1. Abstract
OpenCL™ is the open standard to programming across multiple computing devices, such as CPU, GPU, and FPGA, and is an ideal programming language for heterogeneous computing implementation. This article is a step-by-step guide on the methodology of dispatching a workload to all OpenCL devices in the platform with the same kernel to jointly achieve a computing task. Although the article focuses on only the Intel processor, Intel® HD Graphics, Iris™ graphics, and Iris™ Pro graphics, theoretically, it works on all OpenCL-complied computing devices. Readers are assumed to have a basic understanding on OpenCL programming. The OpenCL framework, platform model, execution model, and memory model [1] are not discussed here.
2. Concept of Heterogeneous Computing Implementation
In an OpenCL platform, the host contains one or more compute devices. Each device has one or more computing units, and each compute unit has one or more processing elements that can execute the kernel code (Figure 1).
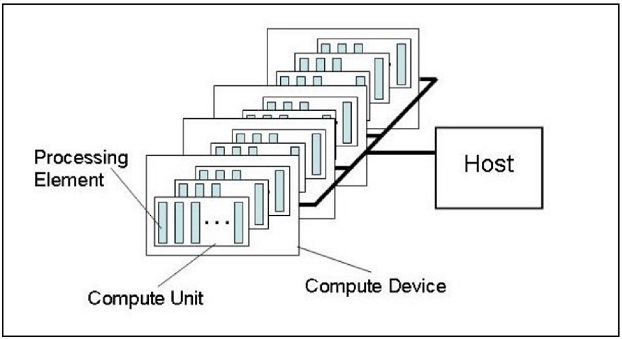
Figure 1: OpenCL™ platform model [2].
From the software implementation perspective, one normally starts OpenCL program from querying the platform. A list of devices can then be retrieved and the programmer can choose the device from those devices. The next step is creating a context. The chosen device is associated with the context and the command queue is created for the device.
Since one context can be associated with multiple devices, the idea is to associate both CPU and GPU to the context and create the command queue for each targeted device (Figure 2).
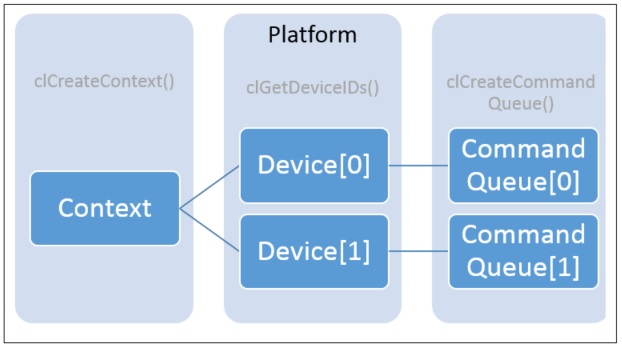
Figure 2: Topology of multiple devices from a programming perspective.
The workload is enqueued to the context (either in buffer or image object form). It thus is accessible to all devices associated to the context. The host program can distribute different amount of workload to those devices.
Assuming XX% of workload is offloaded to the CPU and YY% of the workload is offloaded to GPU, the value of XX% and YY% can be arbitrarily chosen as long as XX% + YY% = 100% (Figure 3).
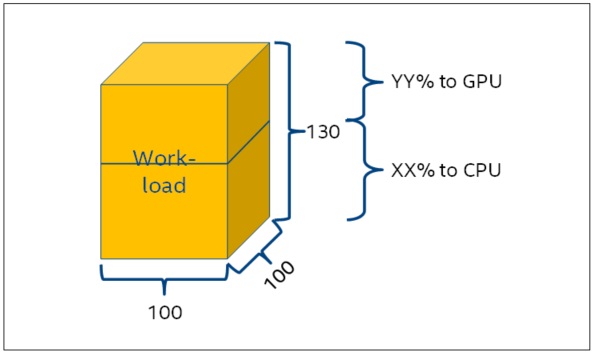
Figure 3: Workload dispatch of the sample implementation.
3. Result
In a sample Lattice-Boltzman Method (LBM) OpenCL heterogeneous computing implementation with 100 by 100 by 130 floating point workload, a normalized performance statistic using a different XX% (the percentage of workload to CPU) and YY% (the percentage of workload to GPU) combination is illustrated in Figure 4. The performance was evaluated on a 5th generation Intel® Core™ i7 processor with Iris™ Pro graphics. Note that although the combination (XX, YY) = (50, 50) has the maximum performance gain (around 30%,) it is not the general case. Different kernels might fit better in either the CPU or GPU. The best (XX, YY) combination must be evaluated case by case.
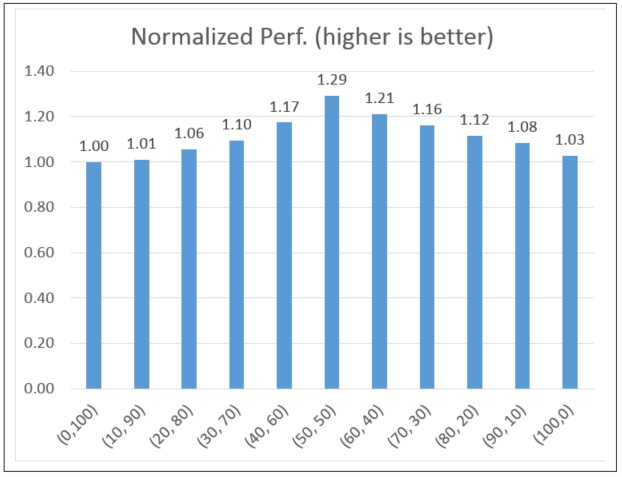
Figure 4: Normalized (XX, YY) combination performance statistics.
4. Implementation Detail
To be more illustrative, the following discussion assumes that the workload is a 100 by 100 by 130 floating point 3D array and the OpenCL devices are an Intel processor and Intel HD Graphics (or Iris graphics or Iris Pro graphics). Since the implementation involves only a host-side program, the OpenCL kernel implementation and optimization are not discussed here. The pseudocode in this section ignores the error checking. Readers are encouraged to add error-checking code themselves when adapting it.
4.1 Workload
The workload assumes a 100 × 100 x 130 floating point three-dimensional (3D) array, declared in the following form:
const int iGridSize = 100 * 100 * 130;
float srcGrid [iGridSize], dstGrid [iGridSize]; // srcGrid and dstGrid represent the source and
//the destination of the workload respectively
Although the workload assumes a 3D floating point array, the memory is declared as a one-dimensional array so that the data can be easily fitted into a cl_mem object, which is easier for data manipulation.
4.2 Data structures to represent the OpenCL platform
To implement the concept in Figure 2 programmatically, the OpenCL data structure must be designed with at least a cl_platform, a cl_context, and a cl_program object. In order to feed to the OpenCL API call, the cl_device_id, cl_command_queue, and cl_kernel objects are declared in pointer form. They could be instantiated via dynamic memory allocation according to the number of computing device used.
typedef struct {
cl_platform_id clPlatform; // OpenCL platform ID
cl_context clContext; // OpenCL Context
cl_program clProgram; // OpenCL kernel program source object
cl_int clNumDevices; // The number of OpenCL devices to use
cl_device_id* clDevices; // OpenCL device IDs
cl_device_type* clDeviceTypes; // OpenCL device types info. CPU, GPU, or
// ACCELERATOR
cl_command_queue* clCommandQueues; // Command queues for the OpenCL
// devices
cl_kernel* clKernels; // OpenCL kernel objects
} OpenCL_Param;
OpenCL_Param prm;
4.3 Constructing the OpenCL devices
The implementation discussed here considers the case with a single machine with two devices (CPU and GPU) so that readers can easily understand the methodology.
4.3.1 Detecting OpenCL devices
Detecting the device is the first step of OpenCL programming. The devices can be retrieved through the follow code snippet.
clGetPlatformIDs ( 1, &(prm.clPlatform), NULL );
// Get the OpenCL platform ID and store it in prm.clPlatform.
clGetDeviceIDs ( prm.clPlatform, CL_DEVICE_TYPE_ALL, 0, NULL, &(prm.clNumDevices) );
prm.clDevices = (cl_device_id*)malloc ( sizeof(cl_device_id) * prm.clNumDevices );
// Query how many OpenCL devices are available in the platform; the number of
// device is stored in prm.clNumDevices. Proper amount of memory is then
// allocated for prm.clDevices according to prm.clNumDevices.
clGetDeviceIDs (prm.clPlatform, CL_DEVICE_TYPE_ALL, prm.clNumDevices, prm.clDevices, \
NULL);
// Query the OpenCL device IDs and store it in prm.clDevices.
In heterogeneous computing usage, it is important to know which device is which in order to distribute the correct amount of workload to the designated computing device. ClGetDeviceInfo() can be used to query the device type information.
cl_device_type DeviceType;
prm.clDeviceTypes = (cl_device_type*) malloc ( sizeof(cl_device_type) * \
prm.clNumDevices );
// Allocate proper amount of memory for prm.clDeviceTypes.
for (int i = 0; i < prm.clNumDevices; i++) {
clGetDeviceInfo ( prm.clDevices[i], CL_DEVICE_TYPE, \
sizeof(cl_device_type), &DeviceType, NULL );
// Query the device type of each OpenCL device and store it in
// prm.clDeviceType one by one.
prm.clDeviceTypes[i] = DeviceType;
}
4.3.2 Preparing the OpenCL context
Once the OpenCL devices are located, the next step is to prepare the OpenCL context, which facilitates those devices. It is a straightforward step, as it is the same as any other OpenCL programming on creating the context.
cl_context_properties clCPs[3] = { CL_CONTEXT_PLATFORM, prm.clPlatform, 0 };
prm.clContext = clCreateContext ( clCPs, 2, prm.clDevices, NULL, NULL, NULL );
4.3.3 Create command queues
The command queue is the tunnel to load kernels, kernel parameters, and workload to the OpenCL device. One command queue is created for one OpenCL device; in this example, two command queues are created for CPU and GPU respectively.
prm.clCommandQueues = (cl_command_queue*)malloc ( prm.clNumDevices * \
sizeof(cl_command_queue) );
// Allocate proper amount of memory for prm.clCommandQueues.
for (int i = 0; i < prm.clNumDevices; i++) {
prm.clCommandQueues[i] = clCreateCommandQueue ( prm.clContext, \
prm.clDevices[i], CL_QUEUE_PROFILING_ENABLE, NULL);
// Create command queue for each of the OpenCL device
}
4.4 Compiling OpenCL kernels
The topology indicated in Figure 2 is implemented so far. The kernel source file then should be loaded and built for the OpenCL devices to execute. Note that there are two OpenCL devices in the platform. The two device IDs must be fed to the clBuildProgram() call so that the compiler can build the proper binary code for each device. The following source code snippet assumes that the kernel source code is loaded into a buffer, clSource, via file I/O calls and is not detailed below.
char* clSource;
// Insert kernel source file read code here. Following code assumes clSource buffer is
// properly allocated and loaded with the kernel source.
prm.clProgram = clCreateProgramWithSource (prm.clContext, 1, clSource, NULL, NULL );
clBuildProgram (prm.clProgram, 2, prm.clDevices, NULL, NULL, NULL );
// Build the program executable for CPU and GPU via feeding clBuildProgram() with
// “2”, which illustrates there are 2 target devices and the device ID list.
prm.clKernels = (cl_kernel*)malloc ( prm.clNumDevices * sizeof(cl_kernel) );
for (int i = 0; i < prm.clNumDevices; i++) {
prm.clKernels[i] = clCreateKernel (prm.clProgram, “<the kernel name>”, NULL );
}
4.5 Distributing the workload
After the kernel has been built, the workload can then be distributed to the devices. The following code snippet demonstrates how to dispatch the designated workload to each OpenCL device. Note that the setting OpenCL kernel argument, clSetKernelArg(), call is not demonstrated here. Different kernel implementation need different arguments. The code to set up the kernel argument is less meaningful in the example here.
// Put kernel argument setting code, clSetKernelArg(), here. Note that, the same argument
// must be set to the both kernel objects.
size_t dimBlock[3] = { 100, 1, 1 }; // Work-group dimension and size
size_t dimGrid[2][3] = { {100, 100, 130}, {100, 100, 130} }; // Work-item dimension
// and size for each OpenCL device
dimGrid[0][0] = dimGrid[1][0] = (int)ceil ( dimGrid[0][0] / (double)dimBlock[0] ) * \
dimBlock[0];
dimGrid[0][1] = dimGrid[1][1] = (int)ceil ( dimGrid[0][1] / (double)dimBlock[1] ) * \
dimBlock[1];
// Make sure the work-item size is a factor of work-group size in each dimension
dimGrid[0][2] = (int)ceil ( round(dimGrid[0][2]* (double)<XX> /100.0) / (double)dimBlock[2] )
* dimBlock[2]; // Work-items for CPU
dimGrid[1][2] = (int)ceil ( round(dimGrid[1][2] * (double)<YY> /100.0) /
(double)dimBlock[2] ) * dimBlock[2]; // Work-items for GPU
// Assume <XX>% of workload for CPU and <YY>% of workload to GPU
Size_t dimOffset[3] = { 0, 0, dimGrid[0][2] }; // The offset of the whole workload. It is
// the GPU workload starting point
for (int i = 0; i < 2; i++) {
If ( CL_DEVICE_TYPE_CPU == prm.clDeviceTypes[i] )
clEnqueueNDRangeKernel ( prm.clCommandQueues[i], prm.clKernels[i], \
3, NULL, dimGrid[0], dimBlock, 0, NULL, NULL );
else // The other device is CL_DEVICE_TYPE_GPU
clEnqueueNDRangeKernel ( prm.clCommandQueues[i], prm.clKernels[i], \
3, dimOffset, dimGrid[1], dimBlock, 0, NULL, NULL );
// Offload proper portion of workload to CPU and GPU respectively
}
5. Reference
[1] OpenCL 2.1 specification. https://www.khronos.org/registry/cl/
[2] Image courtesy of Khronos group.