Today, the Technology Innovation Institute (TII) in Abu Dhabi has launched Falcon 3, its most powerful family of AI models to date. With this announcement, Intel is sharing initial performance results for the Falcon 3 models and support on its AI product portfolio across Intel® Gaudi® AI accelerators, Intel® Xeon® Processors and AI PCs powered by Intel® Core™ Ultra processors and Intel® Arc™ graphics.
The Falcon 3 family of models with base and instruct versions, ranging from 1B to 10B, offer superior performance and fine-tuning capabilities, ranking among the top global models. Falcon 3 family of models achieves state of art results on reasoning, language understanding, instruction following, code, and mathematics tasks. Available in multiple languages and designed for easy integration, Falcon 3 will expand in January 2025 to include multimodal functionalities such as images, video, and audio modes.
Intel® Gaudi® Accelerates Enterprise AI with Falcon 3
The Intel® Gaudi® 2 and Gaudi® 3 AI accelerators both support the new Falcon 3 models. The Intel Gaudi 3 AI accelerators, which was recently introduced by Intel, deliver 4x AI compute for BF16, 2x AI compute for FP8, and 2x networking bandwidth for massive system scale-out compared to its predecessor – a significant leap in performance and productivity for AI training and inference. Intel Gaudi 3 AI accelerators are designed from the ground up for AI workloads and benefit from Tensor cores, and eight large Matrix Multiplication Engines compared to many small matrix multiplication units that a GPU has. This leads to reduced data transfers and greater energy efficiency. Open ecosystem software frameworks, like PyTorch*, Hugging Face*, inference serving such as vLLM*, and enterprise applications like OPEA, are optimized for Intel Gaudi and make it easy for AI systems deployment. Systems with Intel Gaudi accelerators are available via major OEM partners and cloud service providers like Intel® Tiber™ AI Cloud, Denvr Dataworks and IBM.
The following table illustrates the inference throughput performance of Gaudi 3 accelerators with PyTorch and Optimum Habana. The optimizations in both hardware and software make Intel Gaudi a great choice for running open LLMs such as Falcon 3 in a solution optimized for performance per dollar.
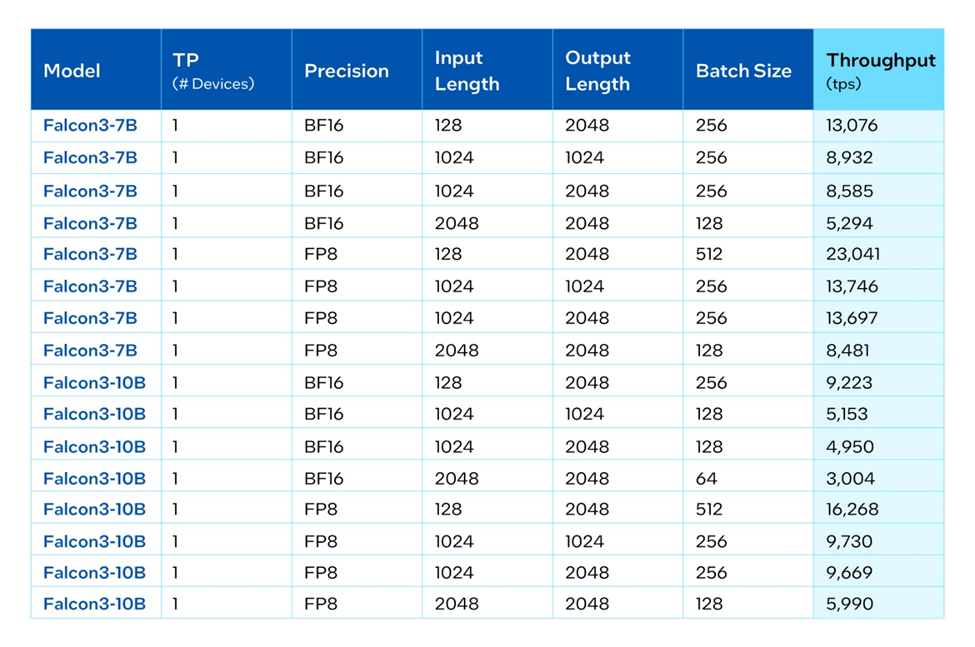
We are also excited to share that Intel’s contributions enabled support for the new Falcon 3 7B and 10B models in the Open Platform for Enterprise AI (OPEA). OPEA is an open-source project under the LF AI & Data Foundation, designed to enable the creation of robust, composable, and multi-vendor generative AI solutions. With this integration, users can easily build generative AI applications like ChatQnA using Falcon 3 models by leveraging the retrieval-augmented generation (RAG) technique and deploying them on the Intel Gaudi platform, ensuring high concurrency and efficient handling of user requests.
Here we show a demo of Falcon3-7B-instruct hosted on the Intel Gaudi platform in Denvr Cloud and application created in Hugging Face spaces. This demo is enabled by an Inference API powered by OPEA microservices. Customers can reach out to Denvr Dataworks to get access to the Inference API for preview.

Falcon 3 on Intel Xeon Processors
Intel Xeon processors are the ubiquitous backbone of general compute, offering easy access to powerful computing resources across the globe. Available today across all major cloud service providers, Intel Xeon processors have Intel® Advanced Matrix Extensions (Intel® AMX), an AI engine in every core that unlocks new levels of performance for AI performance. Intel has been leading contributor to PyTorch in CPU optimizations and has made AI frameworks like Hugging Face and vLLM optimized for Xeon.
We benchmarked Falcon 3 7B on both AWS instance M7i.48xl (based on 4th Gen Intel® Xeon® Scalable Processor) and on-prem server based on Intel® Xeon® 6 processors with Performance-cores (P-cores) with PyTorch and Intel® Extension for PyTorch*. Per benchmarking, running Falcon 3 7B with different input/output configurations can reach good throughput while keeping the next token latency less than 50ms for good user experience of interactive applications.
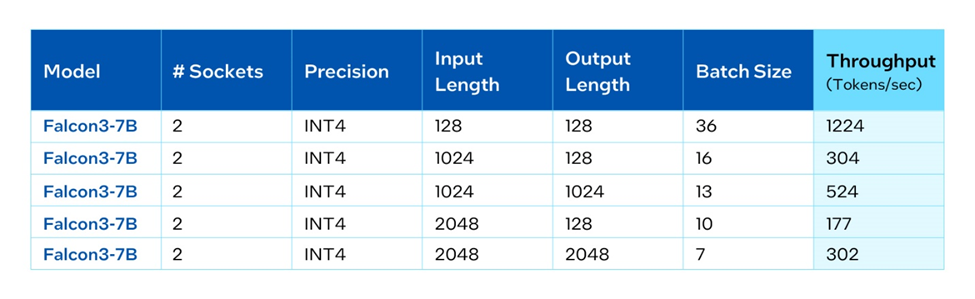
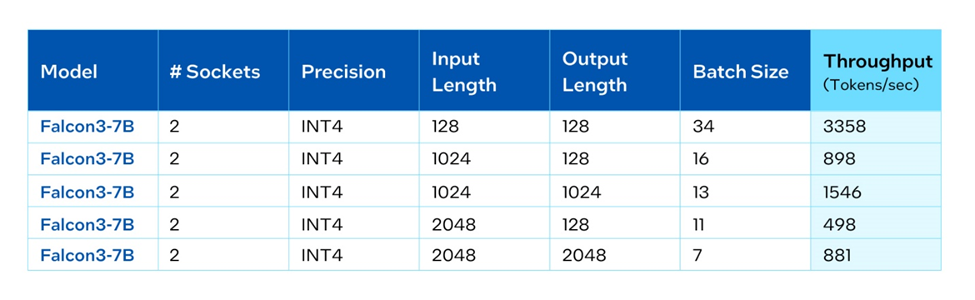
Falcon 3 on Intel AI PC Solutions
AI PCs equipped with Intel Core Ultra processors and built-in Intel Arc graphics deliver exceptional on-device AI inference to the client and edge. With specialized AI hardware such as NPU on the Intel Core Ultra platforms and Intel® Xe Matrix Extensions (XMX) acceleration on built-in Intel® Arc™ GPUs, achieving high performance inference and performing lightweight fine-tuning and application customization is easier than ever on AI PCs. This local, built-in compute capability also allows users to run the Falcon 3 models at the edge. Developers are enabled to use open-source frameworks such as PyTorch and the Intel Extension for PyTorch for research and development. For deploying models to production, the Intel® OpenVINO™ Toolkit is available for efficient model deployment and inference on AI PCs. Table 4 shows the inference throughput on Intel® Core™ Ultra 288V with built-in Intel® Arc™ 140V GPU with PyTorch and the Intel Extension for PyTorch.
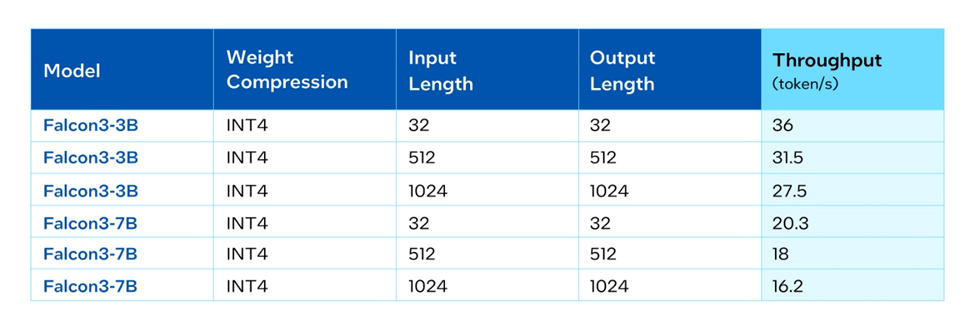
Summary
Today we announced support for Falcon 3 models on Intel Gaudi AI Accelerators, Intel Xeon processors and AI PCs equipped with Intel Core Ultra processors and built-in Intel Arc graphics, which powers both data center deployment and local inference use cases. Intel will continue to optimize the throughput and latency of these models. Get Started with Falcon models with Intel AI solutions on Intel Tiber AI Cloud.
Product and Performance Information
Intel Gaudi 3 Configurations:
Measured with 1 Intel Gaudi 3 AI Accelerator. 2 socket Intel®Xeon® Platinum 8480+ CPU @ 2.00GHz. 1TB System Memory. OS: Ubuntu 22.04. Intel Gaudi software suite 1.19.0 (pre-release). Optimum Habana https://github.com/alekseyfa/optimum-habana/commits/falcon/ Tested by Intel on December 11th 2024. Repository will be published soon.
Intel® Xeon® Configurations:
Measurement on Intel Xeon 6 Processor (formerly code-named: Granite Rapids) using: 2x Intel® Xeon® 6 6980P with P-cores, HT On, Turbo On, NUMA 6, Integrated Accelerators Available [used]: DLB [8], DSA [8], IAA[8], QAT[on CPU, 8], Total Memory 1536GB (24x64GB DDR5 8800 MT/s [8800 MT/s]), BIOS BHSDCRB1.IPC.3544.D02.2410010029, microcode 0x11000314, 1x Ethernet Controller I210 Gigabit Network Connection 1x Micron_7450_MTFDKBG960TFR 894.3G, CentOS Stream 9, 6.6.0-gnr.bkc.6.6.16.8.23.x86_64, Test by Intel on Dec 12th 2024. Run multiple instances (1 instance per NUMA node, 6 instances in total, BS varies per different input-output length) Repository here.
Measurement on AWS EC2 m7i.metal-48xl using: 2x Intel® Xeon® Platinum 8488C, HT On, Turbo On, NUMA 2, Integrated Accelerators Available [used]: DLB [8], DSA [8], IAA[8], QAT[on CPU, 8], Total Memory 512GB (16x32GB DDR5 4800 MT/s [4400 MT/s]), BIOS Amazon EC2 1.0, microcode 0x2b000603, 1x Elastic Network Adapter (ENA) 1x Amazon Elastic Block Store 256G, Ubuntu 24.04.1 LTS 6.8.0-1018-aws, (1 instance per socket, 2 instances in total, BS varies per different input-output length) Test by Intel on Dec 12th 2024. Repository here.
Demo with Intel Gaudi 2 AI Accelerator: Application hosted in HuggingFace Spaces with Denvr Inference API (preview) endpoint Inference API was hosted on Intel Gaudi 2 instances in Denvr cloud. Intel Gaudi 2 software suite used by Denvr cloud: 1.18; OS: Ubuntu 22.04.4.LTS; Kernel: v5.0.4-0.202; K8s server version: 1.29.5
Intel® Core™ Ultra Configurations:
Intel Core Ultra: Falcon3 3B and 7B instruct model measurements were completed on an Asus Zenbook S14 UX5406SA.303 laptop with Intel® Core™ Ultra 9 288V platform using 32GB LPDDR5x 8533Mhz total memory, Intel graphics driver 101.6319, IPEX 2.5.110, Windows* 11 Pro 24H2 version 26100.2605, Best Performance power mode, core isolation enabled, and Batch Size 1. Intel Arc graphics only available on select Intel Core Ultra (Series 2) powered systems; minimum processor power required. OEM enablement required. Check with OEM or retailer for system configuration. Test by Intel on 12/13/24. Repository here.
Notices & Disclaimers
Performance varies by use, configuration and other factors. Learn more on the Performance Index site. Performance results are based on testing as of dates shown in configurations and may not reflect all publicly available updates. See backup for configuration details. No product or component can be absolutely secure. Your costs and results may vary. Intel technologies may require enabled hardware, software or service activation.
Intel Corporation. Intel, the Intel logo, and other Intel marks are trademarks of Intel Corporation or its subsidiaries. Other names and brands may be claimed as the property of others.
AI disclaimer:
AI features may require software purchase, subscription or enablement by a software or platform provider, or may have specific configuration or compatibility requirements. Details at www.intel.com/AIPC. Results may vary.