Introduction
With machine learning and AI on the rise, the need for computing large data sets has also risen. GPUs contribute to this purpose, both in efficiency and agility. They have the capability to perform extensive mathematical and scientific computations in parallel.
When users think of a hardware GPU vendor, they don't typically think of Intel. However, several Intel® Data Center GPU options are available to accelerate AI workloads. Intel recently released a certified GPU plug-in for the Red Hat OpenShift* catalog, making it much easier to run these and other workloads on any of the Intel Data Center GPUs.
This article shows how Intel and Red Hat’s close collaboration brings all of the pieces together, including Security-Enhanced Linux* (SELinux) support so that certified Intel GPU drivers and plug-ins can be built, installed, and deployed to every Red Hat OpenShift node with an Intel GPU while minimizing downtime.
You will also get an overview of the capabilities for running AI workloads using Red Hat OpenShift on an Intel GPU. For more information, see Enable the Intel Data Center GPU and a how-to video.
About the Software
To avoid vendor lock-in, start by using open source software wherever you can. Both Red Hat and Intel have a long history of supporting open source software. Red Hat OpenShift gives you the advantage of open source with the additional benefit of experts who provide deep technical support when needed. For running AI workloads at scale, Red Hat OpenShift AI is an add-in that provides a curated set of AI-supporting applications that let you develop, optimize, deploy, and scale out AI workloads.
Next, consider which AI software stack to use. For AI training, PyTorch* and TensorFlow* are two of the most popular frameworks, but there are many others to choose from. Intel provides optimized packages for these frameworks that take advantage of AI acceleration on Intel CPUs and GPUs. The PyTorch Optimizations from Intel is one of these optimized runtimes.
You also need to think about the hardware resources needed to develop and scale out your models. The market includes AI applications that cover various domains with diverse requisites. What might be needed for training a model is probably different from what is needed to infer a model. You might be using all open source software, but models with vendor-specific hardware optimizations are much more difficult, arduous, and expensive to change.
How to Accelerate Inferencing Workloads
The rest of this article shows how to accelerate inferencing workloads using an Intel GPU to increase performance. To deploy your trained models in production, there is an open source software stack called OpenVINO™ toolkit that can be used to convert, optimize, and deploy models across Intel and Arm* processors as well as various GPUs that include Intel® Data Center GPU Flex Series. Red Hat OpenShift AI fully integrates OpenVINO toolkit and can install it as a certified operator. This makes it easier to start a Jupyter* Notebook with pretrained models that can run on many different types of CPUs and more recently GPUs.
You still need the ability to make sure that GPU resources are available to the workload in your pod: Use the OpenVINO™ model server to deploy models at scale. For Intel GPUs, a good way to do this is to install the device plug-ins from Intel certified operator from the OperatorHub that is integrated into Red Hat OpenShift. The operator is a collection of plug-ins that can discover Intel accelerators and other hardware resources to make them available to your workloads to schedule.
Recently, a GPU plug-in was certified as part of the device plug-ins from Intel. Only one instance of the plug-in needs to start. It only runs on nodes with GPUs and it can discover the total number of installed Intel Data Center GPU Flex Series, which includes the Intel Data Center GPU Flex 140 and Intel Data Center GPU Flex 170. The cluster administrator must own the entire provisioning of the hardware and software so that the data scientist has a nice GUI to train, optimize, and deploy AI models.
Prerequisites for Cluster Administrators
The cluster administrator has a few prerequisites before installing the device plug-in from Intel and starting the GPU plug-in. At least one node needs to have an Intel GPU with the driver installed. The Intel GPU driver isn't yet integrated into the kernels used in Red Hat OpenShift, but Red Hat provides a secure way to load kernel module drivers using its own Kernel Module Management operator. Until the driver is fully integrated, Intel maintains an updated GPU driver container image at its intel-data-center-gpu-driver-for-openshift repository.
The second prerequisite is to install the Node Feature Discovery operator in the cluster. This operator labels every node with its detailed capabilities, including whether it has an Intel GPU installed and other supported hardware features. This is helpful when you have massive clusters with multiple capabilities in each node.
The Red Hat-certified device plug-ins operator for the Red Hat OpenShift container platform 4.14 includes support for Intel® Software Guard Extensions (Intel® SGX), Intel GPUs, and most recently added support for Intel® QuickAssist Technology. You can learn more about Intel SGX integration in the Red Hat OpenShift container platform in Securing Your Workloads on Red Hat OpenShift Container Platform with Intel SGX. Figure 2 shows what the device plug-ins operator looks like in the Red Hat OpenShift OperatorHub Console catalog.
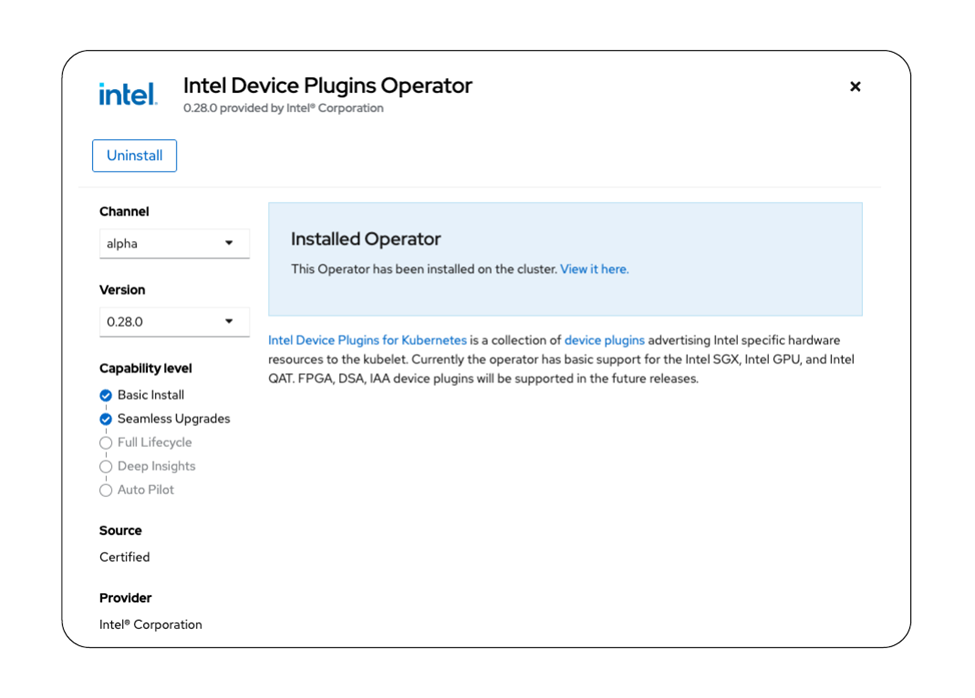
Figure 1. An installation of device plug-ins operator from Intel
After you install the operator, create a single GpuDevicePlugin instance. This instance uses a nodeSelector and runs on the nodes that the Node Feature Discovery operator labeled as having an Intel GPU. If you were to install the Intel SGX plug-in, it would only run on nodes that the Node Feature Discovery operator labeled as having support for Intel SGX. Just like the GPU plug-in, only one instance of the SGX plug-in is needed to run.
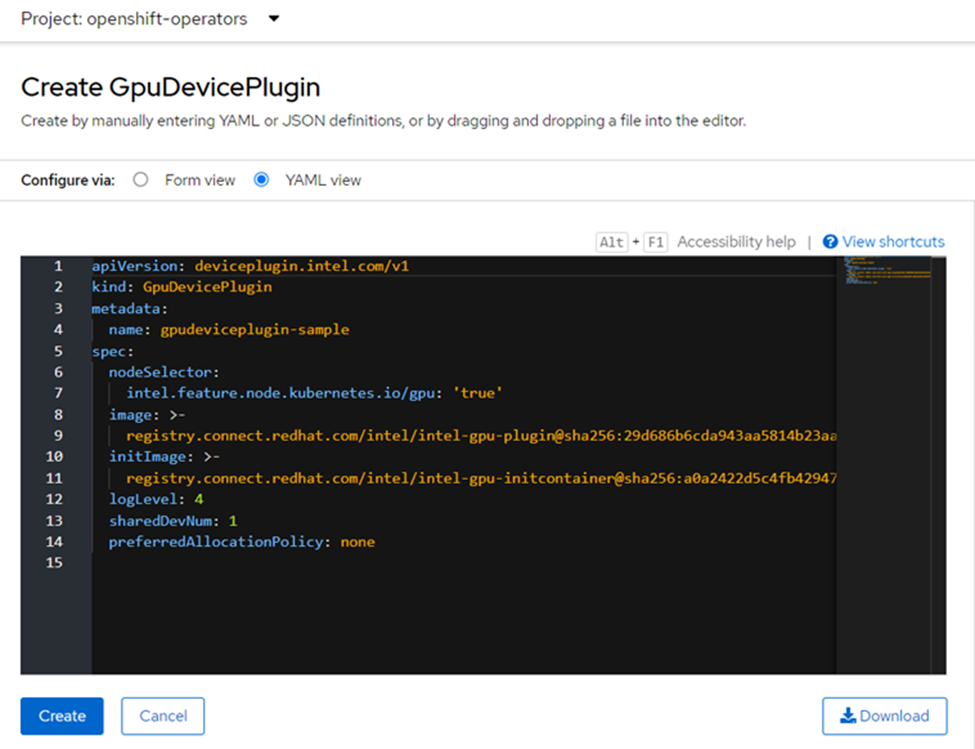
Figure 2. Intel GPU plug-in installation for Red Hat OpenShift
Now that the GPU plug-in is enabled, install the Red Hat OpenShift AI operator to create, deploy, and observe workloads. This operator integrates the operator for OpenVINO toolkit, which is used to optimize and run models. To enable different accelerators, code changes are not required, which makes it easier to migrate and run workloads across different cloud vendors as well as on-premise, providing the most flexibility to customers.
Optimize and Deploy a Trained Model for Data Scientists
After the cluster administrator has configured the infrastructure with Red Hat OpenShift AI, the OpenVINO toolkit, Intel GPU driver, and the Intel GPU plug-in are fully installed, the data scientist can get to work.
The OpenVINO toolkit provides various tools to deploy, optimize, and manage inference requests. Within Red Hat OpenShift AI, you can launch Jupyter Notebooks with the OpenVINO toolkit to interactively debug, optimize, and perform model inference. The OpenVINO toolkit is available as a certified operator in the Red Hat catalog. Models based on popular frameworks, such as TensorFlow, PaddlePaddle*, or ONNX* (Open Neural Network Exchange), can run on multiple hardware platforms with only a single argument change. There are even advanced options to support a combination of accelerators.
Data scientists get a nice GUI to decide which notebook image to launch. The OpenVINO toolkit optimizes and deploys a model that has already been trained. When you select one of these options, the OpenVINO toolkit prompts for how large of a pod to start, which determines how many CPUs your workload uses.
The OpenVINO toolkit includes a lot of prebuilt models and sample Python* code to run them. An OpenVINO toolkit inference workload with an Intel Data Center GPU Flex Series 140 and Red Hat OpenShift AI was presented at the Red Hat summit in May 2023. This demo used the OpenVINO toolkit live object detection sample, which is one of the models that downloads when you install the operator. Because OpenVINO toolkit does a good job of abstracting the hardware, you can just change a letter from c to g in the model conversion section to switch from running a model on the CPU to running it on a GPU. The metrics and live usage of a GPU can be tracked on Red Hat OpenShift container platform with a custom Grafana* dashboard and XPU Manager, an Intel GPU open source tool.
Another example, which uses generative AI, was presented at KubeCon North America in 2023. You can watch a video of that demo and also see the notebook used on the OpenVINO™ notebooks on GitHub.
Figure 3 is a screenshot from a node with an Intel Data Center GPU Flex Series 140. This card has two GPUs with eight Xe-cores per GPU. That is why two GPUs show up in the Grafana chart in figure 3. For more advanced AI models, the Intel Data Center GPU Flex Series 170 is ideally suited because it has one GPU with 32 Xe-cores and 16 GB of memory versus 12 GB of memory.
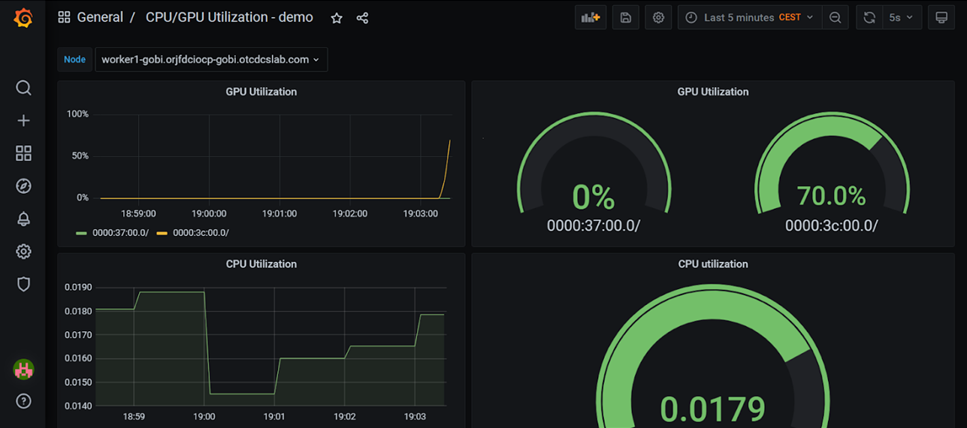
Figure 3. Grafana chart showing GPU use