Introduction
With the development of new storage technologies and accompanying expectations of higher performance, the industry has begun to look at migration toward memory channels for possibilities.
A new direction in storage technology that offers expectations of higher performance is the non-volatile dual in-line memory module (NVDIMM).
NVDIMM is memory that is nonvolatile and allows for random access. Nonvolatile means that data is kept even without power, so during unexpected power loss, system crashes, and normal shutdowns we will not experience data loss. At the same time, NVDIMM uses a dual in-line memory module (DIMM) package compatible with a standard DIMM slot, and communicates through a standard double data rate (DDR) bus. Considering the fact that it is nonvolatile and compatible with a traditional dynamic random-access memory (DRAM) interface, it is also called persistent memory (PMEM).
Types
According to the definition provided by the standardization body JEDEC, there are at present three types of NVDIMM, which are described as follows.
NVDIMM-N
NVDIMM-N includes flash memory and traditional DRAM in one module, to which computers have direct access, and supports both byte and block addressing. Following an unexpected power loss, the NVDIMM-N backup power source can provide sufficient power to copy data from DRAM to flash memory, and when power is restored the data can be reloaded into DRAM.
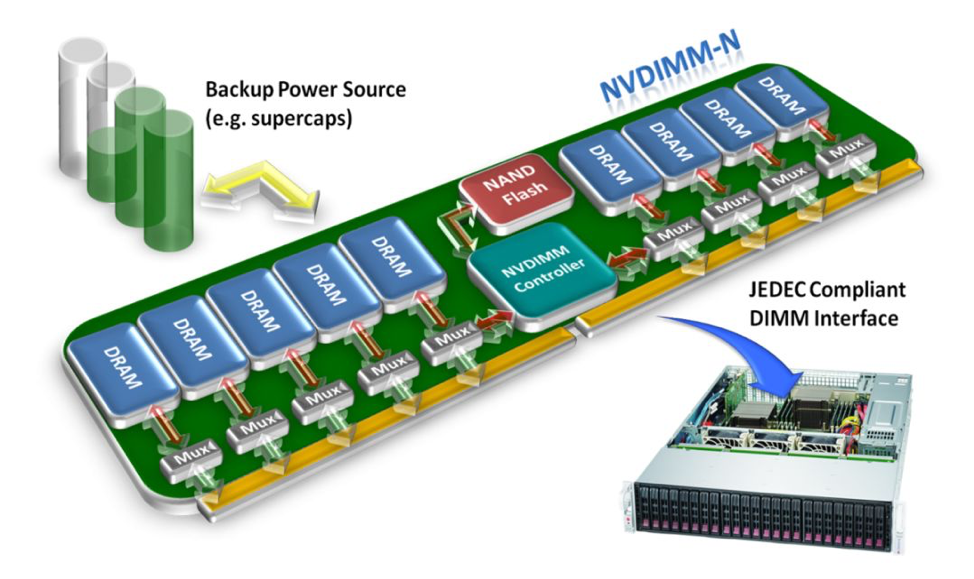
Figure 1. An NVDIMM-N.
In fact, NVDIMM-N primarily works like traditional DRAM, and that is why its delay also happens at the level of 10-8 seconds. As for its capacity, constrained by size, NVDIMM-N sees limited improvement over traditional DRAM.
One drawback is that the NVDIMM-N flash is not addressable, and another is that the use of two media types greatly increases its cost. However, NVDIMM-N has impressed the industry with its new concept of persistent memory. Currently, there are many NVDIMM-N based products on the market.
NVDIMM-F
NVDIMM-F is flash memory and uses the DDR3 or DDR4 bus of DRAM while, as we know, a solid-state drive (SSD) with NAND flash as a medium generally uses Serial Advanced Technology Attachment (SATA), Serial Attached SCSI (SAS), or PCIe* bus. The use of the DDR bus can improve the maximum bandwidth and reduce to a certain extent the delay and cost caused by the protocol, but it only supports block addressing.
NVDIMM-F works essentially the same as an SSD, and that is why its delay is at the level of 10-5 seconds. Its capacity can easily expand to terabytes (TB).
NVDIMM-P
The standard related to this type is currently under development. It is expected to come out together with the DDR5 standard. According to the release plan, DDR5 will provide a bandwidth that is twice that of DDR4, and improves the channel efficiency. For NVDIMM-P, these expected improvements, combined with its user-friendly interfaces for server and client platforms, enables high-performance and improved power management in applications.
NVDIMM-P combines the features of DRAM and flash, supporting both block addressing and traditional DRAM-like byte addressing, with a possible terabyte capacity, like NAND flash. In addition, it can keep the delay within the level of 10-7 seconds.
With data media connected straight to the memory bus, a CPU can access the data directly, without drive or PCIe latency. At the same time, instead of requiring block access, the CPU can access only the data it needs because memory access is through a cache line of 64 bytes.
Intel Corporation released Intel® Optane™ DC persistent memory in April 2019. It can be seen as an instance of an NVDIMM-P implementation.

Figure 2. Intel® Optane™ DC persistent memory.
Hardware Support
Applications can directly access NVDIMM-P in the same way they access traditional DRAM, which also saves the need for page swapping between traditional block devices and memory. However, writing data to persistent memory and writing data to ordinary DRAM shares computer resources including processor buffers, L1/L2 cache, and so on.
It should be noted that in order to make the data persistent, the data should be written to the persistent memory device or the buffer with power loss protection. If software wants to make full use of the features of persistent memory, the instruction set architecture needs to support at least the following features.
Atomicity of Writing
Atomicity means that writes of any size to persistent memory should be atomic because this can prevent erroneous data or duplicative writing caused by a system crash or unexpected power loss. IA-32 (IA32) and IA-64 (IA64) processors can guarantee atomic writing of data access (aligned or unaligned) to cache data up to 64 bits; therefore, software can safely update data in persistent memory. This also improves performance, for it avoids the use of copy-on-write or write-ahead-logging, which is used to ensure write atomicity.
Efficient Cache Flushing
For performance reasons, the data in persistent memory must be put into the processor cache before being accessed. An optimized cache flushing instruction can reduce flushing's (CLFLUSH) impact on performance.
CLFLUSHOPT provides more efficient cache flush instructions.
The cache line write back (CLWB) instruction writes the data that are altered on the cache line back to memory (similar to CLFLUSHOPT), with no need to turn this cache line to invalid (MESI protocol), but instead into the unaltered Exclusive state. CLWB is actually trying to reduce the inevitable cache miss in the next access due to the flushing of certain cache lines.
Committing to Persistence
Within the architecture of modern computers, upon the completion of cache flushing, the modified data is written back to the write buffer of the memory subsystem. However, under this circumstance, the data is not persistent. To ensure that data is written to persistent memory, software needs to flush volatile write buffers or other caches in the memory subsystem. The commit instruction, PCOMMIT, for persistent writes can commit the data in the write queue of the memory subsystem to persistent memory.
(Notes: Platforms that support Intel® Optane™ DC persistent memory are also required to support Asynchronous DRAM Refresh (ADR). This feature guarantees data persistence during power-fail or shutdowns by flushing the Write Pending Queue (WPQ ) in the memory controller automatically, eliminating the need for PCOMMIT. For more information, please refer to Deprecating the PCOMMIT Instruction)
Non-temporal Store Optimization
When software needs to copy a large amount of data from ordinary memory to persistent memory (or between persistent memories), weak order, non-temporary store operation (for example, MOVNTI) instructions are available options. Because non-temporal store instructions can implicitly invalidate the cache line to be written back, software does not need to explicitly flush the cache line (see Section 10.4.6.2. of the Intel® 64 and IA-32 Architectures Software Developer’s Manual, Volume 1).
The above introduces several ways of implementing NVDIMM, as well as the hardware optimization and support, to give full play to the performance of NVDIMM-P. The following section is about software support, including programming model, programming library, Storage Performance Development Kit (SPDK) support, and so on.
Software Support
This section is about the support software can provide to fully enable NVDIMM features. Some might wonder why NVDIMM does not appear as convenient as the name suggests; for persistent memory is still far away from the ideal usage scenario of restarting a computer with everything remaining the same as it was when last shut down. In fact, this will still be difficult to achieve in the near future because, on top of DRAM for example, cache and registers remain volatile. Persistent memory alone cannot make everything persistent. There is another problem: memory leaks. If a memory leak happens, a restart will clear volatile memory, but what about a persistent memory leak? This is a tough situation. PMEM is similar to memory in some respects and to storage in others; however, generally, we do not take PMEM as something able to replace memory or storage. In fact, it can be regarded as a supplement to fill the huge gap between memory and storage.
SPDK has included support PMEM since the 17.10 release. PMEM is exposed as a block device in the bdev layer of the SPDK and communicates with the upper layer through a block device interface, as shown in Figure 3.
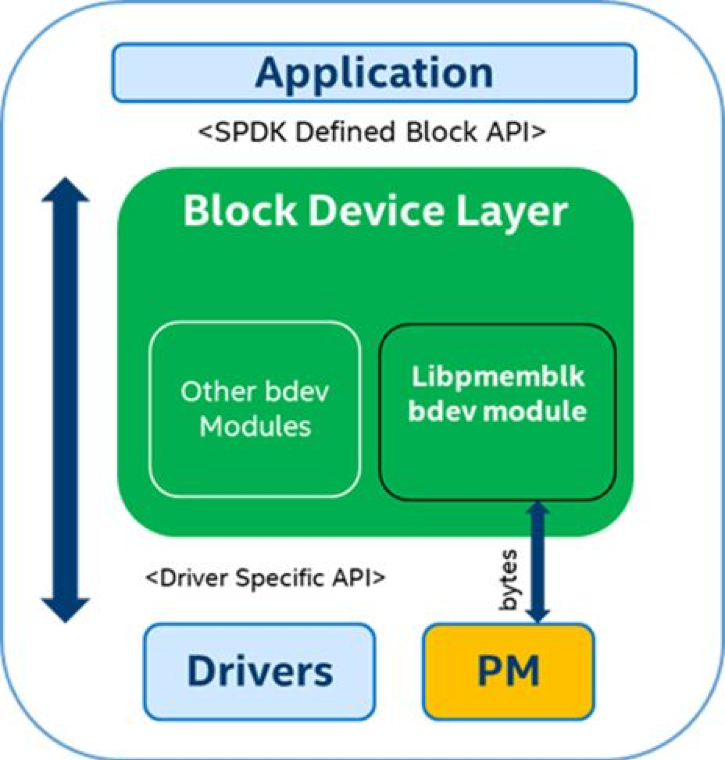
Figure 3. PMEM support in SPDK.
From the figure, we can see that libpmemblk turns a block operation into a byte operation, but how does it achieve this? Let us take a look at the basics before delving into libpmemblk and the underlying Persistent Memory Development Kit (PMDK).
Mmap and DAX
Let us first take a look at traditional I/O; that is, buffered I/O. Most operating systems use cache I/O by default, which allows I/O data to be cached in the operating system page cache, meaning that data is first copied to the operating system kernel space buffer and from there to the specified user address space.
// A Programmer’s view (not just C programmers!)
fd = open(”/my/file”, O_RDWR);
…
count = read(fd, buf, bufsize);
…
count = write(fd, buf, bufsize);
…
close(fd);
// “Buffer-Based”
In Linux*, this file access technique is realized through read/write system calls, as shown in Figure 4. Next, in contrast, we see how memory mapped I/O mmap () works.
// A Programmer’s view (mapped files)
fd = open(”/my/file”, O_RDWR);
…
base = mmap(NULL, filesize, PROT_READ|PROT_WRITE,
MAP_SHARED, fd, 0);
close(fd);
…
base[100] = ’X’;
strcpy(base, ”hello there”);
*structp = *base_structp;
…
// “Load/Store”
We can get a pointer to the corresponding file through mmap, and then assign a value or execute memcpy/strcpy just as how we operate in memory. We call this process a load/store operation, and it generally requires calls to msync and fsync to persist data.
What mmap does can be regarded as directly copying files to user space, saving one copy of data because it establishes mapping between files and user space. However, mmap still relies on page cache.
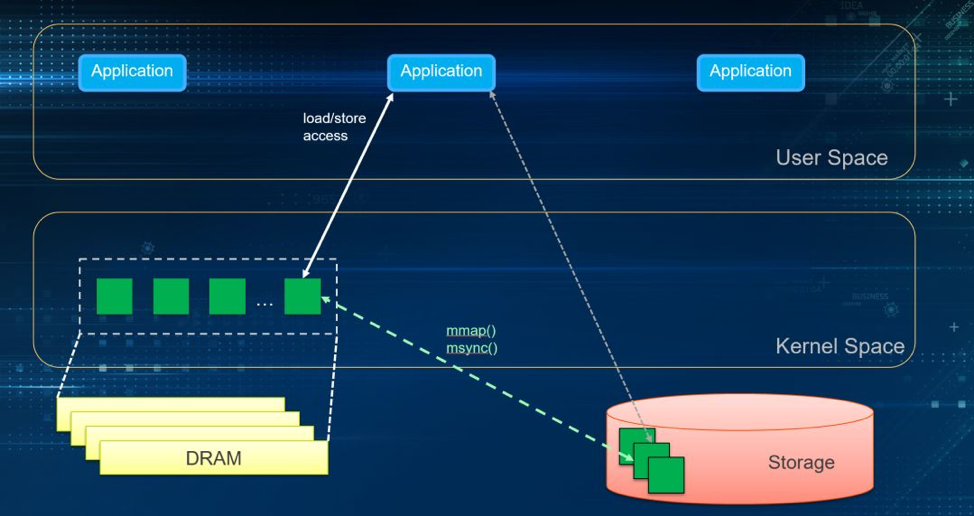
Figure 4. Load/store still needing page cache.
Now, what is DAX? DAX, meaning direct access, is a mmap-based feature. But it is different from mmap in its complete independence from the page cache and its direct access to storage devices. That makes it a good fit for NVDIMM. The application's file operations on mmap are directly synchronized to NVDIMM. DAX is now supported on XFS, EXT4, and Windows* NTFS, but its use requires some modification on the application or file system.
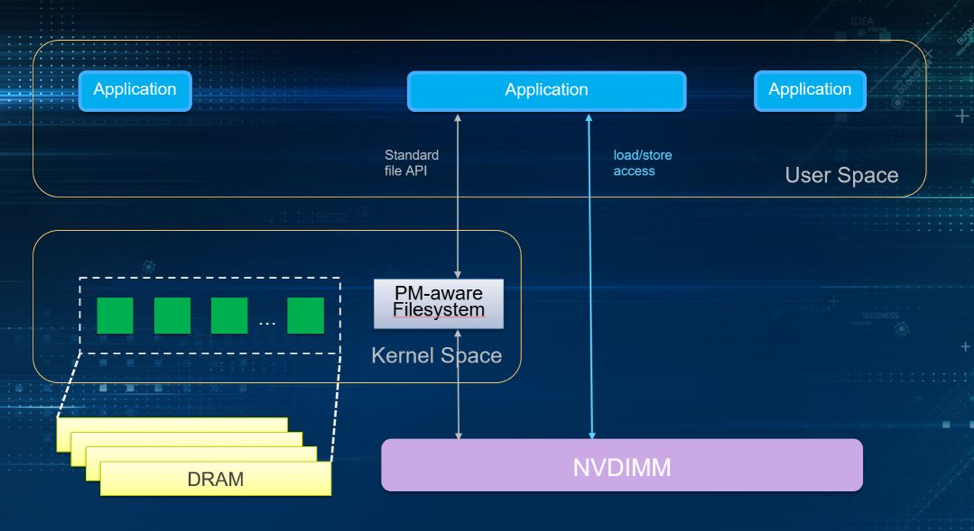
Figure 5. DAX.
NVM Programming Model
The non-volatile memory (NVM) Programming Model roughly defines three ways to use persistent memory.
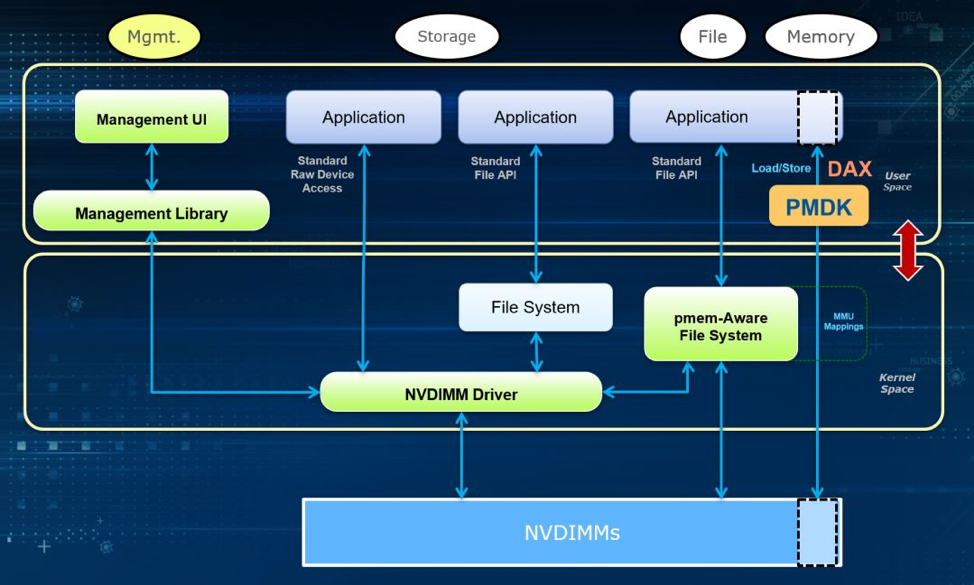
Figure 6. NVM Programming Model.
- Management, as shown on the left of Figure 6, mainly manages NVDIMMs through an API provided by the driver, such as capacity checks, health status, firmware version, firmware upgrade, mode configuration, and so on.
- The middle part of Figure 6 shows usage as a storage block device. The file system and kernel that support the NVDIMM driver are used. The application program does not need to make any modifications and accesses NVDIMM through a standard file interface.
- The third way to use it is based on the DAX features of the file system; it operates through load/store, and synchronously persists data with no need for a page cache. Moreover, there are no system calls or interrupts involved. These feature the core of the NVM Programming Model, maximizing NVIDMM’s potential features. But the downside is that the application may need to make some changes.
Persistent Memory Development Kit (PMDK)
libpmemblk implements an array of blocks of the same size residing in persistent memory. Each block in it remains atomic transactionality for sudden power loss, program crashes, and so on. It is based on the libpmem library.
libpmem is a low level library provided by the PMDK, for flushing and persisting data in NVDIMM. It can track every store operation on PMEM and ensure that the data is made persistent.
In addition, PMDK also provides other programming libraries, such as libpmemobj, libpmemlog, libvmmalloc, and so on. Please visit pmem.io for more information.
Real Use in SPDK–Bdevperf Test
bdevperf is a tool provided in SPDK for performance evaluation. Users can enable various kinds of block device in SPDK bdev layer and run bdevperf test.
STEP 1. Create a PMEM bdev
Clone or download a repo and step in to the directory of SPDK.
./configure --with-pmdk
make
PMDK has been included in some newly released versions of Linux. If there happen to be errors in configuration, visit the GitHub* site to install the PMDK library.
First, we need to run an SPDK target. SPDK provides several targets for different usage, for example, ISCSI target, NVMF target, vhost target, etc. Here we run a simple target spdk_tgt only for receiving and parsing RPC commands:
./app/spdk_tgt/spdk_tgt
Next, we can create a pmem_pool through the SPDK RPC command:
rpc.py create_pmem_pool /path/to/pmem_pool (MB) > <BlockSize>
If we do not have a real NVDIMM to test here, we can just choose a random path of pmem_pool (for simulation); for example:
rpc.py create_pmem_pool /mnt/pmem 128 4096
If you have Intel Optane DC persistent memory in the system, you can refer to the Quick Start Guide: Configure Intel® Optane™ DC Persistent Memory on Linux* for configuration. After configuration, just use the mount directory as the path of pmem_pool.
We can also use pmem_pool_info to obtain information needed to create a pmem_pool:
rpc.py pmem_pool_info /path/to/pmem_pool
Or, we can delete the pmem_pool just created:
rpc.py delete_pmem_pool /path/to/pmem_pool
Then, we set up a bdev block device on the pmem_pool we created:
rpc.py construct_pmem_bdev /path/to/pmem_pool -n pmem_bdev_name
Step 2. Update the Configuration File
Change path to spdk/test/bdev/bdev.conf.in, and only keep part of the PMEM configuration.
[Pmem]
Blk <pmemblk pool file name> <bdev name>
For example:
[Pmem]
Blk /mnt/pmem-pool pmem-bdev
Step 3. bdevperf Test
./bdevperf -c ../bdev.conf.in -q <iodepth> -t <time> -w <io pattern type: write|read|randwrite|randread>-o <io size in bytes>
Example command:
./bdevperf -c ../bdev.conf.in -q 128 -t 100 -w write -o 4096
./bdevperf -c ../bdev.conf.in -q 128 -t 100 -w write -o 4096
Conclusion
In this article, we’ve described the differences between hardware and software for NVDIMM as storage. Intel Corporation released Intel® Optane™ DC persistent memory in April of 2019, making NVDIMM the focus of the industry.
References
Intel® Architecture Instruction Set Extensions Programming Reference
Joint Electron Tube Engineering Council (JETEC) technology focus area on Main Memory: DDR4 & DDR5 SDRAM
Operating Modes of Intel® Optane™ DC Persistent Memory
Intel® Optane™ Memory: Two Confusing Modes Part 4: Comparing the Modes - The SSD Guy
About the Author
Chunyang Hui, a software engineer at Intel, is mainly engaged in SPDK development and performance optimization of storage software.
© 2019 Intel Corporation