
Introduction
Deep learning applications are multiplying in many fields of science. The performance of these models is strictly related to the type of hardware and the deployment methods of AI software that can ease development, optimization, and training processes.
Cross-architecture computing is an important next-generation trend with the computing industry investing in dedicated hardware that promises to deliver impressive inference and training performance. Because of this proliferation of specialized hardware, a unified software development environment across CPU and accelerator architectures, such as oneAPI, could highly simplify models of development.
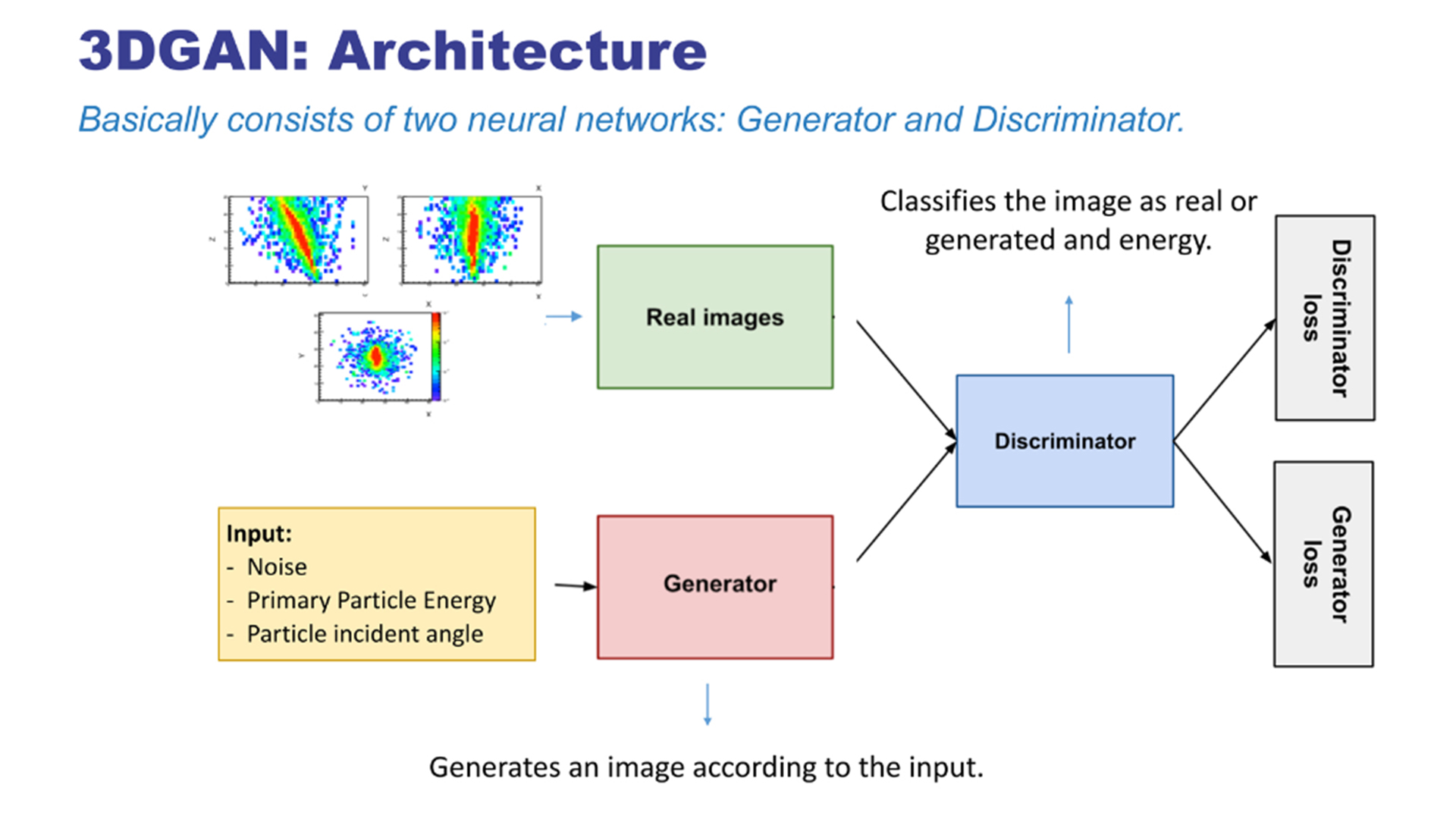
We tested oneAPI with a generative model called 3DGAN. It’s a convolutional generative adversarial network (GAN) aimed at simulating the response of a high-energy physics detector (calorimeters).
About oneAPI and Intel® DevCloud
So, how did we deploy the 3DGAN with oneAPI? First, we installed oneAPI and the Intel® AI Analytics Toolkit since we’re working with Python* and TensorFlow*. Other toolkits are available if you’re working with IoT, HPC, or anything else.
Next, we cloned one of the conda* environments provided by the AI toolkit and added the missing packages for our project. Finally, we ran the code using Keras* v2.0.0 and Intel® Optimization for TensorFlow* v1.15. The conda environment provided by the toolkit already comes with the optimized version of TensorFlow.
Results So Far
R&D projects carried out through CERN openlab are already working to tackle the ICT challenges posed by the High-Luminosity Large Hadron Collider (HL-LHC), which will come online toward the end of this decade. With the HL-LHC, experiments will require around a hundred times more simulated data than with the current LHC, helping them to probe rarer phenomena more accurately.
Our main objective is to be able to run the simulations across diverse hardware architectures, thus easing portability. To help achieve this objective, our current goal is to ease portability of DNN training and inference across different hardware. oneAPI simplifies this task, although our initial tests show that the DNN training process is slightly slower. Optimization will be dedicated to improve this aspect.
Conclusion
In a loose comparison between a CPU, an NVIDIA GPU, and a CPU with oneAPI, we found that oneAPI converges toward a better level of accuracy than a CPU without oneAPI. In a ratio comparison of data versus generated data, we found that oneAPI generates more accurate data.
Additional Resources
Project Details and Final Presentation
About Silke Donayre Holtz
Silke participated in the CERN openlab 2020 online Summer Internship Program. She is currently studying for a master degree in computer science at Karlsruhe Institute of Technology (KIT) and working in the field of data compression using deep neural networks. She previously worked at the Jicamarca Radio Observatory and in a biochemical laboratory at her former university, where she also earned a B.S. in Electronic Engineering. Two of her favorite activities are playing video games and singing. You can connect with her on LinkedIn.