Intel® Extension for TensorFlow*
We are excited to announce Intel® Extension for TensorFlow*, an open-source solution to run TensorFlow applications on Intel AI hardware. Intel® Extension for TensorFlow* is a high-performance deep learning extension implementing the TensorFlow* PluggableDevice interface. Through seamless integration with TensorFlow framework, it allows Intel XPU (GPU, CPU, etc.) devices readily accessible to TensorFlow developers. With the Intel Extension, developers can train and infer TensorFlow models on Intel AI hardware with zero code change.
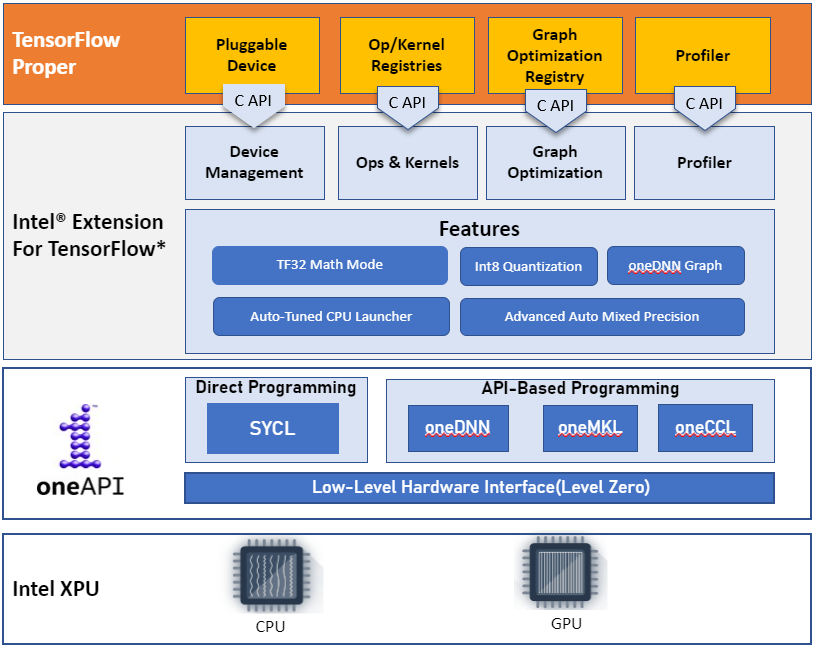
Intel® Extension for TensorFlow* is built on top of oneAPI software components. Most performance-critical graphs and operators are highly optimized by using Intel® oneAPI Deep Neural Network (oneDNN), an open-source, cross-platform performance library for Deep Learning applications. Other operators are implemented with SYCL*, one API’s core language for programming accelerators and multiprocessors. The plug-in also maintains a local Eigen math library which ports Eigen to the SYCL* language so that it can generate SYCL* kernel programs to implement device operators. Intel® Extension for TensorFlow implements all the TensorFlow GPU operators, which ensures good performance and sufficient model coverage for Intel GPUs.
Intel® Extension for TensorFlow* Features
Intel® Extension for TensorFlow* maintains the same user experience with TensorFlow public Python API, such as device management API (tf.config.list_physical_devices), model execution API (v1’s Session graph API and v2’s eager and graph API), Keras Mixed precision API, profiler API (tf.profiler.experimental.start ). Thus, you can run existing application code on Intel GPU without any changes. Currently, Intel® Extension for TensorFlow* supports both Intel CPU and Intel GPU on Linux* and WSL (Windows Subsystem for Linux*).
Intel® Extension for TensorFlow* provides good performance with the default configuration. It also offers several features through simple Python APIs or environment variables for advanced users to get additional performance:
- Advanced Auto Mixed Precision
Intel® Extension for TensorFlow* is fully compatible with Keras mixed precision API in TensorFlow. It also provides an advanced auto mixed precision feature. For example, you can just set two environment variables to get the performance benefit from low-precision data type FP16/BF16 without changing the application code.export ITEX_AUTO_MIXED_PRECISION=1 export ITEX_AUTO_MIXED_PRECISION_DATA_TYPE="BFLOAT16" # or "FLOAT16" - TF32 Math Mode
Intel® Iris® Xe GPU Matrix Engine in Ponte Vecchio Xe-HPC GPU natively supports the TF32 math mode. Intel® Extension for TensorFlow* enables TF32 math mode on Ponte Vecchio with one line:
export ITEX_FP32_MATH_MODE="TF32" - Int8 Quantization
Intel® Extension for TensorFlow* leverages Intel® Neural Compressor to provide a compatible TensorFlow INT8 quantization solution. You may reuse the existing TensorFlow INT8 models or write minimal lines of code to generate a new TensorFlow INT8 model as below:from neural_compressor.experimental import Quantization, common quantizer = Quantization() quantizer.model = fp32_model dataset = quantizer.dataset('dummy', shape=(1, 224, 224, 3)) quantizer.calib_dataloader = common.DataLoader(dataset) int8_model = quantizer.fit()
- Auto-Tuned CPU Launcher [Experimental]
Intel® Extension for TensorFlow* provides an auto-tuned CPU Launcher to help user to get better performance when running the TensorFlow applications on the CPU. Tensorflow application performance on CPU is highly influenced by various configurations, such as workload instance number, thread number per instance, thread affinity, memory allocator, NUMA memory placement policy, etc. There is no single configuration that is optimal for all topologies. The CPU launcher automates these configuration settings to simplify model deployment workflow. Users may use the following command:- Latency mode:
python -m intel_extension_for_tensorflow.python.launch --latency_mode infer_resnet50.py - Throughput mode:
python -m intel_extension_for_tensorflow.python.launch --throughput_mode infer_resnet50.py
- Latency mode:
- Aggressive Fusion through oneDNN Graph [Experimental]
Intel® Extension for TensorFlow* can offload performance-critical graph partitions to oneDNN library through oneDNN Graph API to get more aggressive graph optimizations such as Multi-Head Attention (MHA) fusion for Transformers. This feature is experimental and under active development. Currently, users can enable this feature with one environment variable.export ITEX_ONEDNN_GRAPH=1
Enabling Intel® Extension for TensorFlow*
This section uses an example to show how to enable TensorFlow applications on Intel GPU with Intel® Extension for TensorFlow*.
Installation
- Pre-Installation Requirements
- Install Intel GPU driver
• If running an Intel® Data Center GPU Flex Series, please find drivers here
• For other Intel GPUs (experimental), please find GPU driver installation guides here - Install Intel® oneAPI Base Toolkit :
• Install Intel® oneAPI Base Toolkit Packages 2022.3
- Install Intel GPU driver
- Setup environment variables
source /opt/intel/oneapi/setvars.sh - Install the latest Tensorflow and Intel® Extension for Tensorflow*
pip install tensorflow==2.10.0 pip install --upgrade intel-extension-for-tensorflow[gpu]
Check Physical Devices
You can use tf.config.list_physical_devices() to check all available physical devices:
import tensorflow as tf
tf.config.list_physical_devices()
Output
[PhysicalDevice(name='/physical_device:CPU:0', device_type='CPU'),
PhysicalDevice(name='/physical_device:XPU:0', device_type='XPU')]
You can see both CPU and XPU in a machine with Intel GPU installed. “XPU” is the device type registered by Intel® Extension for TensorFlow* to represent Intel GPU, as the counterpart of “GPU” in TensorFlow.
Using Intel GPU in TensorFlow Model
TensorFlow PluggableDevice takes priority over native devices, so if you don’t explicitly specify the device through tf.device(), it will run on Intel GPU by default without any code change. If explicitly specify device, only one line change is required:
import tensorflow as tf # TensorFlow registers PluggableDevices here.
tf.config.list_physical_devices() # XPU device is visible to TensorFlow.
[PhysicalDevice(name='/physical_device:CPU:0', device_type='CPU'), PhysicalDevice(name='/physical_device:XPU:0', device_type='XPU')]
#Section 1 Run implicitly
a = tf.random.normal(shape=[5], dtype=tf.float32) # Runs on XPU.
b = tf.nn.relu(a) # Runs on XPU .
#Section 2 Run with explicit device setting
with tf.device("/XPU:0"): # Users can also use 'with tf.device' syntax.
c = tf.nn.relu(a) # Runs on XPU.
with tf.device("/CPU:0"):
c = tf.nn.relu(a) # Runs on CPU.
#Section 3 Run with graph mode
@tf.function # Defining a tf.function
def run():
d = tf.random.uniform(shape=[100], dtype=tf.float32)
e = tf.nn.relu(d)
run() # PluggableDevices also work with tf.function and graph mode. Runs on XPU
Summary and Future Work
Intel® Extension for TensorFlow* is a high-performance deep learning extension plugin based on TensorFlow PluggableDevice interface to bring the first Intel GPU product Intel® Data Center GPU Flex Series 170 into TensorFlow ecosystem for AI workload acceleration.
For product quality CPU support, we recommend you to use TensorFlow and Intel® Optimization for TensorFlow*. Intel® Extension for TensorFlow* provides experimental CPU support.
We are continuously enhancing Intel® Extension for TensorFlow* on functionality and performance. With further product development, more Intel devices will be added to the XPU-supported list. We are also exploring more features, such as:
- Extending the support for OpenXLA and JAX.
- Adding an XPU heterogeneous execution runtime to efficiently schedule TensorFlow applications on both CPU and GPU to get better system hardware utilization
We welcome the community to evaluate the new AI solution and contributions to Intel® Extension for TensorFlow*.
Resource
- Intel® Extension for TensorFlow* GitHub*
- GitHub* Online Documentation & Tutorials
- Installation Guide
- Get Started
- Performance Tuning Guide
- System Requirements
Acknowledgment
We would like to thank Yiqiang Li, Zhoulong Jiang, Guizi Li, River Liu, Yang Sheng, Teng Lu, Cherry Zhang from the Intel® Extension for TensorFlow* development team, Haihao Shen, Feng Tian, Liang Lv from the Intel® Neural Compressor team, Ying Hu, Kai Wang, and Jianyu Zhang, etc. from AI support team for their contributions to Intel® Extension for TensorFlow*. We also offer special thanks to Sophie Chen, Eric Lin, and Jian Hui Li for their technical discussions and insights, and to collaborators from Google for their professional support and guidance. Finally, we would like to extend our gratitude to Wei Li, Andres Rodriguez, and Honesty Young for their great support.