Introduction
This article discusses:
- OpenCL-C kernel ingestion and execution within in a SYCL* program
- Differences in the pure SYCL* analogous single source program
- Tips including: interoperability features, error handling, build recommendations, precision issues, and instrumentation
- References to development tools and documentation
Use this article if:
- You have kernels already written in OpenCL-C 1.2 or OpenCL-C 2.0… or kernels targeted to SPIR-V 1.2 (i.e. C++ for OpenCL in Clang). You would like to prepare applications for the future by understanding SYCL* ingestion.
- You want your code base to use multiple heterogeneous compute APIs. For example, you mix OpenCL* API and SYCL* programming and some other API. In this environment:
- You may feed memory through the OpenCL* API and other APIs in the same program already.
- You want to minimize boilerplate code by understanding options with SYCL* programming.
Prerequisites
- Intel® oneAPI Base Toolkit DPC++ Beta3 or newer installed (Beginning of 2020 calendar year public release)
- Intel® CPU: Same requirements as the Intel® oneAPI: DPC++ beta.
- Intel® Graphics Technology: Same requirements as the Intel® oneAPI: DPC++ beta.
The walkthrough source is intended to be standard enough to work on SYCL* 1.2.1 and OpenCL-C 1.2 interoperable implementations. A goal of the Intel® oneAPI initiative is to unlock portability for heterogeneous codes.
Test Platform Configuration:
- Intel® Core™ i7-6770HQ on Linux* OS (Ubuntu* OS 18.04.4)
- OpenCL 2.1 NEO 20.01.15264 (Intel® Graphics Compute Runtime for OpenCL™ Driver)
- OpenCL ICD Loader library 2.2.12
Windows* OS and other hardware platforms are possible. They are not tested for this tutorial.
Interoperability Types
We contend there are three types of OpenCL* and SYCL* programming interoperability:
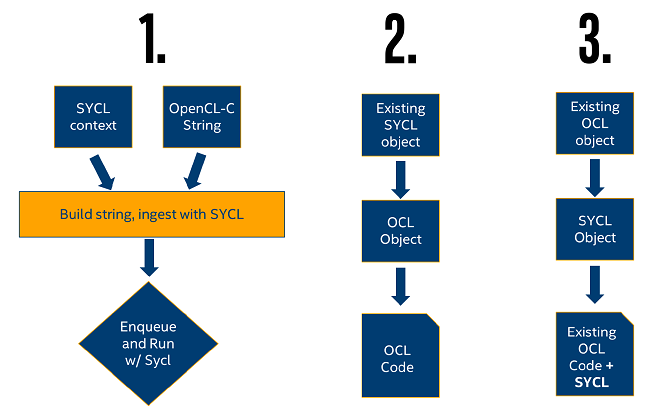
In this article, we discuss the first case. This case maps to a developer with a large investment in preexisting OpenCL-C kernels. It is a lean and powerful introduction to SYCL* runtime capabilities for developers of existing heterogeneous applications.
Key API features that enable cases 2. and 3. are presented near the end of this document.
Code Comparison
We present OpenCL-C kernel ingestion through a SYCL* program. For comparison we present an analogue SYCL-only implementation. The programs run on the same SYCL/OpenCL ‘gpu’ target device.
OpenCL-C kernel ingestion program
#include <CL/sycl.hpp>
#include <iostream>
#include <array>
using namespace cl::sycl;
int main()
{
const size_t szKernelData = 32;
std::array<float, szKernelData> kernelData;
kernelData.fill(-99.f);
range<1> r(szKernelData);
queue q{gpu_selector()};
program p(q.get_context());
p.build_with_source(R"CLC( kernel void sinf_test(global float* data) {
data[get_global_id(0)] = sin(get_global_id(0)*2*M_PI_F/get_global_size(0)) ;
} )CLC", "-cl-std=CL1.2");
{
buffer<float, 1> b(kernelData.data(), r);
q.submit([&](handler& cgh) {
auto b_accessor = b.get_access<access::mode::read_write>(cgh);
cgh.set_args(b_accessor);
cgh.parallel_for(r, p.get_kernel("sinf_test"));
});
}
for(auto& elem : kernelData)
std::cout << std::defaultfloat << elem << " " << std::hexfloat << elem << std::endl;
return 0;
}
Pure SYCL program
#include <CL/sycl.hpp>
#include <iostream>
#include <array>
using namespace cl::sycl;
int main()
{
const size_t szKernelData = 32;
const float M_PI_F = static_cast<const float>(M_PI);
std::array<float, szKernelData> kernelData;
kernelData.fill(-99.f);
range<1> r(szKernelData);
queue q{gpu_selector()};
program p(q.get_context());
{
buffer<float, 1> b(kernelData.data(), r);
q.submit([&](handler& cgh) {
auto b_accessor = b.get_access<access::mode::read_write>(cgh);
cgh.parallel_for(r, [=](nd_item<1> item) {
b_accessor[item.get_global_id(0)] = sin(item.get_global_id(0)*2*M_PI_F/item.get_global_range()[0]);
});
});
}
for(auto& elem : kernelData)
std::cout << std::defaultfloat << elem << " " << std::hexfloat << elem << std::endl;
return 0;
}
To build the OpenCL-C kernel ingestion example:
dpcpp -fsycl-unnamed-lambda ingest.cpp -std=c++17 -o ingest
To run:
./ingest
To build the pure sycl example:
dpcpp -fsycl-unnamed-lambda pure.cpp -std=c++17 -o pure
To run
./pure
Note: -fsycl-unnamed-labmda is part of default compiler behavior for the dpcpp driver as of Intel® oneAPI Base Kit beta04. Other SYCL compilers and runtimes may not have this default.
Reviewing the OpenCL-C kernel ingestion program
We instantiate an std::array of 32 floats. We fill it with an extrme value (-99.f) incase of an error with our program:
const size_t szKernelData = 32;
std::array<float, szKernelData> kernelData;
kernelData.fill(-99.f);
A cl::sycl::range of 1-dimension is created to size our buffer and the global number of workitems in our kernel launch. It is set to the size of the std::array.
range<1> r(szKernelData);
A cl::sycl::queue object is created and associated with the default gpu device afforded by the gpu_selector(). As configured on the tutorial system, this maps to:
- Platform: Intel(R) OpenCL HD Graphics
- Device: Intel(R) Gen9 HD Graphics NEO
- Device Version: OpenCL 2.1 NEO
- Driver Version: 20.06.15619
queue q{gpu_selector()};
A cl::sycl::program is created with the same context used by our cl::sycl::queue.
program p(q.get_context());
We build the OpenCL-C kernel program. In this example, we use a raw string see the R” indication before the string as well as the CLC( and )CLC delimiters to capture the multiline raw string. The string represents the OpenCL-C kernel. The second parameter is an OpenCL-C kernel build option toggle list. In this case, the build parameter specifies that the OpenCL-C compiler should compile the kernel for the OpenCL-C 1.2 standard. The CL1.2 compilation mode is the default and it is not required, however it is shown here for completeness. -cl-std=CL2.0 can also be typical of building OpenCL-C kernel programs with current Intel® implementations.
p.build_with_source(R"CLC( kernel void sinf_test(global float* data) {
data[get_global_id(0)] = sin(get_global_id(0)*2*M_PI_F/get_global_size(0)) ;
} )CLC", "-cl-std=CL1.2");
Ingestion Options:
- The kernel and build options could be read from disk and ingested instead of hard coded. Such an approach can be typical when working with a pre-existing OpenCL-C source base.
- Alternatively, the kernel could be completely generated at runtime.
- The kernel could also be partially generated at runtime with the use of preprocessor macro definitions supplied with -D build options.
- Often referred to as “metaprogramming”: partial, at-runtime kernel generation is typical of many OpenCL projects.
The example kernel finds the sine values in a stride for every work-item. Each stride is 2 * pi / the total number of work-items:
kernel void sinf_test(global float* data) {
data[get_global_id(0)] = sin(get_global_id(0)*2*M_PI_F/get_global_size(0)) ;
}
With our kernel built, the program enters a new scope via open brace to assist with cl::sycl::buffer object creation and destruction. This buffer consists of single precision float data in 1 dimension. The key to this scope is that the cl::sycl::buffer<float, 1> object will be destructed at the closing brace. Consequentially, host visible memory is ensured to be available in the subsequent host program sections. Any memory store clean up calls or memory release calls like delete (C++) free (C) clRelease (OpenCL API) are clear to proceed after buffer object destruction.
{
buffer<float, 1> b(kernelData.data(), r);
...
}
Queue submission with pass by reference lambda function is defined. The lambda function has a typical SYCL command group handler (cl::sycl::handler object) passed for subsequently enqueued operations.
q.submit([&](handler& cgh) {
auto b_accessor = b.get_access<access::mode::read_write>(cgh);
cgh.set_args(b_accessor);
cgh.parallel_for(r, p.get_kernel("sinf_test"));
});
A SYCL accessor is created from our cl::sycl::buffer<float, 1> object with the cl::sycl::buffer<>::get_access member function. The accessor is bound to the first (and in this case only) argument of our OpenCL-C kernel function with the cl::sycl::handler::set_args function.
auto b_accessor = b.get_access<access::mode::read_write>(cgh);
cgh.set_args(b_accessor);
The kernel is scheduled for execution with the cl::sycl::handler::parallel_for function. The total work-item size (NDRange) is set via our cl::sycl::range<1> object with 32 work items. A kernel function is specified from cl::sycl::program::get_kernel function. Our kernel is picked by the function name used in our kernel definition.
cgh.parallel_for(r, p.get_kernel("sinf_test"));
The kernel executes the sin function for each of the 32 work-items. Resulting in an output array that holds the sine of 32 input angles between 0 and 2pi radians.
The end of the program sees the output sine value printed from the array in both float and hexfloat format.
for(auto& elem : kernelData)
std::cout << std::defaultfloat << elem << " " << std::hexfloat << elem << std::endl;
Examining Differences
The pure SYCL example is mostly the same. There are three notable differences.
- This version uses the M_PI double precision pi macro from the host. It downcasts it to a single precision float. M_PI_F is an OpenCL-C 1.2 macro available to represent the value of pi. Note that M_PI_F and M_PI may not be portable for all platforms. Developers may wish to provide a value of pi directly to the kernel and host side program. For early standard adopters, std::numbers::pi from C++20 may also be useful to drive more consistency.
const float M_PI_F = static_cast<const float>(M_PI); - Binding the buffer to a kernel parameter with the cl::sycl::handler::set_args function is not required in the SYCL-only program. As a consequence, cgh.set_args(b_accessor); is removed.
- The kernel is not built via the cl::sycl::program::build_with_source function. This SYCL* version uses a kernel as defined directly within a cl::sycl::handler::parallel_for function. It is a lambda function kernel as a parameter. The sine operation is still performed. The output value is written to memory via the accessor.
cgh.parallel_for(r, [=](nd_item<1> item) { b_accessor[item.get_global_id(0)] = sin(item.get_global_id(0)*2*M_PI_F/item.get_global_range()[0]); });
Tips for new developers
Other interoperability
So far, the article has discussed SYCL-based OpenCL-C kernel ingestion as one type of interoperability. We suggest there are two more interoperability use cases typical for production applications.
SYCL objects can emit their underlying interoperable OpenCL API objects. Consider such functions when augmenting existing SYCL programs to also use the OpenCL API. Many SYCL objects have get() methods to derive the OpenCL object that is in use for the SYCL object:
- cl::sycl::device
- cl::sycl::event
- cl::sycl::kernel
- cl::sycl::program
- cl::sycl::queue
- cl::sycl::context
- cl::sycl::platform
SYCL objects can also be constructed from interoperable OpenCL API objects provided as constructor parameters. Consider these constructors when the SYCL runtime functionality is to be added to an existing OpenCL source base. All of the following objects can be used in SYCL constructors. If any of the following objects have been created from interoperable OpenCL API calls then corresponding SYCL objects can be created using SYCL constructors:
- cl_device_id
- cl_event
- cl_kernel
- cl_program
- cl_command_queue
- cl_context
- cl_platform_id
- cl_mem*
*As of SYCL 1.2.1 specification cl::sycl::image and cl::sycl::buffer objects have constructors that can be based on existing cl_mem objects for interoperable . cl::sycl::image and cl::sycl::buffer objects do not have get() methods to access underlying cl_mem objects.
Whenever using underlying OpenCL objects and OpenCL API calls directly in a SYCL program, do not forget to link the OpenCL ICD Loader library (-lOpenCL or OpenCL.lib) back into your program. For direct ingestion via SYCL in the intial examples of this article notice that neither OpenCL API calls nor OpenCL data types are required. Thus, linking the OpenCL ICD Loader library when using the 'dpcpp' compiler driver is not required.
Building interoperable programs
Please prefer these OpenCL headers and libraries acquired from these sources when building DPC++/SYCL and OpenCL interoperable programs:
- Direct from Khronos github portals
- Headers
- Build from the ICD Loader Library repository
- The Intel® oneAPI Base Toolkit DPC++/SYCL distribution.
- Available from system package managers. (ex: apt install ocl-icd-libopencl1).
Intel® SDK for OpenCL™ Applications or the included toolset within Intel® System Studio are not preferred.
Error Handling
cl::sycl::queue has a constructor that grants usage of an asynchronous exception handler like so:
auto async_exception_handler = [] (cl::sycl::exception_list exceptions) {
for (std::exception_ptr const &e : exceptions) {
try {
std::rethrow_exception(e);
}
catch (cl::sycl::exception const &e) {
std::cout << "Async Exception: " << e.what() << std::endl;
std::terminate();
}
}
};
queue q(gpu_selector(), async_exception_handler);
The handler iterates through the exceptions list to report of any asynchronous errors that occur during command queue execution.
Underlying OpenCL errors are reported through SYCL exception objects. SYCL exception object behavior encapsulates developer effort for managing errors using the cl_err datatypes commonly written to by OpenCL API calls. Exception handling is highly recommended for developers onboarding into SYCL development from OpenCL. Identifying the locations and types of errors becomes much more practical when using exception handlers.
For exception handling documentation see SYCL* 1.2.1 Specification function references to:
- void cl::sycl::queue::throw_asynchronous()
Also see the Base kit samples repository. In the repository vector-add and sepia filter examples show try-catch regions for synchronous expections. Look for try-catch and usage of the cl::sycl::queue::wait_and_throw function. wait_and_throw() function presents any unhandled asynchornous exceptions to be caught by the user defined handler.
With our example, q.wait_and_throw() can be used as well as a try-catch block. We can encapsulate our buffer definition and cl::sycl::queue::submit like so:
try {
buffer<float, 1> b(kernelData.data(), range<1>(szKernelData));
q.submit([&](handler& cgh) {
auto b_accessor = b.get_access<access::mode::read_write>(cgh);
cgh.parallel_for(range<1>(szKernelData), [=](nd_item<1> item) {
b_accessor[item.get_global_id(0)] = sin(item.get_global_id(0)*2*M_PI_F/item.get_global_range()[0]);
});
});
q.wait_and_throw();
} catch ( cl::sycl::exception const &e ) {
std::cerr << "Sync exception: " << e.what() << std::endl;
std::terminate();
}
Note: A quick example to test exception feedback is if the cl::sycl::handler object is accidentally omitted as a parameter. Try removing 'cgh' from b.get_access<access::mode::read_write>(cgh) within our cl::sycl::queue::submit(…) region. Upon recompiling and rerunning the application, observe the exception.
Specific error reporting strings for both compile time and runtime errors are under review as part of the DPC++ beta. Refer to OpenCL API errors as need and defined within the CL/cl.h header from Khronos.
Precision and result validation
Different platforms may give differing results for the same floating-point operations. Changing the gpu_selector() to a cpu_selector in the included training sample targets different hardware and may exhibit such differences.
Applications that are particularly sensitive to precision issues should review the OpenCL and SYCL specification’s precision guidance. Search documentation for ULP (unit last place) to find error allowed by the specifications.
Applications may achieve more consistent behavior by using memory allocations aligned to the system page size, or to a larger power of two. Alignment may minimize any runtime or driver layer memory reorganization or repacking. Here are a few C++17 references for aligned memory allocators:
- void* operator new ( std::size_t count, std::align_val_t al)
- void* std::aligned_alloc( std::size_t alignment, std::size_t size )
In C here are some equivalents:
- void *aligned_alloc( size_t alignment, size_t size ); (C11)
- C options are available for the GNU* compiler
- _aligned_malloc available under Microsoft Visual Studio*
In reduction type algorithms or for implementations that pack floating-point data into wide vectors, it’s possible reordering of floating-point operands can occur. Reordering may give different results run to run for the same application on the same platform. Consider:
- Elimination of any compile time toggles that may relax compute constraints. Opting for usage of more strict compile time toggles.
- This can apply to the host application and the kernel program independently. Common build options are documented for building kernels with the clBuildProgram function (1.2, 2.0, 2.1). -cl-fast-relaxed-math as a kernel build toggle is one such toggle for consideration for a performance trade off.
- Enforcing ordering of operations with similar exponent floating point values together before operating on dependent data with very different exponents. This approach may prove challenging or impractical in some applications.
- Integer arithmetic: is it suitable for the program purpose?
- Of course, extended double precision usage in place of single precision may mitigate some error propagation or variance effects depending on the algorithm. However, larger data type operands typically come with a performance trade off.
To assist in a comparison, our application prints the hexfloat formatting of our computed value. This allows easy review and comparison of the sign, mantissa, and exponent acquired from multiple platforms. Formatted printing of float objects directly may print the same output for different floating point values. Check values with logical comparison and/or the hexfloat representation when conducting error analysis.
Debug and Performance Instrumentation
Intercept Layer for Debugging and Analyzing OpenCL™ Applications (clIntercept) allows developers to observe OpenCL runtime behavior for OpenCL applications, by corollary this can include SYCL applications.
- It can intercept and modify OpenCL calls for debugging and performance analysis.
- clIntercept has a large library of simple environment variable controls to emit meta information about OpenCL programs.
- Many users opt to use clIntercept instead of invest in manually instrumenting their own programs.
Brute force debug
As a fall back, many developers use the printf(...) function to debug within OpenCL-C kernels. There is stream object for SYCL that can provide similar behavior. Remember, eliminate such unneeded streams from production programs as the performance consequence for stream operations from kernels is typically undesirable:
q.submit([&](cl::sycl::handler &h){
//In case stdout debug is needed see cl::sycl::stream object
cl::sycl::stream os(1024,256, h);
h.single_task([=] {
os << "Pure SYCL" << cl::sycl::endl;
});
});
References
- Intel® oneAPI: Data Parallel C++ and SYCL* Technology
- Intel® oneAPI Base Toolkit
- DPC++ Test samples from Github repository (kernel-and-program contains interoperability tests)
- DPC++/SYCL test sample for OpenCL kernel ingestion
- DPC++ Compatibility Tool release notes
- SYCL* 1.2.1 specification document
- Section: 4.8.2 describes OpenCL™ relationship
- SYCL* 1.2.1 reference card
- OpenCL* Technology
- OpenCL 1.2 C API reference
- OpenCL 2.1 C API reference (with OpenCL-C 2.0)
- OpenCL-C 2.0 specification
- OpenCL C++ API Host runtime wrapper manual
- OpenCL Headers
- OpenCL ICD Loader Library
- OpenCL Error Codes
- OpenCL™ runtimes for Intel® processors article
- Ioc64 as part of Intel® SDK for OpenCL™ Applications (Intel® System Studio 2020: OpenCL™ Tools)
- clIntercept
*OpenCL and the OpenCL logo are trademarks of Apple Inc. used by permission by Khronos.
*Other names and brands may be claimed as the property of others