More than 90 percent of all data in the world was generated in the past few years—each day, the world creates more than 2.5 quintillion bytes of data, and the pace is accelerating. The need for AI-fused analytics development—to harness large data sets and extract useful insights at scale—has never been greater.

A New Way to Develop Distributed, Unified AI/Analytics at Scale
Implementing and productionizing traditional AI in today’s data-centric environment involves significant challenges; it requires modernization and innovative approaches to leverage AI’s full potential. For example, only a small fraction of AI productionization is devoted to learning or inference, while the infrastructure surrounding learning/inference is often vast and complex.
To simplify development and accelerate movement from lab and research environments to production at scale, AI needs to have an end-to-end data analytics pipeline. We have already started seeing new, innovative development approaches and trends in the convergence of analytics and AI on distributed, big data platforms.
In a typical advanced analytics solution, about 80 percent of the data pipeline focuses on ingesting, storing, cleaning, and pre-processing data, and about 20 percent of it focuses on AI training and inference. Big data platforms like Apache Spark* and Apache Hadoop* are extremely suitable for developing such end-to-end data pipelines. Enhancing Spark and Hadoop to better meet the challenges of AI-based advanced analytics is exactly why Intel open sourced BigDL, a distributed deep learning framework organically built for the Spark analytics pipeline.
BigDL delivers feature parity with deep learning frameworks like Caffe and Torch, and it drives Spark/Hadoop as the unified analytics pipeline for a consistent and integrated approach to data ingest, prep, machine learning, deep learning, deployment, and visualization.
As we deployed BigDL on Spark and Intel® Xeon® processor-based clusters, some customers expressed preferences for additional deep learning frameworks like TensorFlow* to do the training on Spark. In response, we introduced Analytics Zoo. Its biggest advantage is its support of several popular deep learning frameworks on big data Intel Xeon processor-based clusters.
In addition to TensorFlow, Analytics Zoo supports Keras, and BigDL frameworks, with more planned in the future. It also includes features that help developers build end-to-end analytics/deep learning pipelines that can scale-out on Spark/Hadoop clusters for distributed training and inference.
In addition to supporting popular deep learning frameworks on Intel Xeon processor-based Spark clusters, Analytics Zoo includes the following elements:
- Pre-trained deep learning models for image analysis, text processing, text matching, anomaly detection, and sequence prediction
- A high-level API for simpler application development
- Use cases and examples
- OpenVINO™ toolkit support to accelerate the inference speed for TensorFlow models
Moreover, Intel recently launched the second generation of Intel® Xeon® with built-in instructions to boost deep learning performance, and Intel® Optane™ DC Persistent Memory, a new type of memory that offers larger capacity and lower latency. These innovative technologies improve single node performance for key analytics/AI workloads, and further scale-out efficiency for analytics/AI systems.
We continue to optimize open source projects like Spark, Java*/Scala*, Python*, and SQL on the latest Intel® technologies to unify a production-grade platform that brings the AI and big data analytics ecosystems together. Most importantly, we work with enterprise, cloud, and high-performance computing (HPC) developers to help them more easily build unified analytics/AI pipeline solutions that deliver maximum value on Intel technologies supported by a powerful set of Intelsoftware tools, libraries, and developer resources.
Intel and Ecosystem Partners Showcase Innovative Solutions at Spark*+AI Summit
Scaled-out clusters using those hardware and software technologies can deliver faster insights from big data analytics across a broad range of use cases, including several showcased by Intel at Spark+AI Summit 2019 in San Francisco:
- Analytics Zoo and BigDL on Intel Xeon processor-based platforms deliver deep learning (DL) Spark pipelines at scale. CERN uses these technologies to run topology classification for improving real-time event selection at its Large Hadron collider. The solution showcases the value of DL on distributed Intel platforms as an alternative to customized rule-based methods in high-energy physics.
- Intel Optane DC Persistent Memory analytics optimizations maximize data analytics power with larger memory capacity and lower latency for faster insights from big data analytics. HBase runs 28x to 33x1 more transactions per second (TPS) compared to systems without the persistent memory modules, and Spark SQL on the Intel® Optimized Analytics Package (OAP) supports Intel Optane DC Persistent Memory to run up to 8x2 faster.
- DL training and inference runs on Spark at scale with Analytics Zoo and BigDL. The Dell EMC* Ready Solution for AI uses that software running on Intel Xeon processors to train a multi-class, multi-label model on X-ray images for AI-assisted radiology.
- Spark* deep learning developers use Intel® Software Tools—BigDL and Intel® Parallel Studio XE—to profile, analyze and optimize DL workloads with IntelVNNI, boosting inference performance. In addition, you can improve BigDL training efficiency with Intel Optane DC Persistent Memory.
- Analytics Zoo running on Intel Xeon processors and Intel Optane DC Persistent Memory enables streamlined, end-to-end development, deployment and operations to predict stock price behavior leveraging real-time sentiment analysis. GigaSpaces* Real-Time Insights to Action uses those technologies to deliver faster insights, with up to 3x3 the performance compared to using SSDs.
- Analytics Zoo with Intel® FPGA analytics pipeline-acceleration for Spark streaming at scale delivers real-time performance, low latencies, and high throughput across a range of video analytics use cases supported by Megh Computing* Video Analytics Acceleration.
Intel’s Spark+AI technical sessions include deep-dives into several innovations using Apache Spark on Intel-based platforms:
- Using BigDL and Analytics Zoo on Intel Xeon-based distributed clusters, CERN* easily applied end-to-end deep learning and analytics pipelines on Apache Spark at scale for High Energy Physics. The session, Deep learning on Apache Spark at CERN’s Large Hadron Collider with Intel technologies shares technical details and development learnings using an example of topology classification to improve real-time event selection at the Large Hadron Collider experiments.
- Intel Optane DC Persistent Memory disrupts the traditional memory/storage hierarchy and scales-up servers with higher-capacity persistent memory. It also delivers higher bandwidth and lower latency than SSD or HDD storage. These advantages can help mitigate the risk of increased TCO when scaling out a Spark cluster, as explained in the session, Accelerate Your Apache Spark with Intel Optane DC Persistent Memory.
- Developers can build an easy-to-use AI-based radiologist system to detect diseases from chest x-ray images using Apache Spark, BigDL and Analytics Zoo. The session, Using Deep Learning on Apache Spark to Diagnose Thoracic Pathology highlights a multi-label image classification model using a dataset released by the NIH that works with complex image transformations and deep learning pipelines to deliver scalability and ease of use.
- Spark developers can realize huge performance gains from Intel FPGAs and AI accelerators by designing the hardware and software stack to be dataframe-aware. The session, Apache Arrow*-Based Unified Data Sharing and Transferring Format presents ways developers use the ApacheArrow-based dataframe as a unified data sharing and transferring format to mitigate data transfer overhead between the JVM and the accelerator, and to provide information about how the accelerators are used in Spark.
- Using Intel® AI technologies with Apache Spark for game playing gives researchers and developers a good playground for experimenting with intelligent agents, as the goals and action rules of computer games are well-defined and abstract. The session, Game Playing Using AI on Apache Spark examines how deep neural networks allow visual information in games to be effectively processed and directly used for decision making by agents. The areas of deep reinforcement-learning and meta-learning are also explored.
- Using Analytics Zoo and BigDL, developers can build efficient, cloud-based document recommender systems, leveraging Natural Language Processing (NLP) and Deep Neural Networks (DNNs) at scale. The session, Leveraging NLP and Deep Learning for Document Recommendations in the Cloud presents how developers can use the end-to-end pipeline of Analytics Zoo to significantly improve the precision and performance of mean reciprocal ranking.
Join and contribute to the Analytics Zoo open source project, and visit the Intel® AI Developer Zone for related software tools, libraries framework optimizations, and other resources.
Related Content
Second Generation Intel Xeon Processor Scalable Family Technical Overview: The new processors’ features and enhancements and how developers can take advantage of them.
Intel Optane DC Persistent Memory: A new memory class in the latest generation of Intel Xeon Scalable processors rewrites the performance equation.
Analytics Zoo Overview: The features and benefits of Analytics Zoo, a unified analytics and AI open source software platform designed to simplify and accelerate AI solutions development using various framework models in Apache Spark.
Derive Value from Data Analytics and AI at Scale with Open Source Software and Intel® Platform Technologies: With open source software as a catalyst, Intel innovations in communications, storage/memory and computer processing can help your enterprise move faster, store more, and process everything.
 Ziya Ma is vice president of the Intel Architecture, Graphics and Software group and director of Data Analytics Technologies in System Software Products at Intel Corp. Ma is responsible for optimizing big data solutions on the Intel® architecture platform, leading open source efforts in the Apache community, and bringing about optimal big data analytics experiences for customers. Her team works across Intel, the open source community, industry, and academia to further Intel’s leadership in big data analytics. Ma is a co-founder of the Women in Big Data forum. At the 2018 Global Women Economic Forum, she was honored as Women of the Decade in Data and Analytics. Ma received her bachelor’s degree in computer engineering from Hefei University of Technology in China and a master’s degree and Ph.D. in computer science and engineering from Arizona State University.
Ziya Ma is vice president of the Intel Architecture, Graphics and Software group and director of Data Analytics Technologies in System Software Products at Intel Corp. Ma is responsible for optimizing big data solutions on the Intel® architecture platform, leading open source efforts in the Apache community, and bringing about optimal big data analytics experiences for customers. Her team works across Intel, the open source community, industry, and academia to further Intel’s leadership in big data analytics. Ma is a co-founder of the Women in Big Data forum. At the 2018 Global Women Economic Forum, she was honored as Women of the Decade in Data and Analytics. Ma received her bachelor’s degree in computer engineering from Hefei University of Technology in China and a master’s degree and Ph.D. in computer science and engineering from Arizona State University.
Optimization Notice
Intel's compilers may or may not optimize to the same degree for non-Intel microprocessors for optimizations that are not unique to Intel microprocessors. These optimizations include SSE2, SSE3, and SSE3 instruction sets and other optimizations. Intel does not guarantee the availability, functionality, or effectiveness of any optimization on microprocessors not manufactured by Intel.
Microprocessor-dependent optimizations in this product are intended for use with Intel microprocessors. Certain optimizations not specific to Intel microarchitecture are reserved for Intel microprocessors. Please refer to the applicable product User and Reference Guides for more information regarding the specific instruction sets covered by this notice.
Notice revision #20110804
1. HBase configuration, per Intel testing:
|
|
|
| Total Nodes |
1 client + N server(s) depending on test |
| Workload |
HBase Performance Evaluation Tool (PET) |
| Data |
HDFS DN on HBase RS instance, HDFS NN on client instance |
| Bucket cache size |
Dependent on test configuration |
| Number of threads |
100, 200 |
| Type of data access |
100% random read, no writes |
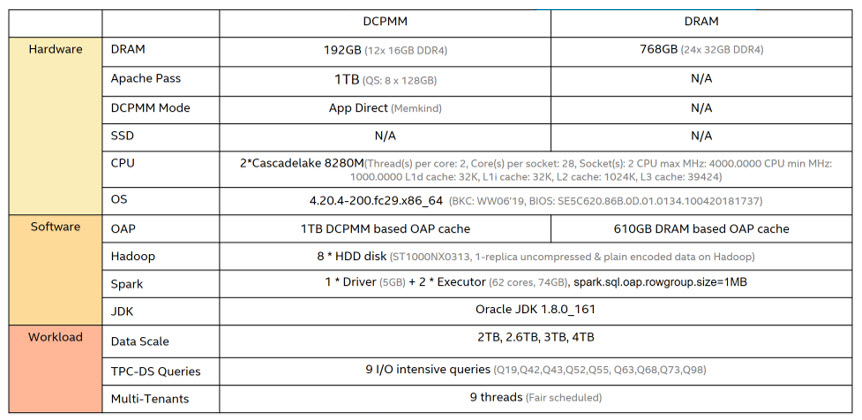
2. Spark SQL on Intel OAP configuration, per Intel testing:
3. As tested and reported by GigaSpaces.
Software and workloads used in performance tests may have been optimized for performance only on Intel microprocessors. Performance tests, such as SYSmark and MobileMark, are measured using specific computer systems, components, software, operations and functions. Any change to any of those factors may cause the results to vary. You should consult other information and performance tests to assist you in fully evaluating your contemplated purchases, including the performance of that product when combined with other products.
Intel does not control or audit the design or implementation of third-party benchmarks or Web sites referenced in this document. Intel encourages all of its customers to visit the referenced Web sites or others where similar performance benchmarks are reported and confirm whether the referenced benchmarks are accurate and reflect performance of systems available for purchase.
Relative performance is calculated by assigning a baseline value of 1.0 to one benchmark result, and then dividing the actual benchmark result for the baseline platform into each of the specific benchmark results of each of the other platforms and assigning them a relative performance number that correlates with the performance improvements reported. SPEC, SPECint, SPECfp, SPECrate. SPECpower, SPECjAppServer, SPECjbb, SPECjvm, SPECWeb, SPECompM, SPECompL, SPEC MPI, SPECjEnterprise* are trademarks of the Standard Performance Evaluation Corporation. See http://www.spec.org for more information. TPC-C*, TPC-H*, TPC-E* are trademarks of the Transaction Processing Council.
Hyper-Threading Technology requires a computer system with a processor supporting HT Technology and an HT Technology-enabled chipset, BIOS and operating system. Performance will vary depending on the specific hardware and software you use. For more information including details on which processors support Hyper Threading Technology.
Intel® Turbo Boost Technology requires a Platform with a processor with Intel Turbo Boost Technology capability. Intel Turbo Boost Technology performance varies depending on hardware, software and overall system configuration. Check with your platform manufacturer on whether your system delivers Intel Turbo Boost Technology. For more information, see http://www.intel.com/technology/turboboost
No computer system can provide absolute security. Requires an enabled Intel® processor and software optimized for use of the technology. Consult your system manufacturer and/or software vendor for more information.
Intel processor numbers are not a measure of performance. Processor numbers differentiate features within each processor family, not across different processor families.
Intel product plans in this presentation do not constitute Intel plan of record product roadmaps. Please contact your Intel representative to obtain Intel’s current plan of record product roadmaps.
Copyright © 2019 Intel Corporation. All rights reserved. Intel, the Intel logo, Xeon and Intel Core are trademarks or registered trademarks of Intel Corporation or its subsidiaries in the United States and other countries. All dates and products specified are for planning purposes only and are subject to change without notice.
*Other names and brands may be claimed as the property of others.