Dr. Amarpal S. Kapoor, Technical Consulting Engineer; Sergey Gubanov, Software Development Engineer
Introduction
This article shows users of the Intel® MPI Library how to measure the virtual memory consumption of their applications. Some basic profiling might make users wrongly believe that the Intel MPI Library’s virtual memory consumption is unreasonably high. This article demonstrates the issue, explains the reason, and shows how to correctly measure the Intel MPI Library’s virtual memory consumption. Intel MPI Library 2019 U9 was used in this article.
Issue
Consider a test MPI program (test.c) making send and receive calls, located in the test folder ($I_MPI_ROOT/test) of the Intel MPI Library installation. The Linux test program was compiled and executed using the following commands:
$ mpiicc test.c -o test
$ mpiexec.hydra -n 192 -ppn 96 -hosts host1, host2 ./test
The binary was executed on two Intel® Xeon® Platinum 9242 processor-based dual socket nodes. Figure 1 shows truncated output from the top utility, which shows a virtual memory consumption of 17 GB per rank. This translates to a virtual memory consumption of 1.59 TB per node and 3.18 TB for a simple hello world program running on 2 nodes. However, this is incorrect.
Resolution
The Intel MPI Library uses a shared virtual memory region within a node, which is mapped into each process’s virtual address space. As a result, when virtual memory consumption is queried for any of the ranks, the size of the entire memory region is reported. All ranks on a node report the size of the same shared region. Most of the virtual memory measuring tools are unaware of this shared virtual memory region and as a result present incorrect data in this context. Therefore, the per-rank virtual memory consumption (17 GB) reported by the top utility is in fact the total virtual memory consumption per node.
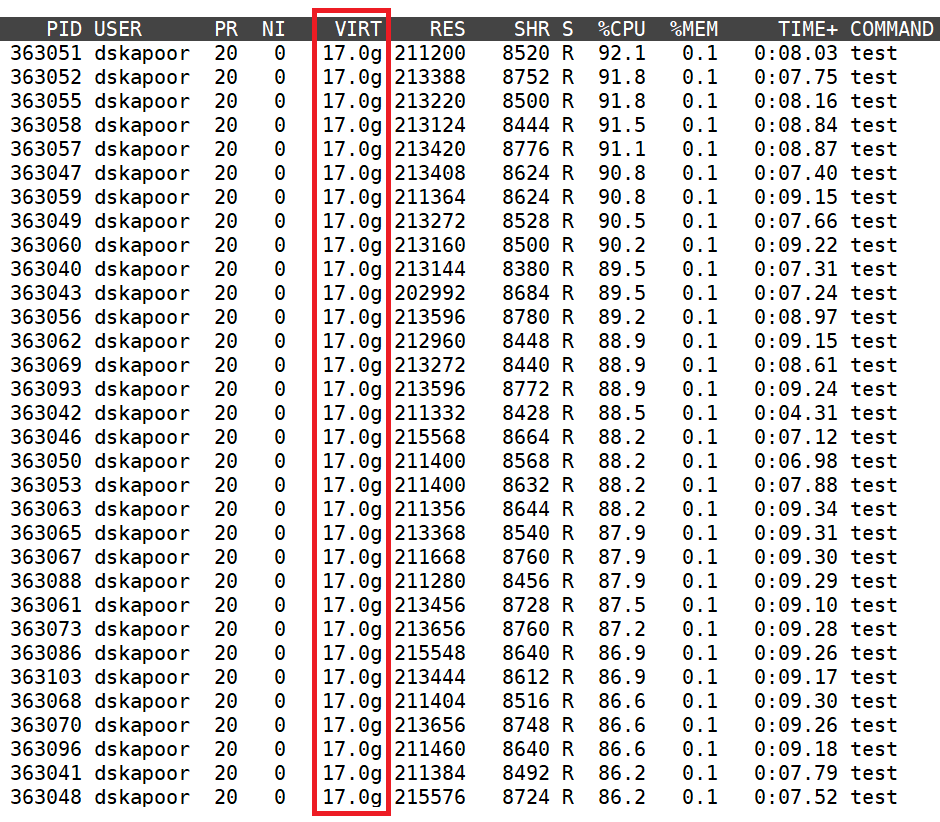
Figure 1: Top output from one of the nodes showing incorrect virtual memory consumption data
Recommendation
Here, we present a method to correctly measure the virtual memory consumption of the Intel MPI Library using /proc/<PID>/smaps files, which in modern Linux distributions provide very detailed information about a process’s memory consumption. Interested users and implementors of memory measuring tools may take note of this.
These smaps files are transient and only exist during the lifetime of the corresponding PID. As a result, we invoke our test application like before and note a few PIDs. Here we consider one of the PIDs (363051) and invoke the following command:
$ cat /proc/363051/smaps
This command results in a long output (16,698 lines). However, we are only interested in a handful of those lines containing the string /dev/shm/Intel_MPI_<postfix>, as shown in Figure 2.
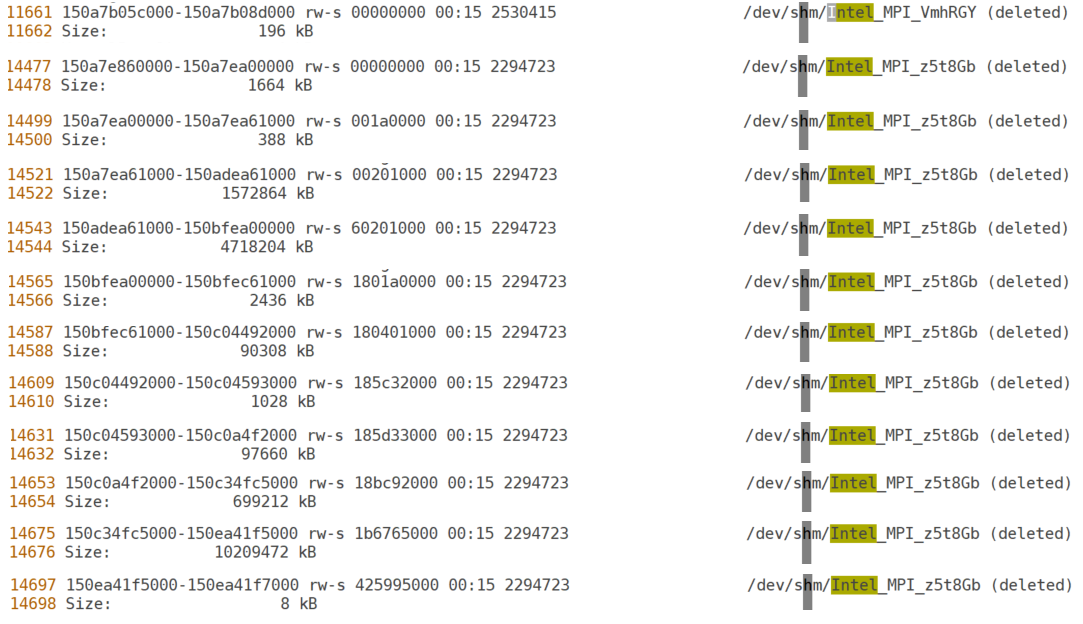
Figure 2: Snippets of interest from the /proc/363051/smaps file
Adding all the sizes corresponding to the Intel MPI Library from the above figure result in a total virtual memory consumption of (196 + 1664 + 388 + 1572864 + 4718204 + 2436 + 90308 + 1028 + 97660 + 699212 + 10209472 + 8) KB = 17,393,440 KB = 16.58 GB per node.
Repeating this procedure for other PIDs yields the same consumption of 16.58 GB per node. You will also notice the same filenames (/dev/shm/Intel_MPI_<postfix>) for each PID, which indicates that the same memory region is mapped to all the ranks.
The top utility wrongly reported a virtual memory consumption of 17 GB per rank, which we have clarified to be 17 GB per node. However, our procedure based on smaps resulted in a slightly lower virtual memory consumption of 16.58 GB per node (or 176.85 MB per rank). This difference comes from the fact that while using the smaps file we were counting virtual memory consumption of the Intel MPI Library alone, while top was reporting virtual memory consumption of both the application and the Intel MPI Library.