RocksDB is a high performance, open source key value store that appeals to developers looking for fast, persistent storage and a flexible API. RocksDB supports various storage hardware, with flash as the initial focus. RocksDB is performant for large server workloads and supports efficient point lookups as well as range scans. It is configurable to support high random-read workloads, high write workloads, or a combination of both. The RocksDB architecture supports easy tuning of trade-offs for different workloads and hardware. Many customers use RocksDB as their underlying data storage. RocksDB presents a real-world use case for optimizing using Intel® Optane™ Persistent Memory (PMem) and the Persistent Memory Development Kit (PMDK). This article highlights some of the optimization opportunities in RocksDB components and the code changes made to these components.
Background on RocksDB
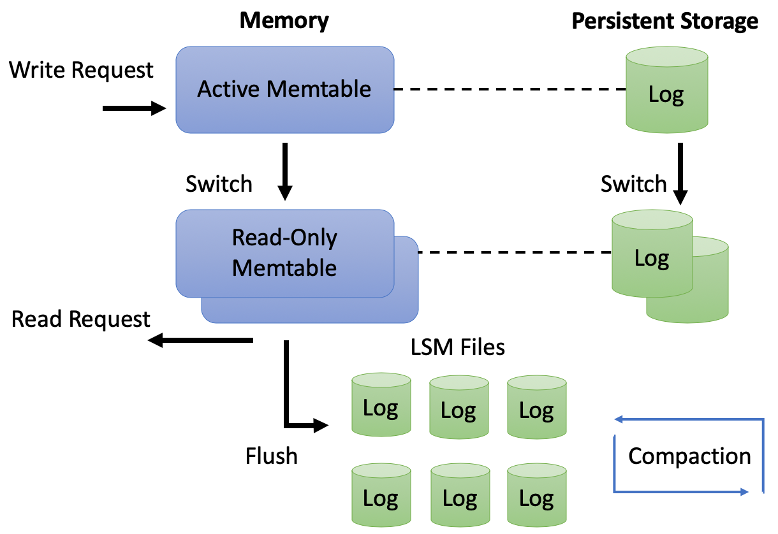
RocksDB architecture is comprised of the following components. This section will provide a brief overview of these components and how they interact.
RocksDB Architecture
The basic constructs of RocksDB are:
- memtable: an in-memory data-structure to ensure very low latency on reads
- sorted static table files (SST files): where data is finally persisted
- a write-ahead log (WAL) file: to ensure that data written to memory but not yet written to SST files is not lost
These components ensure the speed and persistence that RocksDB is known for. Every write to a Rocks database is written in two places: (1) the memtable, and (2) the WAL log file on disk. When the memtable fills up, it flushes its content to an SSTfile (Level-0 of the LSM tree) residing on a persistent storage, and the corresponding WAL file is deleted. RocksDB removes duplicate and overwritten keys in the memtable when it is flushed to a file in L0. In compaction, some files are periodically read in and merged to form larger files, often going into the next LSM level (such as L1, up to Lmax).
The entire database is stored in SSTFiles. In the event of a power failure, the WAL file can be used to completely recover the data in the memtable, which is necessary to restore the database to its original state.
SST File Formats
RocksDB has two types of SSTfile formats: Block-based Tables and Plain Tables that are used in different application scenarios:
- A block-based Table is the default format of SST files. The keys in the file are sorted, so a search operation for a particular key can be done fast by binary search. At the beginning of the SST file, the key/value pairs are arranged in order and allocated in consecutive blocks. The default block size is 4KB.
- The plain table format is optimized for lower query latency on DRAM-only memory. An in-memory index is used as a hash to replace simple binary search with hash + binary search. This index can bypass block cache and avoid the overhead of block copy and LRU cache maintenance. Additionally, the index avoids any memory copy when querying (mmap).
Intel uses persistent memory to optimize RocksDB to meet the above two scenarios. The KVS (key-value separate) solution is suitable for Block-based Tables, while the second is a Plain Table solution, suitable for the scenario where a Plain Table is used.
Opportunities for Persistent Memory with RocksDB
RocksDB is known for its reliability and speed. Due to its architecture, however, the performance of reads aren’t as good as that of writes. The Block-based Table solution suffers from write and space amplification. Write amplification is the amount of data written to storage compared to the amount of data the application wrote. Space amplification is the space required by a data structure. Fragmentation increases space amplification, which requires temporary copies of the data. With large writes to the Block-based Table, compaction causes unpredictable and unexpected latency. The characteristics of a Plain Table make it very suitable for low-latency storage media. The team at Intel identified two areas for optimization within RocksDB:
- Separate keys and values to optimize write and space amplification,
- Use PMem and PMDK to improve the overall performance of the Plain Table.
PMem and the Persistent Programming Model
Intel Optane Persistent Memory is an innovative memory technology that delivers a unique combination of affordable large capacity and support for data persistence. Data on PMem is byte-addressable like memory and persistent like storage but typically doesn’t replace memory or storage.
The Persistent Memory Development Kit (PMDK) is a growing collection of libraries developed for various use cases, tuned, validated to production quality, and thoroughly documented. These libraries build on the Direct Access (DAX) feature available in both Linux and Windows, which allows applications direct load/store access to persistent memory by memory-mapping files on a persistent memory aware file system. In the optimization of RocksDB, we used the libraries libpmem and libpmemobj from the PMDK.
Key Value Separation Solution
For Intel’s KVS solution of RocksDB, engineers chose to store large data on PMem with the libpmemobj library, which is part of PMDK. The following functions were used:
- pmemobj_create used to create pool space on PMem for storing values
- pmem_memcpy_persist used to copy and flush data to persistent memory
- pmemobj_free used to free pool space
In the KVS solution, the SST file constitutes a key-value data structure with the value stored as a pointer to the actual value data that resides in PMem. You can see each of these functions in the code snippet below.
This is an everyday use case for persistent memory among many cloud software architectures. Redis is a similar example of a database that benefits from storing their KVS on persistent memory, seeing significant improvements in speed.
Plain Table Solution
The common characteristics of a Plain Table make it an excellent candidate for persistent memory. Plain Tables use mmap(memory-mapped files) to avoid page caching and eliminate context switching into the kernel. In this solution, libpmem was used to optimize the Plain Table in the io_posix.c file. pmem_memcpy_nodrain was used to optimize the write and flush performance. Instead of flushing, pmem_memcpy_nodrain, which is based on the Non-Temporal (NT) write instruction set, can bypass the cache.

Results
The PMem KVS Solution, currently under development, is targeted for applications storing large values that generate a lot of writing and compaction. The trade-off is that the read performance is not as good. You can find this version of RocksDB in the pmem-rocksdb github repository. The PMem KVS implementation is a modified fork of version 6.2.2 from the upstreamed RocksDB project on GitHub.
The Plain Table Solution, which used PMDK’s pmem_memcpy_nodrain function to bypass the kernel, shows improvements in transactions per second (TPS) and latency, compared to a regular memory file system. This solution uses DAX, which allows direct access without the need to context switch to the OS to run the filesystem. This feature makes it perfect for cases like pointer lookups, giving the table excellent read performance.
Summary
Using libraries from the PMDK, which handle much of the heavy lifting regarding programming persistent memory, was a considerable asset when optimizing RocksDB for Intel Optane PMem modules. With minimal effort, we were able to unlock all its available potential. The Plain Table and Key Value Separate solutions each saw improvements in write and read speeds of RocksDB. These changes are also available as open source, though haven’t yet been accepted to the RocksDB main. You can find this branch on GitHub under a dual GPLv2 and Apache license. Go ahead and check it out! Fork the code and let us know what you think when running the persistent version of RocksDB on your applications.