This article focuses on the steps to improve software performance with vectorization. Included are examples of full applications along with some simpler cases to illustrate the steps to vectorization. As hardware moves forward adding more cores and wider vector registers, software must modernize or change to match the hardware and deliver higher levels of parallelism and vectorization. This increased performance will solve more complex problems in finer resolution. A previous article, Recognizing and Measuring Vectorization Performance, explained how to measure how effectively the software was vectorized.
In this article the terms SIMD and vectorization are used synonymously. A brief review of vectorization is discussed in the introduction. SIMD stands for Single Instruction Multiple Data; the same instruction is used on multiple data elements simultaneously. Intel® Advanced Vector Extensions 512 (Intel® AVX-512) provides registers that are 512 bits wide. One of these registers may be filled with 8 double precision floating point values, or 16 single precision floating point values, or 16 integers. When the register is fully populated a single instruction is applied that operates on 8 to 16 values (depending on the types of values and instruction used) simultaneously (see Figure 1).
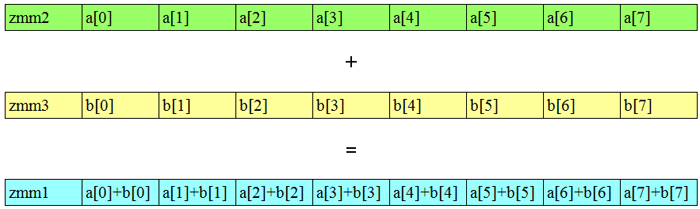
Figure 1: Example of SIMD operations on zmm Intel® Advanced Vector Extensions 512 registers.
When the Intel AVX-512 registers are filled across all available lanes performance can be 8 to 16 times faster. Typically there are many scalar operations to perform, as well as some shuffling and data movement, so a speedup of 8 to 16 is not delivered for a full application (though performance increases significantly). Intel® Advanced Vector Extensions 2 (Intel® AVX2) and Intel® Advanced Vector Extensions (Intel® AVX) instructions are half the width of Intel AVX-512 instructions and Intel® Streaming SIMD Extensions 4 instructions are half the width of Intel AVX and Intel AVX2 instructions. All deliver increasing levels of performance.
Taking software to new performance levels with vectorization
How does a software developer go from scalar code to vector mode? There are several steps to follow:
- Use vectorized libraries (for example, the Intel® Math Kernel Library)
- Think SIMD (think what is done repetitively or multiple times)
- Do a performance analysis (collect data, and then improve)
- Express SIMD
The first three steps are covered in the article referenced above. This article focuses on expressing SIMD and code modifications and includes the following:
- Use pragmas and directives
- Write SIMD-enabled functions
- Remove loop invariant dependencies
- Expand temporary variables to short vectors
- Pay attention to data alignment
- Improve data layout
Pragmas/Directives and dependence
Compilers do a great job of vectorization. There are still times when a compiler is not able to disambiguate memory references inside a repeated do loop to safely guarantee that there are no dependencies between one loop iteration and another. When the compiler cannot determine data independence it will produce scalar code instead of vectorized code. Other times the analysis for the compiler may become too complex, and the compiler may stop and produce scalar code rather than vectorized code.
The most common method to improve vectorization is the addition of pragmas or directives. A compiler pragma (C/C++) or directive (Fortran*) gives the compiler more information about the code segment than it can discern from the code alone allowing the compiler to perform more optimizations. The most common problem for which pragmas or directives are applied is pointer disambiguation, which is the inability to determine if it is safe to vectorize a for or do loop. If you know that the data entering the do (or for) loop does not overlap, you can add a pragma or a directive instructing the compiler to ignore the potential dependency and vectorize it.
Various pragma/directives were developed by different compiler groups. The need to tell compilers to ignore potential data dependencies is so common that it is easier for software developers to have a common set of pragmas and directives recognized by all compilers rather than proprietary pragmas for each compiler. The OpenMP* organization filled that void by adding a SIMD compiler pragma/directive to the OpenMP 4.0 specifications in 2013. This way you can use a standard directive/pragma and know that it will be recognized by many compilers.
The syntax for this directive/pragma is:
#pragma omp simd
!$omp simd
There are additional options to the SIMD pragma that may also be useful:
safelen(length),linear(list:linear-step),aligned(list[alignment]) , . . .
These additional parameters may be useful if the code contains something like:
for (i=8;i<n;i++)
{ . . .
x[i] += x[i-8]* . . . ; . . .
}
There is a dependence between iterations. However, there is a safe length for this (the dependence only goes back 8 values) so the compiler can safely vectorize for a SIMD length of 8. In this case, use a pragma like:
#pragma omp simd safelen(8)
When you use the SIMD pragma/directive, you’re telling the compiler that you know enough about the program and data access that the assumption regarding no dependencies is safe. If you’re wrong, the code may deliver incorrect results. There is a quick check that some developers use for a sanity check—reverse the order of loops—but this is not a guarantee. If reversing the order of the loop changes the value, the code is not safe to vectorize or thread without changes. Additional specifications such as safelen or an atomic operation or other controls may be required to make the code safe to vectorize.
If the results are correct, it might be that for this particular dataset the order of operations did not matter, but it could matter with a different dataset. So failing the check clearly shows dependence, passing the check is not a guarantee of safety. Tools such as Intel® Advisor XE provide a more rigorous analysis and can help identify dependencies and give you hints as to when it is safe to apply SIMD pragmas or directives.
Functions
Frequently a function or subroutine call within a loop prevents vectorization. There are a couple of possibilities that may help in this situation. A short function can be written as a vectorizable function. Vector versions of many transcendental functions exist in math libraries used by the compiler. With the proper syntax, the compiler will generate both vector and scalar versions of a user-written function.
Let’s say there is a function that squares a number and adds a constant to the value. The function might be like this:
double sqadd(double a, double r)
{
double t ;
t = a*a + r ;
return(t) ;
}
To tell the compiler to create a vector version of this function as well as a scalar version write it like this:
#pragma omp declare simd // tell compiler to generate vector versiondouble sqadd(double a, double r)
{
double t ;
t = a*a + r ;
return(t) ;
}
Next, at the places where the function is called, further instruct the compiler to vectorize the loop in the presence of a function call like this:
#pragma omp simd // instruct compiler to generate vector code even though loop invokes function
for (i=0 ; i<n; ++)
{
. . .
anarray[i] = sqadd(r, t) ;
. . .
}
In Fortran the correct directive to use is:
!$omp declare simd(subroutine name)
For example the above function in Fortran may be written as shown below to generate vectorizable implementations:
real*8 function sqadd(r,t) result(qreal)
!$omp declare simd(sqadd)
real*8 :: r
real*8 :: t
qreal = r*r + t
end function sqadd
In the file where the function is invoked I defined it like this:
INTERFACE
real*8 function sqadd(r,t)
!$omp declare simd(sqadd)
real*8 r
real*8 t
end function sqadd
END INTERFACE
The compiler vectorized the do loop containing the call to sqadd. If modules are used, and the function or subroutine is declared SIMD enabled, any file that uses that module can see the function/subroutines are SIMD enabled and then generate vectorized code. For more information on creating SIMD functions/subroutines in Fortran, see this article on explicit vector programming in Fortran.
Loop invariant dependencies
It is common to see do/for loops with an if/else statement in the middle of them where the condition of the if/else statement does not change within the loop. The presence of the conditional may prevent vectorization. This can be rewritten so that it is easier to vectorize. For example if the code looks something like:
for (int ii = 0 ; ii < n ; ++ii)
{
. . .
if (method == 0)
ts[ii] = . . . . ;
else
ss[ii] = . . . ;
. . .
}
This can be rewritten as:
if (method == 0)
for (int ii = 0; ii < n ; ++ii)
{
. . .
ts[ii] = . . . ;
. . .
}
else
for (int ii = 0 ; ii < n; ++ii)
{
. . .
ss[ii] = . . . ;
. . .
}
The above two techniques were applied to the MPAS-Oi oceanic code. The MPAS-O code simulates the earth's ocean system and can work on time scales of months to thousands of years. It handles regions below 1 km as well as global circulation. Doug Jacobsenii from LANL participated in a short collaboration with ParaTools where we used the TAU Performance System* to measure vectorization intensity of this routine on the Intel® Xeon Phi™ coprocessor. Based on the data we looked where the report indicated low vector intensity and then at the code and compiler report.
Excerpts of the code are shown below:
do k=3,maxLevelCell(iCell)-1
if(vert4thOrder) then
high_order_vert_flux(k, iCell) = &
mpas_tracer_advection_vflux4( tracer_cur(k-2,iCell),tracer_cur(k-1,iCell), &
tracer_cur(k,iCell),tracer_cur(k+1,iCell), w(k,iCell))
else if(vert3rdOrder) then
high_order_vert_flux(k, iCell) = &
mpas_tracer_advection_vflux3( tracer_cur(k-2,iCell),tracer_cur(k-1,iCell), &
tracer_cur(k,iCell),tracer_cur(k+1,iCell), w(k,iCell), coef_3rd_order )
else if (vert2ndOrder) then
verticalWeightK = verticalCellSize(k-1, iCell) / (verticalCellSize(k, iCell) +&
verticalCellSize(k-1, iCell))
verticalWeightKm1 = verticalCellSize(k, iCell) / (verticalCellSize(k, iCell) +&
verticalCellSize(k-1, iCell))
high_order_vert_flux(k,iCell) = w(k,iCell) * (verticalWeightK * tracer_cur(k,iCell) +&
verticalWeightKm1 * tracer_cur(k-1,iCell))
end if
tracer_max(k,iCell) = max(tracer_cur(k-1,iCell),tracer_cur(k,iCell),tracer_cur(k+1,iCell))
tracer_min(k,iCell) = min(tracer_cur(k-1,iCell),tracer_cur(k,iCell),tracer_cur(k+1,iCell))
end do
We quickly saw that this code contained both a subroutine call and invariant conditional within the do loop. So we made the subroutine vectorizable and swapped the positions of the loop and conditional. The new code looks like this:
! Example flipped loop
if ( vert4thOrder ) then
do k = 3, maxLevelCell(iCell) - 1
high_order_vert_flux(k, iCell) = &
mpas_tracer_advection_vflux4( tracer_cur(k-2,iCell),tracer_cur(k-1,iCell), &
tracer_cur(k,iCell),tracer_cur(k+1,iCell), w(k,iCell))
end do
else if ( vert3rdOrder ) then
do k = 3, maxLevelCell(iCell) - 1
high_order_vert_flux(k, iCell) = &
mpas_tracer_advection_vflux3( tracer_cur(k-2,iCell),tracer_cur(k-1,iCell), &
tracer_cur(k,iCell),tracer_cur(k+1,iCell), w(k,iCell), coef_3rd_order )
end do
else if ( vert2ndOrder ) then
do k = 3, maxLevelCell(iCell) - 1
verticalWeightK = verticalCellSize(k-1, iCell) / (verticalCellSize(k, iCell) +&
verticalCellSize(k-1, iCell))
verticalWeightKm1 = verticalCellSize(k, iCell) / (verticalCellSize(k, iCell) +&
verticalCellSize(k-1, iCell))
high_order_vert_flux(k,iCell) = w(k,iCell) * (verticalWeightK * tracer_cur(k,iCell) +&
verticalWeightKm1 * tracer_cur(k-1,iCell))
end do
end if
In this case we combined two of the techniques listed in this article to get vectorized code and improve performance: make subroutines/functions SIMD enabled or vectorizable and move out invariant conditionals. You will typically find that you must apply multiple techniques to tune your code. Each change is a step in the correct direction; sometimes the performance doesn't really jump ahead until all the changes are made; change data layout, apply pragmas or directives, align data and such. Each element is a step to improve performance. Several more techniques follow in the upcoming sections.
Expand temporary scalars into short arrays
Temporary values are commonly calculated in the middle of a for or do loop. Sometimes this is done because an intermediate value is used in several calculations, and the common subset of computations is calculated and then held for a short time for reuse. Sometimes it just makes the code easier to read. If you apply “think SIMD” to this situation it means to make the temporary arrays into short vectors that are as long as the widest SIMD register the code will run on.
This technique was applied to finite element and finite volume methods solving a system of partial differential equations related to calcium dynamics in a heart cell. Calcium ions play a crucial role in driving the heartbeat. Calcium is released into the heart cell at a lattice of discrete positions throughout the cell, known as calcium release units (CRUs). The probability that calcium will be released from a CRU depends on the calcium concentration at that CRU. When a CRU releases calcium (it “fires”), the local concentration of calcium ions increases sharply, and the calcium that diffuses raises the probability for release at neighboring sites. As a sequence of CRUs begins to release calcium throughout the cell, the release can self-organize into a wave of increasing concentration. A wave that is triggered among the normal physiological signaling (for example, the cardiac action potential) can lead to irregular heartbeats and possibly a life-threatening ventricular fibrillation. These dynamics are simulated by a system of three time-dependent partial differential equations developed by Leighton T. Izu.
Consider special-purpose MPI code that simulates these calcium dynamics developed by Matthias K. Gobbert and his collaborators (Numerical Simulation of Calcium Waves in a Heart Cell). This code solves the system of partial differential equations using finite element or finite volume methods and matrix-free linear solvers. Using a profiler such as the TAU Performance System, we find that most of the runtime is spent in the matrix vector multiplication function.
Here is a representative code snippetiii from this function (variables or functions changed are in bold italics):
for(iy = 0; iy < Ny; iy++)
{ for(ix = 0; ix < Nx; ix++)
{
iz = l_iz + spde.vNz_cum[id];
i = ix + (iy * Nx) + (iz * ng);
l_i = ix + (iy * Nx) + (l_iz * ng);
t = 0.0;
if (ix == 0)
{
t -= ( 8.0/3.0 * Dxdx) * l_x[l_i+1 ];
diag_x = 8.0/3.0 * Dxdx;
} else if (ix == 1)
{
t -= ( bdx + 4.0/3.0 * Dxdx) * l_x[l_i-1 ];
t -= ( Dxdx) * l_x[l_i+1 ];
diag_x = bdx + 7.0/3.0 * Dxdx;
}
if (iy == 0)
{
. . .
} else if (iy == 1)
{
t -= ( bdy + 4.0/3.0 * Dydy) * l_x[l_i-Nx];
t -= ( Dydy) * l_x[l_i+Nx];
diag_y = bdy + 7.0/3.0 * Dydy;
} else if (iy == Ny-2)
{
t -= (bdy + Dydy) * l_x[l_i-Nx];
t -= 4.0/3.0 * Dydy * l_x[l_i+Nx];
diag_y = bdy + 7.0/3.0 * Dydy;
} else if (iy == Ny-1)
{
t -= (2*bdy + 8.0/3.0 * Dydy) * l_x[l_i-Nx];
diag_y = 2*bdy + 8.0/3.0 * Dydy;
}else
{
t -= (bdy + Dydy) * l_x[l_i-Nx];
t -= Dydy * l_x[l_i+Nx];
diag_y = bdy + 2.0 * Dydy;
}
if (iz == 0)
{
.
.
.
}
.
.
.
if (il == 1)
{
.
.
.
l_y[l_i] += t*dt + (d + dt*(diag_x+diag_y+diag_z + a +
getreact_3d (is,js,ns, l_uold, l_i) )) * l_x[l_i];
}else
{
l_y[l_i] += t*dt + (d + dt*(diag_x+diag_y+diag_z + a )) *
l_x[l_i];
}
}
}
The temporary variable t is expanded to be a short array temp[8]. In addition, a new short vector alocal is created to store values equivalent to the function call to getreact_3d(). To facilitate ease of programming, Intel® Cilk™ Plus expressions are used. When the temporary arrays are used, the new code looks like this (new variables or changed variables are bold italics for ease of recognition):
for(iy = 0; iy < Ny; iy++)
{
...
for(ix = 8; ix < Nx-9; ix+=8)
{
i = ix + (iy * Nx) + (iz * ng);
l_i = ix + (iy * Nx) + (l_iz * ng);
temp[0:8] = 0.0;
temp[0:8] -= ( bdx + Dxdx) * l_x[l_i-1:8 ];
temp[0:8] -= ( Dxdx) * l_x[l_i+1:8 ];
diag_x = bdx + 2.0 * Dxdx;
if (iy == 0)
{
temp[0:8] -= ( 8.0/3.0 * Dydy) * l_x[l_i+Nx:8];
diag_y = 8.0/3.0 * Dydy;
} else if (iy == 1)
{
temp[0:8] -= ( bdy + 4.0/3.0 * Dydy) * l_x[l_i-Nx:8];
temp[0:8] -= ( Dydy) * l_x[l_i+Nx:8];
diag_y = bdy + 7.0/3.0 * Dydy;
} else if (iy == Ny-2)
{
temp[0:8] -= (bdy + Dydy) * l_x[l_i-Nx:8];
temp[0:8] -= 4.0/3.0 * Dydy * l_x[l_i+Nx:8];
diag_y = bdy + 7.0/3.0 * Dydy;
}else if (iy == Ny-1)
{
temp[0:8] -= (2*bdy + 8.0/3.0 * Dydy) * l_x[l_i-Nx:8];
diag_y = 2*bdy + 8.0/3.0 * Dydy;
}else
{
temp[0:8] -= (bdy + Dydy) * l_x[l_i-Nx:8];
temp[0:8] -= Dydy * l_x[l_i+Nx:8];
diag_y = bdy + 2.0 * Dydy;
}
if (iz == 0)
{
.
.
.
}
.
.
.
if (il == 1)
{
. . .
alocals[0:8] = . . .
// operations that would be done by function getreact_3d()
l_y[l_i:8] += temp[0:8]*dt + (d + dt*(diag_x+diag_y+diag_z + a +
alocals[0:8])) * l_x[l_i:8];
}else
{
l_y[l_i:8] += temp[0:8]*dt + (d + dt*(diag_x+diag_y+diag_z + a )) *
l_x[l_i:8];
}
. . .
}
}
When these changes were applied to the code, the execution time on an Intel® Xeon Phi™ coprocessor 5110P went from 68 hours 45 minutes down to 38 hours 10 minutes, cutting runtime by 44 percent!
Data alignment
Notice that the original loop went from ix = 0 to Nx - 1. There were some special conditions to cover ix = 0 or 1, but instead of the new code going from ix = 2 to Nx - 1 it begins at 8. You might recognize this is done to maintain data alignment in the kernel loop.
In addition to operating on full SIMD register width, performance is best when data moving into the SIMD registers is aligned on cache line boundaries. This is especially true for the Intel Xeon Phi coprocessors (it helps all processors, but the percentage performance impact is largest on Intel Xeon Phi coprocessors). The arrays are initially aligned on cache boundaries, then cases where ix=0,7 were handled before entering the ix loop, then all the movements within the ix loop operate on subsections of arrays where each subsection is aligned to a cache line boundary. It would have been good if the software developers in this case had added a pragma assume aligned, which would not have improved code performance, but it may have eliminated the need for the compiler to add a peel loop to execute before beginning the aligned kernel loop. In a previous article I pointed out that unaligned matrices could decrease code performance for selected kernels by over 53 percent. The times for aligned versus unaligned matrixes in a recent simple matrix multiply test on a platform based on an Intel® Xeon® processor E5-2620 are shown in Table 1:
|
Version |
Time (seconds) |
|
Aligned |
3.78 |
|
Un-aligned |
4.86 |
Table 1: Matrix multiply test results—aligned versus unaligned.
For further investigation, the code segments to repeat that exercise are available at: samplematrixcode.
Data Layout
Software performs best when the data layout is organized the way data is accessed. An example that illustrates this is the tutorial that accompanies ParaTools’ ThreadSpotter*iv, which you can download and run (ThreadSpotter is not required to build or run the different cases). In the first case a linked list is used to fill and access a database. The initial data storage element is a structure that is defined as shown below:
struct car_t {
void randomize();
color_t color;
model_t model;
std::string regnr;
double weight;
double hp;
};
A linked list is formed of these structures, and then queries are made. The linked list allows data to be accessed in a random, unpredictable method that is difficult for the prefetch section of the processor to accurately predict. In Table 2, this is shown in the “Linked list” row. When the linked list is replaced by a standard C++ vector class, data is accessed in a linear fashion.
The vector basis is shown below:
class database_2_vector_t : public single_question_database_t
{
public:
virtual void add_one(const car_t &c);
virtual void finalize_adding();
virtual void ask_one_question(query_t &query) const;
private:
typedef std::vector<car_t> cars_t;
cars_t cars;
};
In Table 2 this is shown in the “Vector” row. As shown in Table 2, performance increases significantly with this improved access pattern. This change preserved the same structure. When a query is related to the car color, notice that the entire structure is brought into cache, but only one element of the structure— color—is used. In this case the memory bus is occupied transferring extra data to and from memory and cache. This consumes both extra bandwidth as well as cache resources.
In the next case the cars structure used in the previous two examples is replaced with a new class:
class database_3_hot_cold_vector_t : public single_question_database_t
{
public:
virtual void add_one(const car_t &c);
virtual void finalize_adding();
virtual void ask_one_question(query_t &query) const;
private:
typedef std::vector<color_t> colors_t;
typedef std::vector<model_t> models_t;
typedef std::vector<double> weights_t;
colors_t colors;
models_t models;
weights_t weights;
typedef std::vector<car_t> cars_t;
cars_t cars;
};
Notice that there are separate vectors for colors_t, models_t, and weights. When a query is based on colors, the colors_t vector is brought into cache and the model and weight information is not brought in, reducing the pressure on data bandwidth and L1 cache use. The vector brought into cache for the searches is “hot”; the vector not brought into cache is “cold.” This is shown in the “Hot-cold vectors” row. This also allows data to be accessed in a preferred unit stride fashion and use all lanes of the SIMD registers. See the performance improvements shown in Table 2.
This last data layout change is equivalent to changing an Array of Structures to a Structure of Arrays. The concept of changing from AOS to SOA is to place data contiguously in the manner it is accessed. Developers are encouraged to learn more about AOS to SOA such as when it is advantageous to adopt a Structure of Arrays rather than operate on an Array of Structures.
|
Version |
Average Time/Query Set |
Speed Up |
|
Linked list |
11.1 |
1 |
|
Vector |
0.32 |
34 |
|
Hot-cold vectors |
0.22 |
50 |
Table 2: Data layout impact on performance on platform based on the Intel® Xeon® E5-2620 processor.
Summary
Performance increases significantly when software effectively fills and uses the vector registers available on current platforms. The steps listed in this article were:
- Use appropriate pragmas and directives
- Utilize SIMD-enabled user-defined functions/subroutines
- Move invariant conditionals outside of the inner-most loops
- Store data in the order in which it is used
- Align data on cache line boundaries
Software developers who embrace these techniques and use the information from compiler optimization reports should see their software performance improve. Tools such as Intel Advisor XE can help improve vectorization as well. Vectorization is an important step in software optimization and performance optimization. Adopt these techniques, and check-out the Intel Developer Zone, Modern Code site for more details and find answers to your questions. Finally, please share your experiences in the comments section of this article.
i MPAS-O oceanic code development was supported by the DOE Office of Science BER.
ii Douglas Jacobsen work was supported by the DOE Office of Science Biological and Environmental Research (BER), MPAS code example used by permission.
iii Samuel Khuvis. Porting and Tuning Numerical Kernels in Real-World Applications to Many-Core Intel Xeon Phi Accelerators, PhD Thesis, Department of Mathematics and Statistics, University of Maryland, Baltimore County, May 2016. Code segments used by permission.
iv Thread Spotter is distributed by ParaTools, Inc. tutorial code segments used by permission. Intel® Advisor XE is a part of Intel® Parallel Studio XE, distributed by Intel Corp.