
 When building a virtual platform, the focus tends to be on the nominal operation of the system (as they say in the automotive and aerospace industries). Making sure the virtual platform implements the functionality of the system correctly so that software can run reliably.
When building a virtual platform, the focus tends to be on the nominal operation of the system (as they say in the automotive and aerospace industries). Making sure the virtual platform implements the functionality of the system correctly so that software can run reliably. Once the nominal functionality is there, often the questions comes up about how to test abnormal, faulty, and otherwise non-nominal system behaviors. This is often called “fault injection”, even though the events injected sometimes are not precisely faults. Performing fault injection on hardware is complicated and expensive (even something as simple as pulling an Ethernet cable is tricky to automate), and often results in breaking the hardware being tested.
Fault injection in virtual platforms
Using a virtual platform makes it much easier to provide cheap, reliable, and repeatable fault injection for software testing, and it was been part of the Simics value proposition from the very early years. For example, here is an excerpt from a trade-show roll-up from 2003:
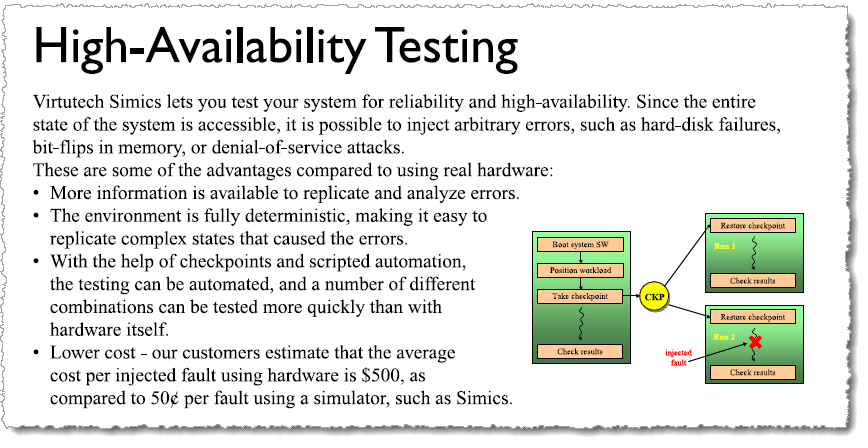
In general, fault injection in a virtual platform requires the behavior of the system model to be extended. Some types of faults can be introduced by simply changing the state of the model (register values, memory contents, etc.), but in the general case it is necessary to have specific fault injection support in the model. In addition to such designed-in and clearly intentional faults, sometimes we come across cases where fault injection was found by accident. In this blog post, I will share a few stories about fault injection from the early days of Simics.
Cache and memory ECC
A very early example of intentional fault injection support in a Simics model, was modeling errors from the cache and memory Error Correcting Code (ECC) units in a server system. The Simics model was extended to model the software-visible reporting of ECC errors being discovered, including special hardware registers and interrupts. This follows an important general principle of fault injection in virtual platforms – it is often better to model the error reporting mechanisms and inject specific error reports, compared to modeling the underlying mechanisms and inject problems in the hope that they will be detected and trigger errors.
In the case of a cache and memory, a model of the underlying mechanism would store the contents of each cache line or chunk of memory (ECC being applied to groups of 32 or 64 bytes back around 2000) along with their ECC bits (which are not visible to software). On each read, the ECC would be checked to see if the data was valid, correctable, or so broken it could not be corrected. In case an uncorrectable error was detected, an error would be reported. The hardware involved looks something like this:
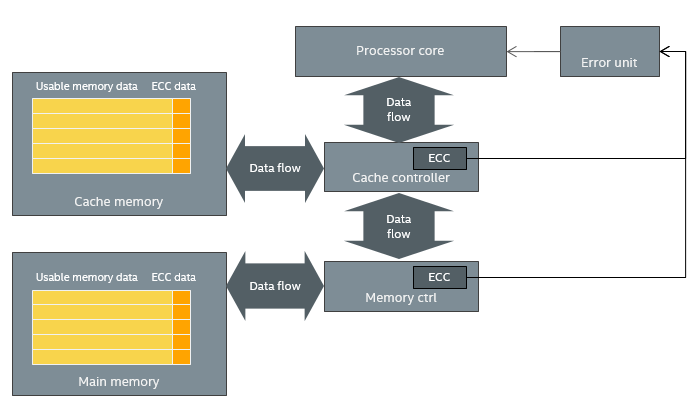
Causing an actual error and error report to the software requires a lot of work when using an accurate model of the ECC mechanisms. For cache errors, you would have to determine a cache line to modify, compute the data and ECC data modifications needed to cause the desired error, and then hope that the processor would read the cache line before replacing it with new data. For memory, you would have to guess at a location that software would touch soon, modify its data and ECC data, and then hope that the software would come read the data and trigger the error. This requires running with a fairly complex cache and memory model all the time, slowing the simulation by a factor of at least a 100x, while making fault injection rather tricky.
Instead, what was done was to add capabilities to the model to inject error reports into the system. Error reports were injected by assigning certain values to the error reporting registers, and triggering an interrupt for the processor to handle (the device is thus an active part in the process, not just storage for error reporting values). This makes it possible to very easily activate the error handling code directly for testing, which is typically what you want. The virtual platform looks like this, which is a simplification compared to the hardware:
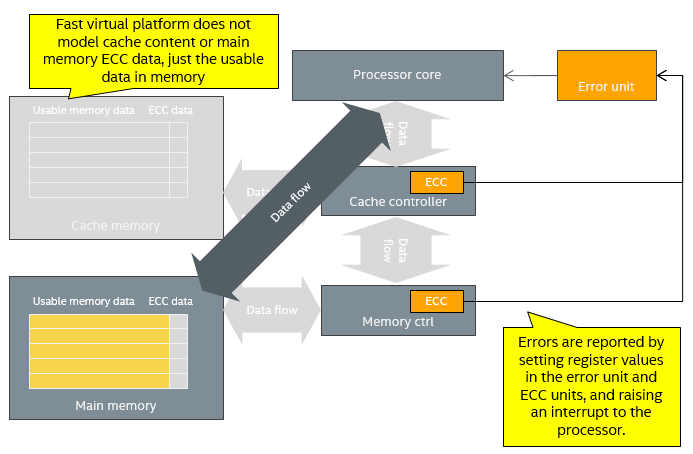
The virtual platform bypasses the controllers in the data flow in order to gain speed, and ignores the ECC. The ECC modules and error unit are modeled to the extent that they can report errors and interrupt the processor.
Of course, in case you do not have ECC on memory, it makes perfect sense to change the value of the data bits in order to test what happens to the software as a result of these changes. Classic memory test programs and the self-testing memory scrubbers for high-reliable systems typically look for memory that is damaged in this way – with bits permanently damaged and stuck at one or zero, or suffering “upsets” that change the value of bits behind the back of the software. However, most safety-critical and embedded systems today use ECC, and thus fault injection for memory tends to focus on ECC and other detection mechanisms rather than flipping bits in the simulated memory.
I must admit to having actually implemented memory error injection mechanisms for stuck bits and transient upsets in Simics, for demo purposes. Including some different memory test algorithms.
Inserting two cards at once
Another early example of unexpected event injection was discovered by accident. The Simics team was building a model of a system where it was possible to hot-plug boards into a backplane, as the system was running. This let us test the hot-plug management code, to validate that the system software correctly detected newly inserted boards and activated them.
As part of testing the model, a developer stopped the simulation, added two boards to the system, and then started the execution again. The software immediately crashed. The scenario was something like the below – and the question was: is this a model bug or a real bug in system?
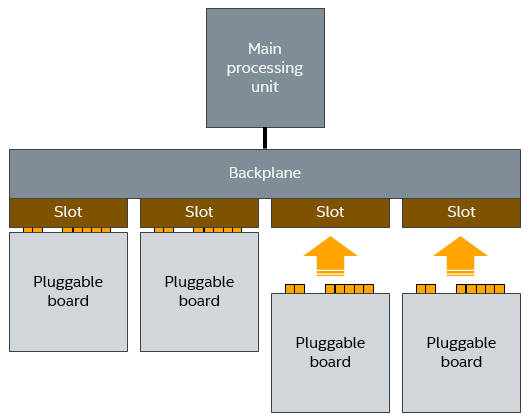
It was actually rather easy to find out what kind of error this was. The virtual platform modeled an existing system, and we actually had reference hardware available. Thus, an engineer took two physical boards, and pushed them in at the same time (one in each hand, counting down from three to get the time precise). Turned out you were not supposed to do that. The system crashed, with the exact same stack trace as seen on the simulator!
So, what we saw on Simics was also seen in the real world. It was a real bug in the software. The software had been written with the assumption that two boards would not be added in close succession. Makes sense that no one had thought about that – “who would do that?” Likely all previous testing had simply added one card at a time and checking that it worked correctly. What this case shows is the ability of a virtual platform and simulation in general to explore a larger set of possible system execution scenarios, as well as the need for developers to think through what can really happen. Not just what they hope will happen. I wrote about this phenomenon in a couple of earlier blog posts on the right mindset and the right toolset for testing.
In terms of fault injection, this is an example of varying the timing of events in the system to cover extreme cases that are difficult to hit in the lab (but which you can be sure will hit some user at some point). Being able to control the timing of events and injecting additional events is a key benefit of simulated hardware over real hardware (even if you build a robot to inject electrical events).
Clock drift? What clock drift?
Another example of rare timing issues being exposed in a virtual platform by accident is what happened when running a multiprocessor operating system on Simics. The operating system suddenly crashed with a divide-by-zero error – which had never been seen on hardware.
It turned out to be a question of an operating system algorithm dealing with clock drift between processors. In real hardware, you would never expect to see exactly the same time on two processor cores (especially not when they are on separate chips), and each processor’s clock would drift over time. Thus, the code took the difference in measured time from two processors and used it as the divisor in a division. On Simics, the measured difference turned out to be zero since in the simulator, time is tightly coordinated and there is no attempt made to model the physical drift of clock crystals.
Double the lock
When it comes to working with the timing in a virtual platform, one parameter that can be easily changed is the clock frequency of processor core. Varying this can also reveal problems in code, as it changes the timing relationship between processor operations and hardware events.
In one case, we were trying a range of clock frequencies in an embedded processor running a commercial real-time operating system (RTOS). We discovered that the RTOS boot froze when the clock frequency was set to 833 MHz. At the model’s default clock frequency of 800 MHz, it worked. After some experimentation, it was determined that the freeze happened in a narrow range of frequency settings, from 832.9 to 833.3 MHz. Interesting.
Since Simics is a non-intrusive debugger, it was rather easy to step through the code to determine what was going on. The problem was found in an interrupt service routine (ISR) for the serial port driver. The ISR disabled all interrupts (as such code usually does) and then tried to take a lock guarding a shared data structure. Interrupts would then be re-enabled after taking the lock. When the freeze happened, the lock was already taken when the ISR was entered, and with no interrupts enabled there was no way for it to be released since nothing else could run due to the disabled interrupts.
What did we learn from this? Getting locking right is hard, and locking issues in low-level driver code can truly crash a machine. Virtual platforms can reveal race conditions latent in code by trying different timings in a controlled manner. It is also clear that non-intrusive debug is incredibly valuable to debug tricky issues in low-level code.
Today
Today, fault injection is a common use case for virtual platforms. At Intel, we routinely add commands to Intel virtual platforms that inject faults in order to test RAS (Reliability, Availability, and Serviceability) features, using the same style as the ECC error injection discussed above. In addition, pushing the boundaries of the hardware configuration in simulation and supporting odd configurations help smoke out issues in software. From time to time, new accidental cases of fault injection pop up, often in the area of synchronization between multiple processors and hardware units.
Papers and resources
Here are some more papers and blog posts about fault injection on Simics:
- Some notes on what kind of faults you can inject in a simulator like Simics
- Systematic fault injection using Simics to find OS kernel races
- Using fault injection to validate safety-critical systems
- DrSeus – simulating single-event upsets in Simics
- Injecting faults on serial ports in Simics
- Injection faults in networks on Simics
- Investigating Uncore Error Resilience