By Jianming Song
Introduction
As deep learning projects evolve from experimentation to production, there is increasing demand to serve deep learning models for large scale, real-time distributed inference. While there are many tools available for relevant tasks (such as model optimization, serving, cluster scheduling, workflow management, and so on), it is still a challenging process for many deep learning engineers and scientists to develop and deploy distributed inference workflow that can scale out to large clusters in a transparent fashion.
![]()
To address this challenge, we are happy to announce the release of Cluster Serving support in Analytics Zoo 0.7.0. Analytics Zoo Cluster Serving is a lightweight, distributed, real-time serving solution that supports a wide range of deep learning models, including TensorFlow*, PyTorch*, Caffe*, BigDL, and OpenVINO™ toolkit. It provides a simple publish-subscribe (pub/sub) API, through which users can easily send their inference requests to the input queue using a simple Python* API. Cluster Serving will then automatically manage the scale-out and real-time model inference across a large cluster, using distributed streaming frameworks such as Apache Spark* Streaming, Apache Flink*, and so on. The overall architecture of Analytics Zoo Cluster Serving is illustrated in Figure 1.
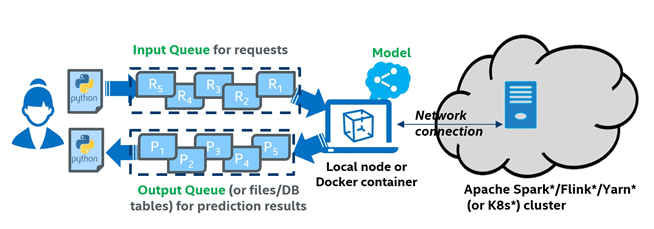
Figure 1. Analytics Zoo Cluster Serving solution.
How Cluster Serving Works
Follow the three simple steps below to use the Cluster Serving solution (as illustrated in Figure 2).
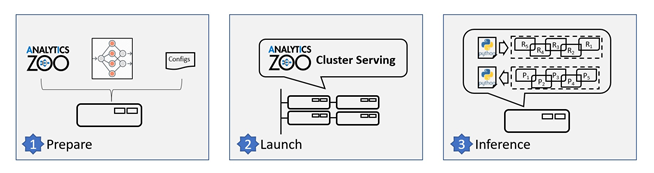
Figure 2. Steps to use the Analytics Zoo Cluster Serving solution.
- Install and prepare the Cluster Serving environment on a local node:
- Copy a previously trained model to the local node; currently, TensorFlow, PyTorch, Caffe, BigDL, and OpenVINO are supported.
- Install Analytics Zoo on the local node (for example, using a single pip install command).
- Configure Cluster Server on the local node, including the file path to the trained model and the address of the cluster (such as Apache Hadoop* YARN cluster, Spark cluster, Kubernetes* cluster, and so on).
Please note that you only need to deploy the Cluster Serving solution on a single local node, and no modifications are needed for the (YARN or K8s) cluster.
- Launch the Cluster Serving service
Launch the Cluster Serving service by running the startup script on the local node, such as:
cluster-serving-startUnder the hood, Cluster Serving will automatically deploy the trained model and serve the model inference requests across the cluster in a distributed fashion. You may monitor its runtime status (such as inference throughput) using TensorBoard*.
- Distributed, real-time (streaming) inference
Cluster Serving provides a simple pub/sub API that enables you to easily send the inference requests to an input queue (currently Redis* Streams is used) using a simple Python API, such as:
input = InputQueue() input.enqueue_image(id, image)Cluster Serving will then read the requests from the Redis Stream, run the distributed real-time inference across the cluster using Spark Streaming or Flink, and return the results back through Redis. Afterward, you can get the inference results again using a simple Python API, such as:
output = OutputQueue() results = output.dequeue()
A Quick Start Example
Try Cluster Serving by running the quick start example provided in the Analytics Zoo 0.70 release. It contains all the necessary components for running a distributed inference pipeline using Cluster Serving, enabling first-time users to get it up and running within minutes. The example includes:
- A docker image for Analytics Zoo Cluster Serving with all dependencies installed
- A sample configuration file
- A sample trained TensorFlow model and sample data for inference
- A sample Python client program
Follow the high-level steps below to run the quick start example. See the Analytics Zoo Cluster Serving Programming Guide for detailed instructions.
- Start the Analytics Zoo docker:
#docker run -itd --name cluster-serving --net=host intelanalytics/zoo-cluster-serving:0.7.0 bash - Log in to the container and go to our prepared working directory:
#docker exec -it cluster-serving bash #cd cluster-serving - Start the Cluster Serving inside the container:
#cluster-serving-start - Run the Python client program to start the inference:
#python3 quick_start.py
The following inference results should appear on your local console:
image: fish1.jpeg, classification-result: class: 1's prob: 0.9974158
image: cat1.jpeg, classification-result: class: 287's prob: 0.52377725
image: dog1.jpeg, classification-result: class: 207's prob: 0.9226527
If you want to build and deploy your own customized Cluster Serving pipeline, you can start by modifying the sample configuration and sample Python program provided in the quick start example. Following is a look at these sample files. See the Cluster Serving Programming Guide for details.
The configuration file (config.yaml) looks like the following:
## Analytics Zoo Cluster Serving Config Example
model:
# model path must be set
path: /opt/work/model
data:
# default, localhost:6379
src:
# default, 3,224,224
image_shape:
params:
# default, 4
batch_size:
# default, 1
top_n:
spark:
# default, local[*], change this to spark://, yarn, k8s:// etc.
# if you want to run on cluster
master: local[*]
# default, 4g
driver_memory:
# default, 1g
executor_memory:
# default, 1
num_executors:
# default, 4
executor_cores:
# default, 4
total_executor_cores:
The Python program looks like the following:
from zoo.serving.client import InputQueue, OutputQueue
import os
import cv2
import json
import time
if __name__ == "__main__":
input_api = InputQueue()
base_path = "../../test/zoo/resources/serving_quick_start"
if not base_path:
raise EOFError("You have to set your image path")
output_api = OutputQueue()
output_api.dequeue()
path = os.listdir(base_path)
for p in path:
if not p.endswith("jpeg"):
continue
img = cv2.imread(os.path.join(base_path, p))
img = cv2.resize(img, (224, 224))
input_api.enqueue_image(p, img)
time.sleep(5)
# get all results and dequeue
result = output_api.dequeue()
for k in result.keys():
output = "image: " + k + ", classification-result:"
tmp_dict = json.loads(result[k])
for class_idx in tmp_dict.keys():
output += "class: " + class_idx + "'s prob: " + tmp_dict[class_idx]
print(output)
Conclusion
We are excited to share this new Cluster Serving support in the latest Analytics Zoo 0.7.0 release, and hope this solution helps to simplify your distributed inference workflow and improve productivity. We would love to hear your questions and feedback on GitHub* and the mail list. Expect to hear more about Analytics Zoo as we continue to develop it as a unified data analytics and AI platform.