This article describes the new Data Plane Development Kit (DPDK) API for traffic management (TM) that was introduced in DPDK release 17.08. This API provides a generic interface for Quality of Service (QoS) TM configuration, which is a standard set of features provided by network interface cards (NIC), network processing units (NPU), application-specific integrated circuits (ASIC), field-programmable gate arrays (FPGA), multicore CPUs, and so on. TM includes features such as hierarchical scheduling, traffic shaping, congestion management, packet marking, and so on.
This API is generic, as it is agnostic of the underlying hardware, software, or mixed HW/SW implementation. It is exposed as an extension for the DPDK ethdev API, similar to the flow API. A typical DPDK function call sequence is included to demonstrate implementation.
Main Features
Hierarchical Scheduling
The TM API allows users to select strict priority (SP) and weighted fair queuing (WFQ) for the hierarchical nodes subject to specific implementation support being available. The SP and WFQ algorithms are available at the level of each node of the scheduling hierarchy, regardless of the node level/position in the tree. The SP algorithm is used to schedule between sibling nodes with different priority, while WFQ is used to schedule between groups of siblings that have the same priority.
Example: As shown in Figure 1, the root node (node 0) has three child nodes with different priorities. Hence, the root node will schedule the child nodes using the SP algorithm based on their priority, with zero (0) as the highest priority. Node 1 has three child nodes with IDs 11, 12, and 13, and all the child nodes have the same priority (that is, priority 0). Thus, they will be scheduled using the WFQ mechanism by node 1. The WFQ weight of a given child node is relative to the sum of the weights of all its sibling nodes that have the same priority, with one (1) as the lowest weight.
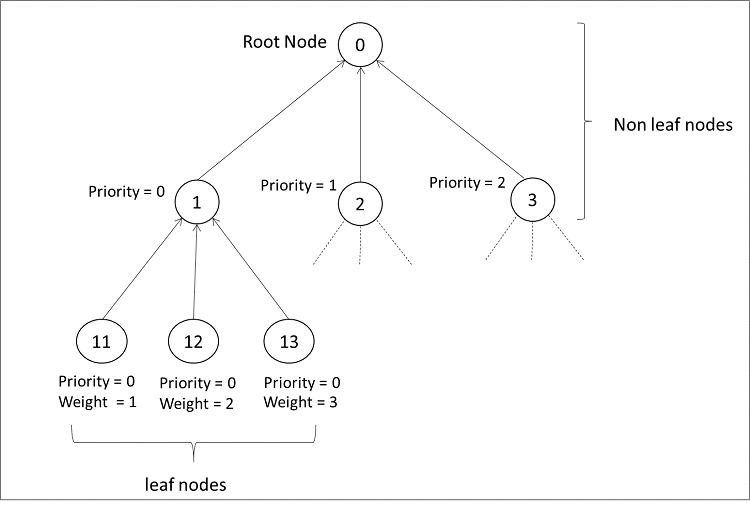
Figure 1: Hierarchical QoS scheduler.
Traffic Shaping
The TM API provides support for selecting single-rate and dual-rate shapers (rate limiters) for the hierarchy nodes, subject to the specific implementation support available. Each hierarchy node has zero or one private shaper (only one node using it) and/or zero, one, or several shared shapers (multiple nodes use the same shaper instance). A private shaper is used to perform traffic shaping for a single node, while a shared shaper is used to perform traffic shaping for a group of nodes. The configuration of private and shared shapers for a specific hierarchy node is done through the definition of shaper profile, as shown below:
/**
* Shaper (rate limiter) profile
*/
struct rte_tm_shaper_params {
/** Committed token bucket */
.committed = {
/* bucket rate (bytes per second) */
.rate = 0,
.size = TOKEN_BUCKET_SIZE
},
/** Peak token bucket */
.peak = {
.rate = TM_NODE_SHAPER_RATE,
.size = TOKEN_BUCKET_SIZE
},
/** framing overhead bytes */
.pkt_length_adjust = RTE_TM_ETH_FRAMING_OVERHEAD_FCS,
};
Figure 2: Shaper profile parameters.
As shown in Figure 1, each non-leaf node has multiple inputs (its child nodes) and single output (which is input to its parent node). Thus, non-leaf nodes arbitrate their inputs using scheduling algorithms (for example, SP, WFQ, and so on) to schedule input packets to its output while observing the shaping (rate limiting) constraints.
Congestion Management
The congestion management algorithms that can be selected through the API are Tail Drop, Head Drop and Weighted Random Early Detection (WRED). They are made available for every leaf node in the hierarchy, subject to the specific implementation supporting them.
During congestion, the Tail Drop algorithm drops the new packet while leaving the queue unmodified, as opposed to the Head Drop algorithm, which drops the packet at the head of the queue (the oldest packet waiting in the queue).
The Random Early Detection (RED) algorithm works by proactively dropping more and more input packets as the queue occupancy builds up. Each hierarchy leaf node with WRED enabled as its congestion management mode has zero or one private WRED context (only one leaf node using it) and/or zero, one, or several shared WRED contexts (multiple leaf nodes use the same WRED context). A private WRED context is used to perform congestion management for a single leaf node, while a shared WRED context is used to perform congestion management for a group of leaf nodes. The configuration of WRED private and shared contexts for a specific leaf node is done through the definition of WRED profile as shown below:
/**
* Weighted RED (WRED) profile
*/
struct struct rte_tm_wred_params {
/* RED parameters */
.red_params = {
[RTE_TM_GREEN] = {.min_th = 48, .max_th = 64, .maxp_inv = 10, .wq_log2 = 9},
[RTE_TM_YELLOW] = {.min_th = 40, .max_th = 64, .maxp_inv = 10, .wq_log2 = 9},
[RTE_TM_RED] = {.min_th = 32, .max_th = 64, .maxp_inv = 10, .wq_log2 = 9}
},
};
Figure 3: WRED profile parameters.
Packet Marking
The TM APIs are provided to support various types of packet marking such as virtual local area network drop eligible indicator (VLAN DEI) packet marking (IEEE 802.1Q), IPv4/IPv6 explicit congestion notification marking of TCP and Stream Control Transmission Protocol packets (IETF RFC 3168), and IPv4/IPv6 differentiated services code point packet marking (IETF RFC 2597).
Capability API
The TM API allows users to query the capability information (that is, critical parameter values) that the traffic management implementation (HW/SW) is able to support for the application. The information can be obtained at port level, at a specific hierarchical level, and at a specific node of the hierarchical level.
Steps to Set Up the Hierarchy
Initial Hierarchy Specification
The scheduler hierarchy is specified by incrementally adding nodes to build up the scheduling tree. The scheduling tree consists of leaf nodes and non-leaf nodes.
Each leaf node sits on top of a scheduling queue of the current Ethernet port. Therefore, the leaf nodes have predefined IDs in the range of 0... (N–1), where N is the number of scheduling queues of the current Ethernet port. The non-leaf nodes have their IDs generated by the application outside of the above range, which is reserved for leaf nodes. The unique ID that is assigned to each node when the node is created is further used to update the node configuration or to connect child nodes to it.
The first node that is added to the hierarchy becomes the root node (node 0, Figure 1), and all the nodes that are subsequently added have to be added as descendants of the root node. The parent of the root node has to be specified as RTE_TM_NODE_ID_NULL, and there can only be one node with this parent ID (that is, the root node).
During this phase, some limited checks on the hierarchy specification are conducted, usually limited in scope to the current node, its parent node, and its sibling nodes. At this time, since the hierarchy is not fully defined, there is typically no real action performed by the underlying implementation.
Hierarchy Commit
The hierarchy commit API is called during the port initialization phase (before the Ethernet port is started) to freeze the start-up hierarchy. This function typically performs the following steps:
* It validates the start-up hierarchy that was previously defined for the current port through successive node add API invocations.
* Assuming successful validation, it performs all the necessary implementation-specific operations to install the specified hierarchy on the current port, with immediate effect once the port is started.
Run-Time Hierarchy Updates
The TM API provides support for on-the-fly changes to the scheduling hierarchy; thus, operations such as node add/delete, node suspend/resume, parent node update, and so on can be invoked after the Ethernet port has been started, subject to the specific implementation supporting them. The set of dynamic updates supported by the implementation is advertised through the port capability set.
Typical DPDK Function Call Sequence
Ethernet Device Configuration
/* Device Configuration */
int status = rte_eth_dev_configure (PORT_ID, N_RXQs, N_TXQs, port_conf);
CHECK ((status != 0), "port init error") ;
/* Init TXQs*/
for (j = 0 ; j < N_TXQs ; j++) {
status = rte_eth_tx_queue_setup (PORT_ID, TX_QUEUE_ID, N_TX_DESC, SOCKET_ID, TX_CONF);
CHECK ((status != 0), "txq init error") ;
}
Create and Add Shaper Profiles
/* Define shaper profile parameters for hierarchical nodes */
struct rte_tm_shaper_params {
.committed = {.rate = COMMITTED_TB_RATE, .size = COMMITTED_TB_SIZE,},
.peak = {.rate = PEAK_TB_RATE, .size = PEAK_TB_SIZE,},
.pkt_length_adjust = PACKET_LENGTH_ADJUSTMENT,
};
/* Create shaper profile */
status = rte_tm_shaper_profile_add (PORT_ID, SHAPER_PROFILE_ID, ¶ms, &error);
CHECK ((status != 0), "Shaper profile add error") ;
/* Create shared shaper (if desired) */
status = rte_tm_shared_shaper_add_update(PORT_ID, SHARED_SHAPER_ID,
SHAPER_PROFILE_ID, &error);
CHECK ((status != 0), "Shaper profile add error") ;
Create the Initial Scheduler Hierarchy
/* Level 1: Port */
struct rte_tm_node_params port_params {
.shaper_profile_id = SHAPER_PROFILE_ID_PORT,
.shared_shaper_id = NULL,
.n_shared_shapers = 0,
.nonleaf = {
. wfq_weight_mode = NULL,
.n_sp_priorities = 0,
},
.stats_mask = TM_NODE_STATS_MASK;
};
status = rte_tm_node_add (PORT_ID, NODE_ID_PORT, RTE_TM_NODE_ID_NULL, 0, 1, NODE_PORT_LEVEL, &port_params, &error);
CHECK ((status != 0), "root node add error") ;
/* Level 2 : Subport */
for (i = 0 ; i < N_SUBPORT_NODES_PER_PORT ; i++) {
struct rte_tm_node_params subport_params {
.shaper_profile_id = SHAPER_PROFILE_ID_SUBPORT(i),
.shared_shaper_id = NULL,
.n_shared_shapers = 0,
.nonleaf = {
. wfq_weight_mode = NULL,
.n_sp_priorities = 0,
},
.stats_mask = TM_NODE_STATS_MASK;
};
status = rte_tm_node_add (PORT_ID, NODE_ID_SUBPORT(i), NODE_ID_PORT, 0, 1, NODE_SUBPORT_LEVEL, &subport_params, &error);
CHECK ((status != 0), "subport node add error") ;
}
/* Level 3: Pipe */
for (i = 0, i < N_SUBPORT_NODES_PER_PORT; i++)
for (j = 0, j < N_PIPES_NODES_PER_SUBPORT; j++) {
struct rte_tm_node_params pipe_params {
.shaper_profile_id = SHAPER_PROFILE_ID_PIPE(i, j),
.shared_shaper_id = NULL,
.n_shared_shapers = 0,
.nonleaf = {
. wfq_weight_mode = NULL,
.n_sp_priorities = 0,
},
.stats_mask = TM_NODE_STATS_MASK;
};
status = rte_tm_node_add (PORT_ID, NODE_ID_PIPE(i, j), NODE_ID_SUBPORT(i), 0, 1, NODE_PIPE_LEVEL, &pipe_params, &error);
CHECK ((status != 0), "pipe node add error") ;
}
/* Level 4: Traffic Class */
for (i = 0, i < N_SUBPORT_NODES_PER_PORT; i++)
for (j = 0, j < N_PIPES_NODES_PER_SUBPORT; j++)
for (k = 0, k < N_TRAFFIC_CLASSES; k++) {
struct rte_tm_node_params tc_params {
.shaper_profile_id = SHAPER_PROFILE_ID_TC(i, j, k),
.shared_shaper_id = {SHARED_SHAPER_ID_SUBPORT_TC(i,k)},
.n_shared_shapers = 1,
.nonleaf = {
. wfq_weight_mode = NULL,
.n_sp_priorities = 0,
},
.stats_mask = TM_NODE_STATS_MASK;
};
status = rte_tm_node_add (PORT_ID, NODE_ID_PIPE_TC(i, j, k), NODE_ID_PIPE(i, j), 0, 1, NODE_TRAFFIC_CLASS_LEVEL, &tc_params, &error);
CHECK ((status != 0), "traffic class node add error") ;
}
/* Level 4: Queue */
for (i = 0, i < N_SUBPORT_NODES_PER_PORT; i++)
for (j = 0, j < N_PIPES_NODES_PER_SUBPORT; j++)
for (k = 0, k < N_TRAFFIC_CLASSES; k++)
for (q = 0, q < N_QUEUES_PER_TRAFFIC_CLASS; q++) {
struct rte_tm_node_params queue_params {
.shaper_profile_id = SHAPER_PROFILE_ID_TC(i, j, k, q),
.shared_shaper_id = NULL,
.n_shared_shapers = 0,
.leaf = {
. cman = RTE_TM_CMAN_TAIL_DROP,
},
.stats_mask = TM_NODE_STATS_MASK;
};
status = rte_tm_node_add (PORT_ID, NODE_ID_QUEUE(i, j, k, q), NODE_ID_PIPE_TC(i, j, k), 0, weights[q], NODE_QUEUE_LEVEL, &queue_params, &error);
CHECK ((status != 0), "queue node add error") ;
}
Freeze and Validate the Startup Hierarchy
status = rte_tm_hierarchy_commit(PORT_ID, clear_on_fail, &error);
CHECK ((status != 0), "traffic management hierarchy commit error") ;
Start the Ethernet Device
status = rte_eth_dev_start(PORT_ID);
CHECK ((status != 0), "device start error") ;
Summary
This article discusses the DPDK Traffic Management API that provides an abstraction layer for HW-based, SW-based, or mixed HW/SW-based traffic management implementations. The API is exposed as part of the DPDK ethdev framework. Furthermore, API usage is demonstrated by building and enabling the hierarchical scheduler on the Ethernet device.
Additional Information
Details on Traffic Management APIs can be found at the following links:
- DPDK Summit Video: DPDK Quality of Service (QoS) API
- Traffic Management APIs Definition
- Traffic Management API Implementation: Intel XL710 NIC , Intel 82599 NIC, SoftNIC
- Traffic Management API and QoS Hierarchical Scheduler: DPDK Programmer’s Guide
About the Authors
Jasvinder Singh is a Network Software Engineer with Intel. His work is primarily focused on development of data plane functions, libraries and drivers for DPDK.
Wenzhuo Lu is a Software Engineer for DPDK at Intel. He is a DPDK contributor and maintainer on dpdk.org.
Cristian Dumitrescu is a Software Architect for Data Plane at Intel. He is a DPDK contributor and maintainer on dpdk.org.