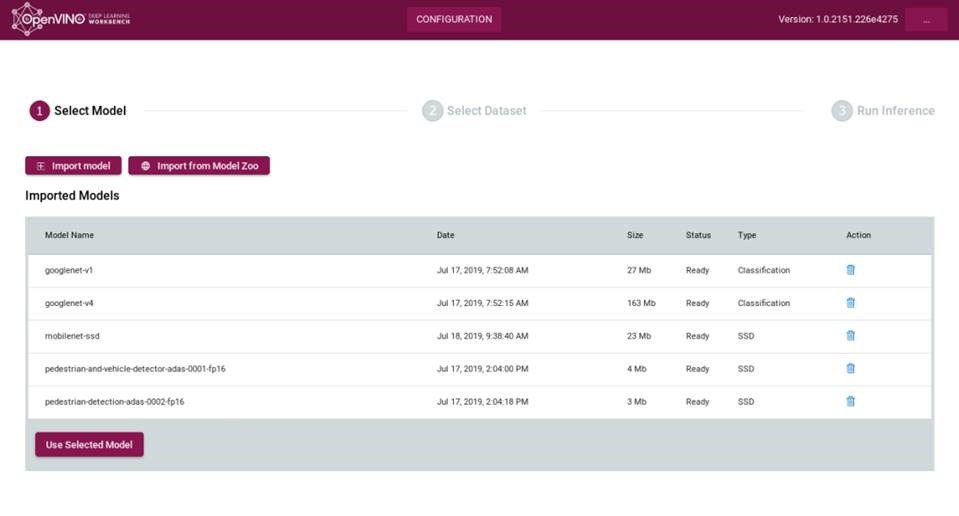 5) Next import a compatible data set in the correct format. Currently ImageNet* (for classification) and VOC* (for Object Identification) are supported
5) Next import a compatible data set in the correct format. Currently ImageNet* (for classification) and VOC* (for Object Identification) are supported
If you don't have a dataset handy, DL Workbench will allow you to auto-generate your own dataset in ImageNet* format.
Note that you could also use the Import Model button. In this case you must create an intermediate reference (IR) file for your specified model by manually running Model Optimizer, then archiving the generated *.xml and *.bin file into a "*.zip" or "*.tar.gz" and finally, uploading the archive into DL Workbench. The difference here is that by choosing Import from Model Zoo, Model Optimizer works "under the hood" and the user needn't worry about running Model Optimizer offline. Also when the user chooses Import from Model Zoo the recognition of whether the model is of Classification or Object Detection type is automatically determined by DL Workbench. When the Import Model option is chosen, the user must tell DL Workbench whether it is Classification, Object Detection or Generic. DL Workbench does recognize many Classification and Object Detection models out in the wild so once the IR file is uploaded it will reveal some default image pre-processing values for that model (these values are normally passed into Model Optimizer through various switches as described later). Finally, it should be noted that if a generic model is selected then there is no way for DL Workbench to suggest pre-processing values. Further INT8 and Winograd optimization cannot be executed for a generic model.
The following is an example of image pre-processing which DL Workbench might choose for a Classification Model.
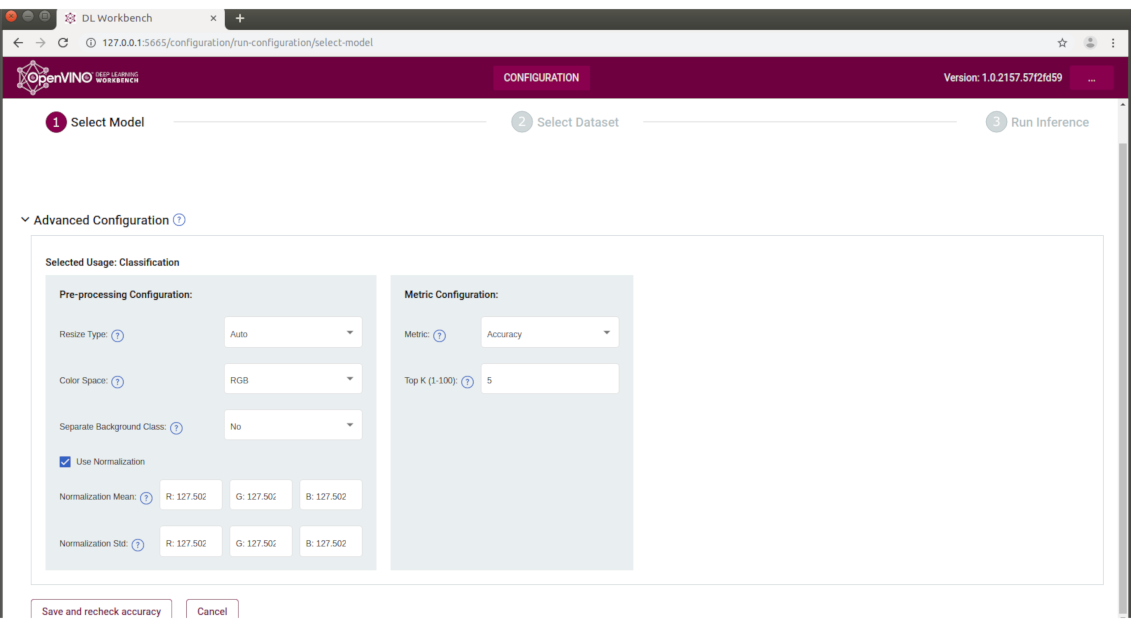
From this point on, you have several options. You can run inference on the chosen model and dataset on multiple devices. DL Workbench gives you the choice to run inference on CPU, GPU or VPU and to compare results. Once you select the target hardware for inference, you can tweak the number of parallel streams and batch size to get multiple inference instances. See the following example:

Notice that each of those "dots" above are inference instances, where latency(ms), throughput (fps), batch size, and number of parallel streams are captured. In the Max Latency field, you can find your sweet spot such that the blue line separates the graph into latency <= 400 and >=400 ms.
Below see The Model Performance Summary based on the Inference instance "dot" you selected above:
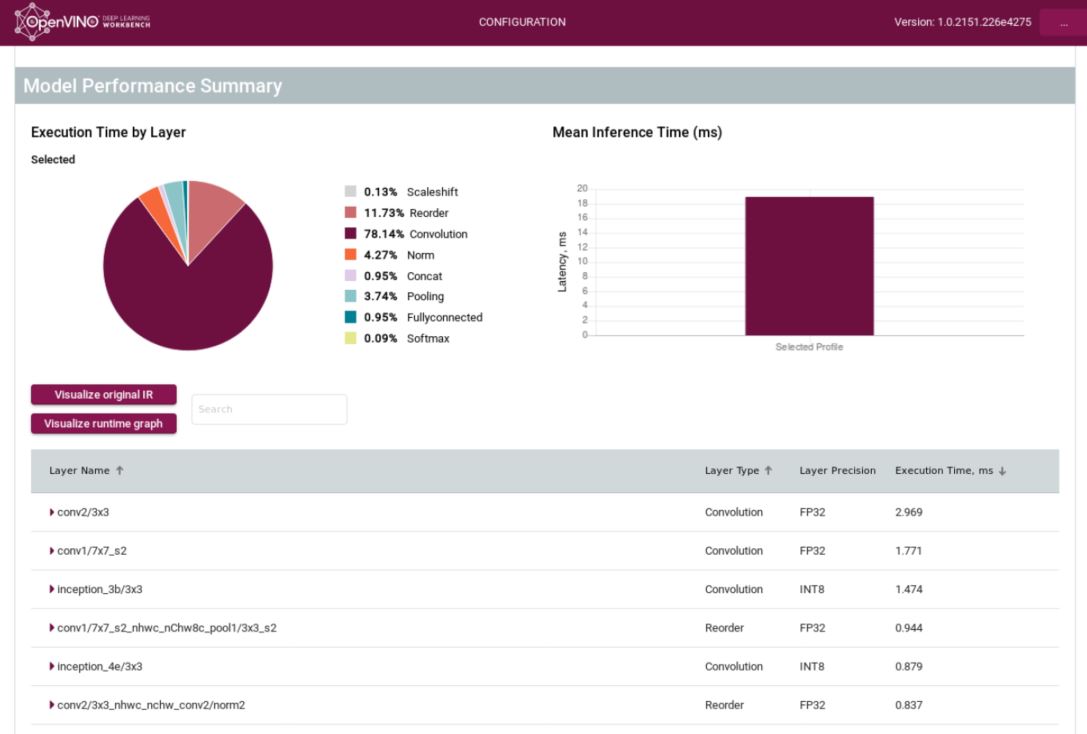
In the pie chart above, notice how the execution time per runtime layer is shown. Further down you will find the "Visualize Original IR" button which shows you the Model Optimizer generated IR in graphical format. During execution the Model Optimizer IR is transformed into a runtime graph, which can be visualized via the "Visualize runtime graph" button. If you are thirsty for low level details of layer transformations, click each of the layers below and you will find details per layer such as transformations which occurred, input shape, output shape, values of runtime layer attributes in the IR Catalog and so on.
Following is an example of a graph:

If you've ever used the open source netron* graph visualizer the graph delivered by DL Workbench should look familiar to you.
As aforementioned, DL Workbench can be used to run inference on CPU, GPU and VPU. The beauty of this is that you can compare the inference results between devices. The following is an example:
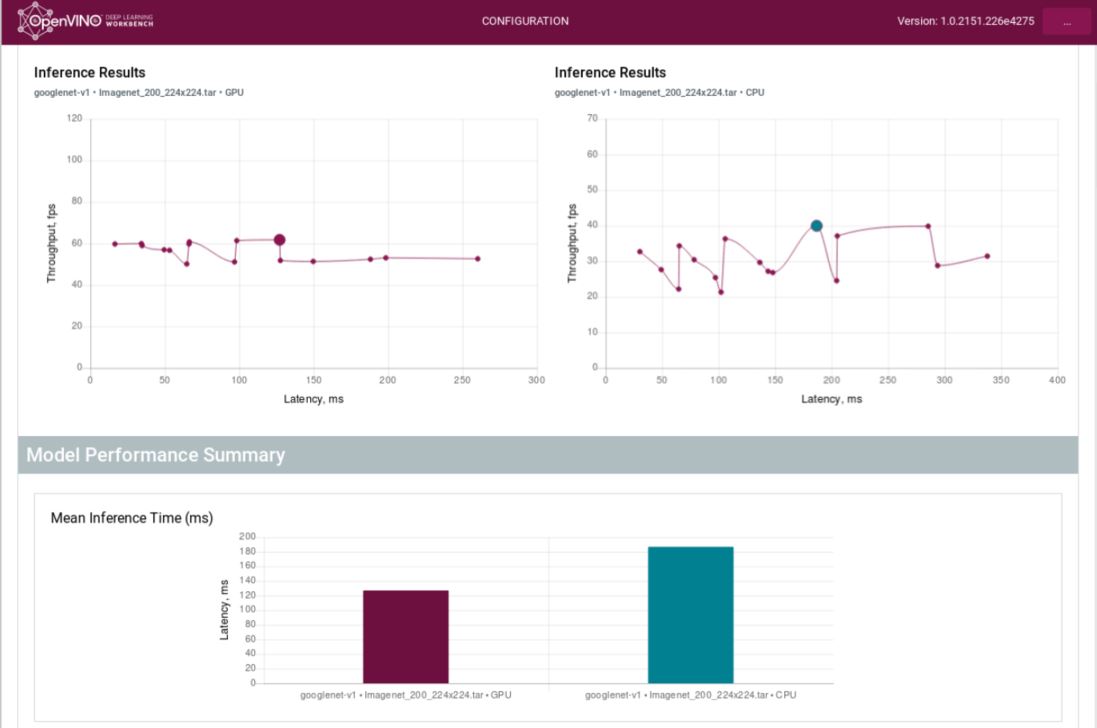
We hope that you're as excited about DL Workbench as we are ! Customers are interested in not only FP32 and FP16 models but they wish to visualize similar data for an INT8 or Winograd Optimized model. If you can get acceptable accuracy using a lower precision model, it's a smart thing to do - you will get much better performance. It's pretty much the same steps as what is already discussed here except now you hit the INT8 or Wingrad radio buttons under the Optimize tab and re-run inference.
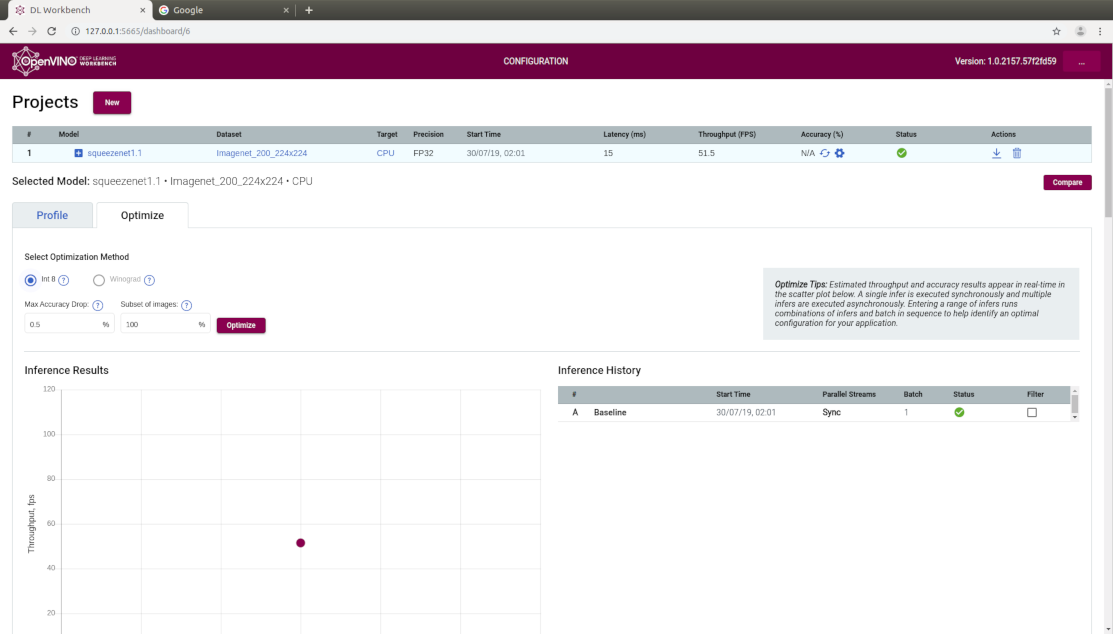
The Intel Software Tools engineering team understands that a matter of great importance to you (especially after optimization) is accuracy. Accuracy is also reported by DL Workbench for inference runs as shown below.

Keep in mind however, that accuracy depends heavily on the pre-processing of input images before the model was trained. Model Optimizer has several knobs which relate to pre-processing such as --scale, --scale_values, --input_shape, --reverse_input_channels, --mean_values and so on. Model Optimizer must know about pre-processing in order to properly generate IR. A certain subset of these Model Optimizer pre-processing knobs are available in DL Workbench but the development team is working on improvements for the next release.
As aforementioned, post your questions to The OpenVINO™ Intel Developer Zone forum and we will respond.