
TensorFlow* has consistently demonstrated performance improvements for AI workloads on Intel® Xeon® processors generation over generation by using optimizations from Intel® oneAPI Deep Neural Network Library (oneDNN). Starting with TensorFlow 2.9, these optimizations are on by default.
The 4th generation Intel Xeon Scalable processor (formerly code named Sapphire Rapids) was launched in January 2023. It runs the Intel® Advanced Matrix Extension (Intel® AMX) that accelerates the performance of deep learning models for bfloat16 and 8-bit integer low precision data types. Intel AMX has two primary components: tiles and tiled matrix multiplication (TMUL). The tiles store large amounts of data in eight two-dimensional registers, one kilobyte in size each. TMUL is an accelerator engine attached to the tiles that contains instructions to compute larger matrices in a single operation.
Intel has recently released its 5th generation Intel Xeon Scalable processor (formerly code named Emerald Rapids), which has the same notable features as the 4th generation but with these additional improvements in the 5th generation version:
- The 5th generation Intel Xeon processor 8592+ provides a 14% core count increase over the 4th generation Intel Xeon processor 8480+, which provides better scalability by enhancing the parallelism of training and inference tasks of deep learning models.
- The 5th generation Intel Xeon processor 8592+ has a cache size that is 2.7x bigger than the 4th generation Intel Xeon processor 8480+ has, which leads to performance gains, especially for model inference when pretrained weights can fit in this larger cache.
- Additionally, the 5th generation Intel Xeon processor has the default mode of sub-NUMA cluster (SNC2) which splits the socket into two subdomains to improve memory latency.
- The 5th generation Intel Xeon processor supports 5600MT/s DDR5 memory speed while the 4th generation supports 4800 MT/s. This helps improve the performance of bandwidth-bound operations.
Training and inference models for both bfloat16 and 8-bit quantized models that are compressed by Intel® Neural Compressor can run on 5th generation Intel Xeon Scalable processors without any further code changes.
Performance Improvements
The following charts show the relative performance speedup of running popular deep learning vision and language models for inference and training use cases on 5th generation Intel Xeon Scalable processors. We used Intel Optimization for TensorFlow preview and the Intel® AI Reference Models to produce these results.

The previous chart shows speedup for selected inference models with bfloat16/float32 mixed precision. The data was collected for both real-time batch size (where batch size=1, 4 cores per instance) and batched (where batch size is greater than 1, 1 instance per sub-NUMA node) Inference. As shown, the speedup of the 5th generation over the 4th generation Intel Xeon Scalable processor ranges from 23% to 39%. For the batched case, the batch size that performs the best is shown.
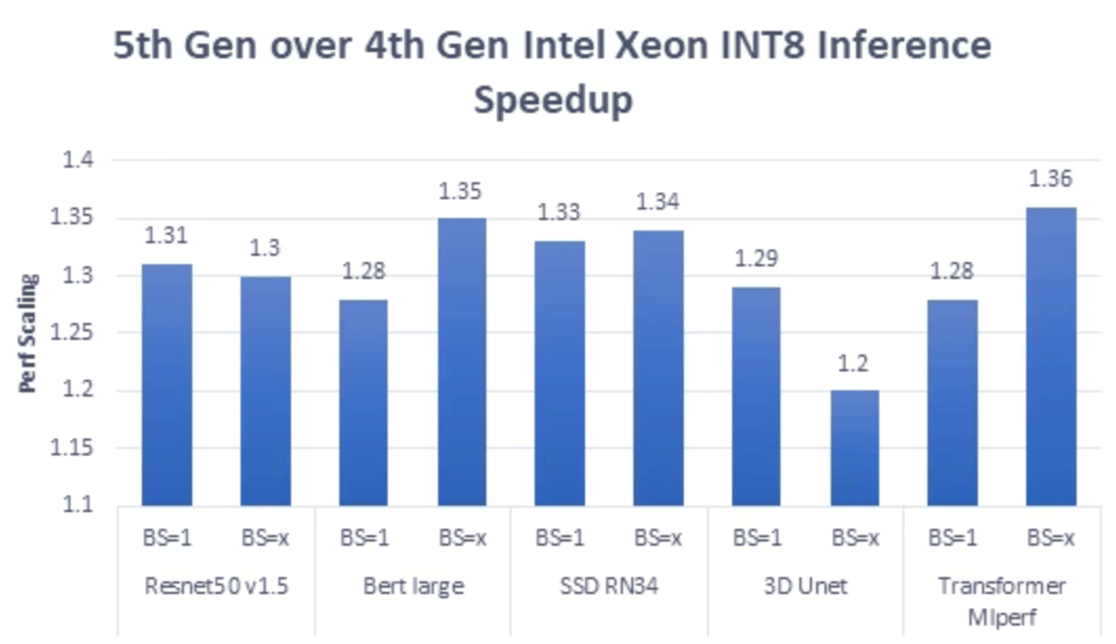
Similarly, the above chart shows inference performance improvement of quantized version (8-bit integer precision) of the same models and use cases mentioned previously. Here a speedup of 20% to 36% is observed.
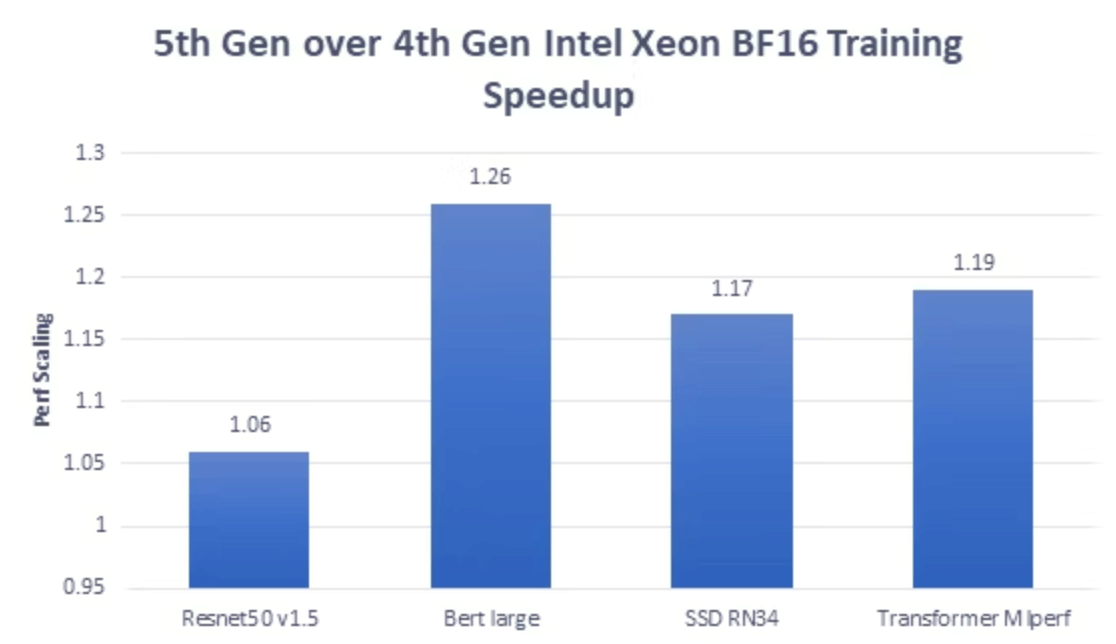
The previous chart shows the performance improvement for the model training case with bfloat16/float32 mixed precision. The 5th generation Intel Xeon Scalable processor can achieve 6% to 26% speedup over the 4th generation.
Performance Recommendations
As mentioned, previously, the 5th generation Intel Xeon Scalable processor has SNC2 mode enabled by default. Thus, to achieve the best performance when running AI workloads on the 5th generation Intel Xeon Scalable processor, it is recommended to run single training or inference instance per sub-NUMA node to reduce cross-NUMA access overhead.
Another performance impact to consider is the C6 power state. C6 is a sleep state that a process can enter in certain conditions to save power. However, it was found that the C6 state sometimes has a negative impact on model training or inference performance. Therefore, when running AI training or inference workloads, it is recommended to enable the C1 demotion option, which allows the p-code algorithm from Intel to promote cores from C6 to C1 state or to demote cores from C1 to C6 state.
Next Steps
Get the software and try the optimizations for yourself.
TensorFlow 2.14 (intel-tensorflow-avx512 2.14.0)
We encourage you to check out Intel’s AI Tools and framework optimizations and learn about the open, standards-based oneAPI multiarchitecture, multivendor programming model that forms the foundation of the Intel® AI Portfolio.
For more details about the 5th generation Intel Xeon Scalable processor, visit Performance Data for Intel® AI Data Center Products.
Acknowledgements
The results presented in this blog represent the work of many people from different teams at Intel.
Syed Shahbaaz Ahmed, Md Faijul Amin, Nick Camarena, Gauri Deshpande, Ashiq Imran, Ellie Jan, Susan Kahler, Kanvi Khanna, Geetanjali Krishna, Daniel M Lavery, Nhat Le, Christopher Lishka, Sachin Muradi, Shamima Najnin, Tatyana Primak, Rajesh Poornachandran, AG Ramesh, Lei Rong, Nahian Siddique, Bhavani Subramanian, Yimei Sun, Om Thakkar, Jojimon Varghese, Karen Wu, Guozhong Zhuang.
Product and Performance Information
1 Data was collected on 2-socket systems with the system and software configurations detailed as follows.
Intel® Xeon® Platinum processor 8592+ with 1024 GB memory (16 x 64 GB DDR5 5600 MT/s), microcode 0x21000161, hyperthreading on, turbo on, CentOS* Stream 9, kernel 6.2.0-emr.bkc.6.2.3.6.31.x86_64, BIOS version EGSDCRB1.SYS.0105.D74.2308261933, L2 AMP prefetcher disabled, C1 demotion enabled; Software TensorFlow* 2.14.dev202334, Model Zoo for Intel Architecture, tested by Intel on 9/7/2023.
Intel® Xeon® Platinum processor 8480+ processor with 1024 GB memory (16 x 64 GB DDR5 4800 MT/s), microcode 0x2b0004b1, hyperthreading on, turbo on, CentOS Stream 8, kernel 5.15.0-spr.bkc.pc.16.4.24.x86_64, BIOS version EGSDCRB1.SYS.0102.D37.2305081420; Software TensorFlow 2.14.dev202334, Model Zoo for Intel architecture, tested by Intel on 9/5/2023.