Authors: Ryan Loney, Product Manager, OpenVINO™ model server, Intel; Dariusz Trawinski, Deep Learning Software Engineer, OpenVINO™ model server, Intel; Miłosz Żeglarski, Deep Learning Software Engineer, OpenVINO™ model server, Intel
Introduction
What is Model Serving?
To put it simply, model serving is taking a trained AI model and making it available to software components over a network API. To make life easier for our developers, OpenVINO™ toolkit offers a native method for exposing models over a gRPC or REST API. It’s called the OpenVINO™ model server (OVMS).
The OpenVINO™ model server enables quickly deploying models optimized by OpenVINO™ toolkit – either in OpenVINO™ toolkit Intermediate Representation (.bin & .xml) or ONNX \(.onnx) formats – into production. Pre-built container images are available for download on Docker Hub and the Red Hat Catalog. Optimized for minimal footprint, the CPU image is only 145MB compressed – an optimal size for edge or cloud deployments. The server is also optimized for performance. Implemented in C++, it offers high-throughput and low-latency when serving models.
Scaling with Kubernetes
Inferencing with OpenVINO™ model server can be scaled to thousands of nodes using multiple pod replicas in Kubernetes* or OpenShift* clusters. Kubernetes and OpenShift can run on most public clouds, or on-premises in a private cloud or edge deployment.
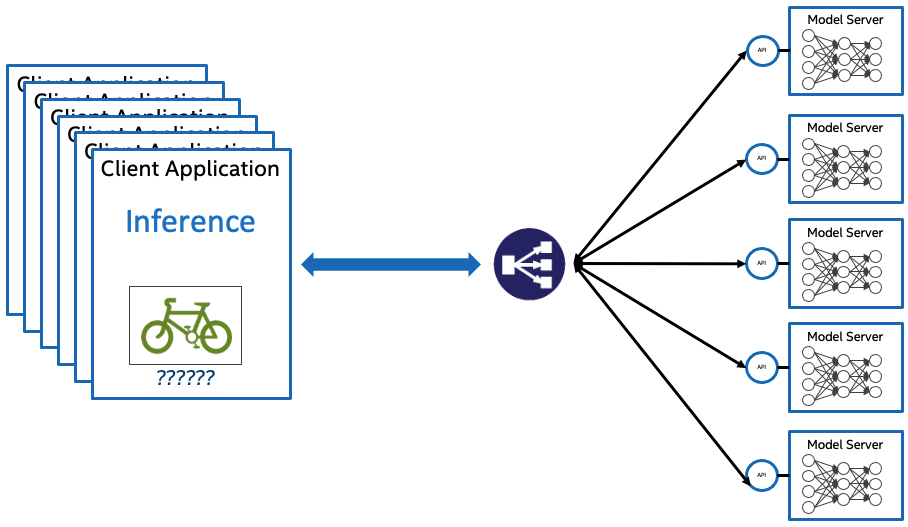
When developers deploy applications in a Kubernetes cluster, the typical application is deployed in a container. For AI applications, a model is usually developed by data scientists through a training process before being handed off to the application. The model can be directly embedded in a container with an application, or it can serve requests to applications over an API endpoint. OpenVINO™ toolkit supports either scenario.
In this blog, we will focus on how to serve models in Kubernetes and OpenShift clusters using OpenVINO™ model server. Both a Helm chart and Operator are available to simplify deployments.
Now let's see how!
Deploying in Kubernetes
Helm
Helm is a popular package manager for Kubernetes. Using our Helm chart, you can quickly deploy and manage many instances of OpenVINO™ model server.
A basic example of the deployment is described below:
git clone https://github.com/openvinotoolkit/model_server
cd model_server/deploy
helm install ovms-app ovms --set model_name=resnet50-binary-0001,model_path=
gs://ovms-public-eu/resnet50-binary
This will create a Kubernetes deployment and an associated service called `ovms-app`.
kubectl get pods
NAME READY STATUS RESTARTS AGE
ovms-app-5fd8d6b845-w87jl 1/1 Running 0 27s
Read more about our helm chart in the documentation.
Kubernetes Operator
An Operator is a framework used for managing applications that are deployed in a Kubernetes cluster. Operators simplify application management via Custom Resource Definition (CRD) resources by delegating knowledge about the configuration in Kubernetes to the Operator controller.
See the steps below to learn how the OpenVINO™ model server Operator is deployed in OpenShift and Kubernetes.
Deploy in OpenShift
We are proud to announce that the OpenVINO™ model server is now available on the Red Hat Catalog as a certified Operator. Find the Operator offering in the OpenShift console:
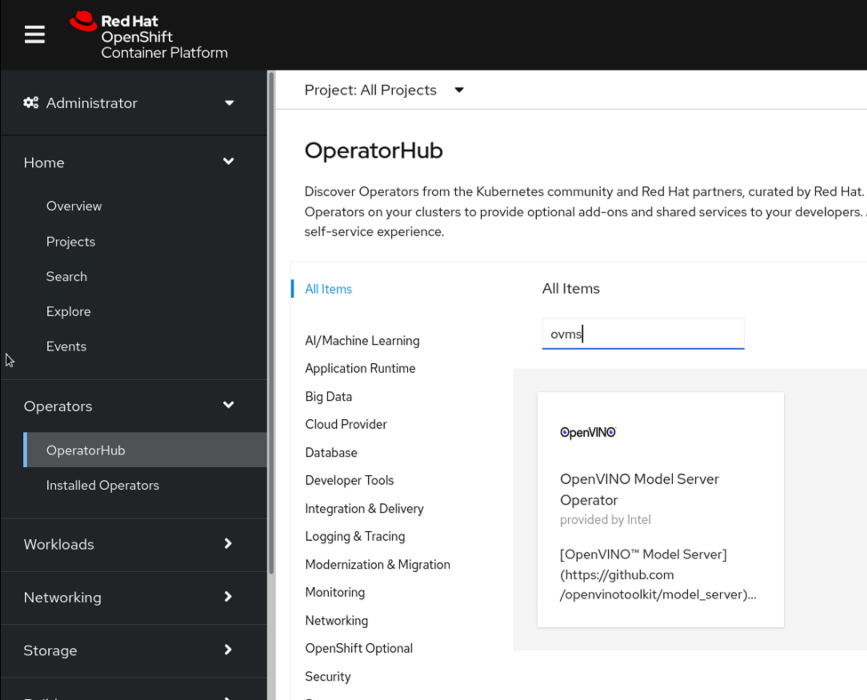
During the installation process, set Installation mode to All namespaces on the cluster (default)
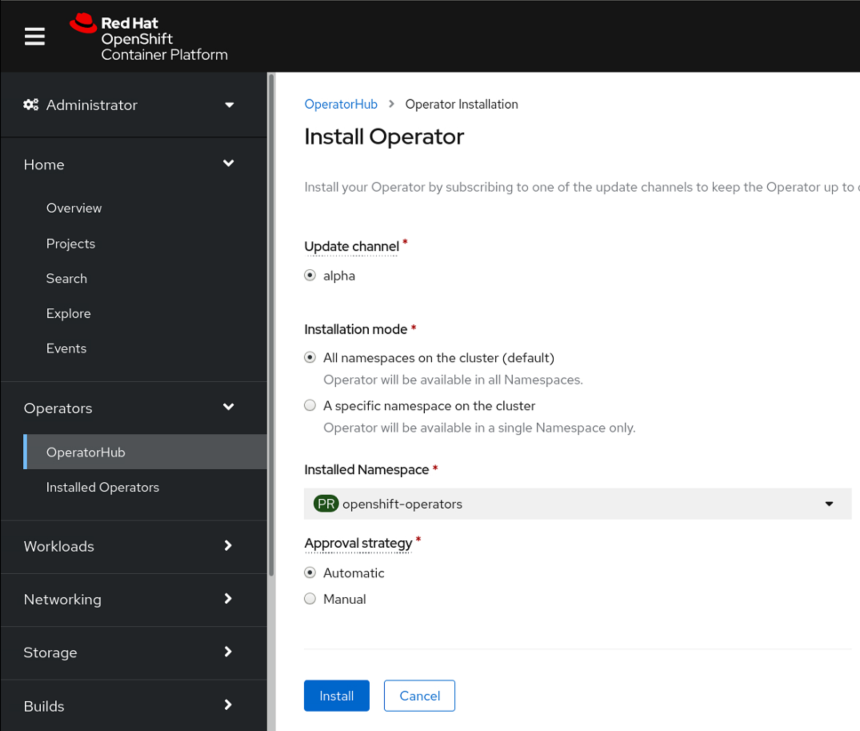
Once the Operator is installed it will be available in Installed Operators (for any existing projects)
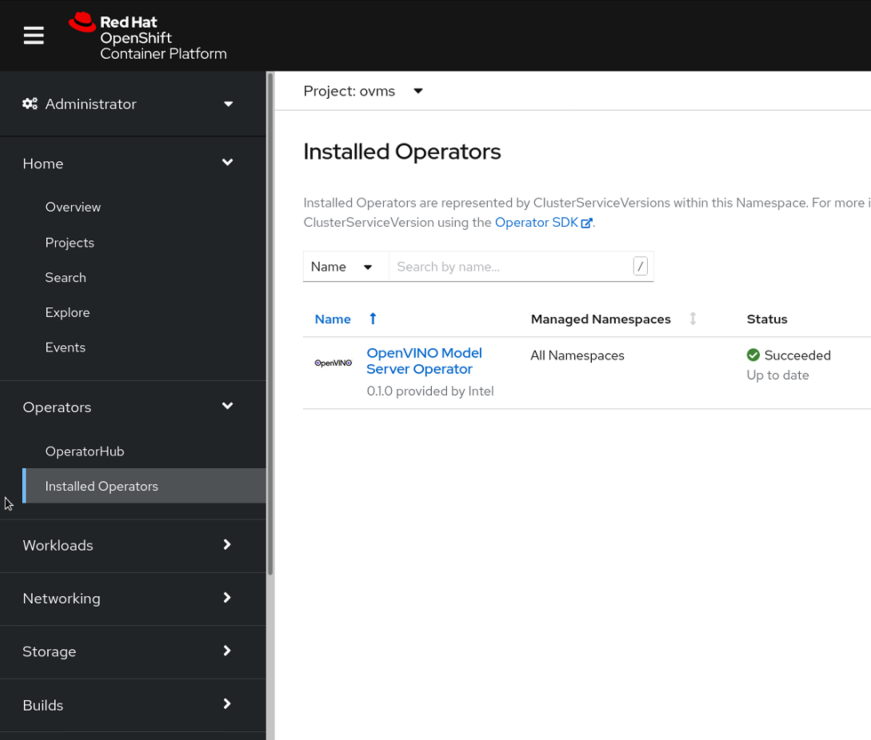
To deploy a new OpenVINO™ model server instance, click on the operator, select Ovms tab and then click Create Ovms.
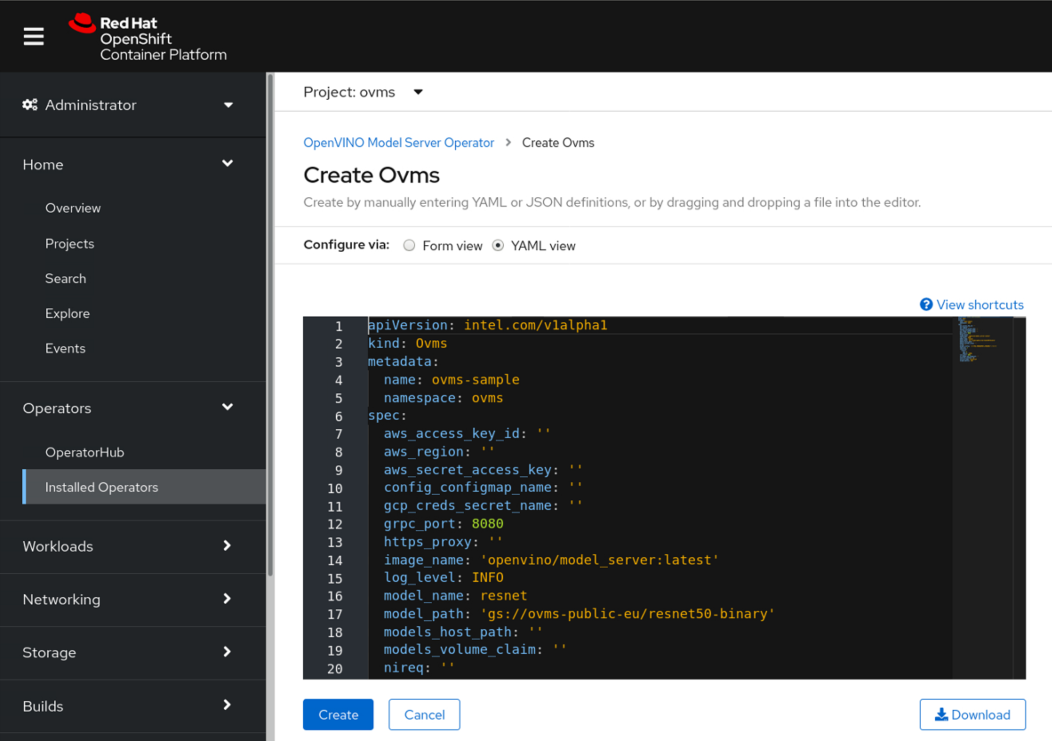
The YAML view is where you can adjust any deployment parameters including the service name, gRPC port, proxy server, cloud storage credentials (if you are using a private model repository), the model repository path and more.
After you click Create, a new OpenVINO™ model server deployment service is provisioned using the defined parameters.
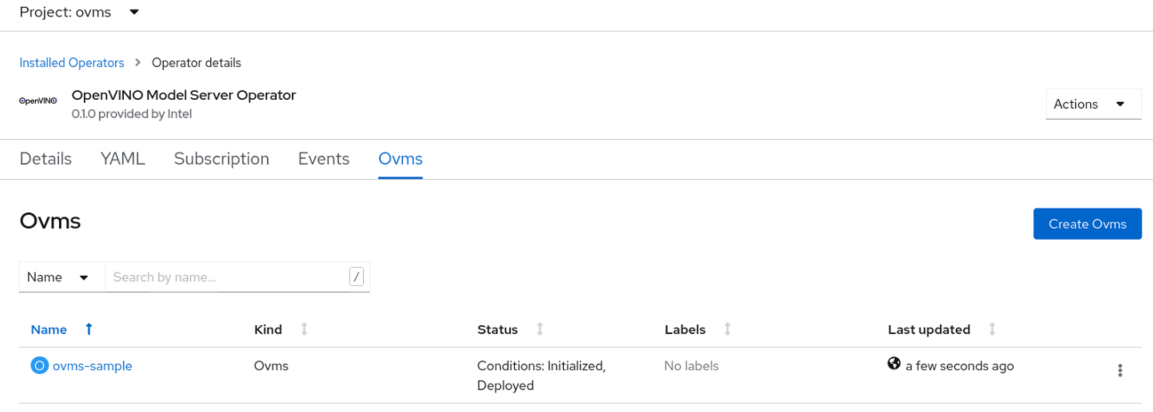
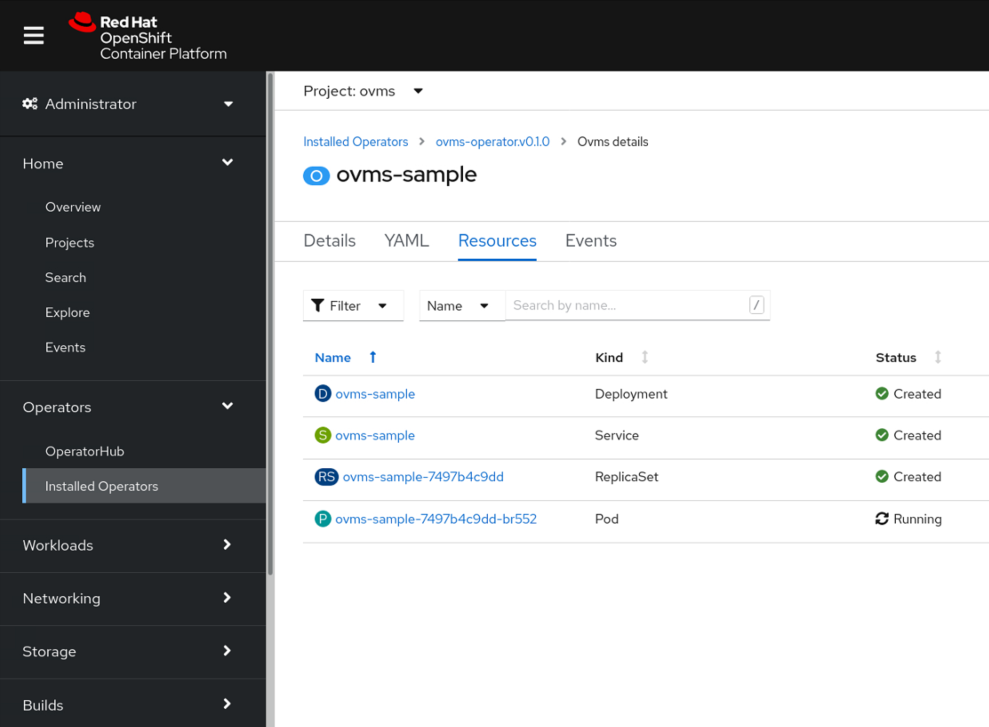
You can check the service and pod status to confirm that all models are loaded successfully and ready to serve requests.
When the Operator is installed in OpenShift, OpenVINO™ model server instances can be also managed from the command line using kubectl. Below is an example of how a deployment can be initiated:
kubectl apply -f
https://raw.githubusercontent.com/openvinotoolkit/model_server/main/extras/ovms-operator/config/samples/intel_v1alpha1_ovms.yaml
This command will deploy an instance of OpenVINO™ model server using a ResNet model from a public Google Cloud Storage bucket.
Deploy in Kubernetes
The OpenVINO™ model server Operator is also available on Operatorhub.io to enable deployments in Kubernetes. The Operator offers the same capabilities as deploying in OpenShift except no GUI interface and management console.
To install the Operator, please follow the instructions from the Operatorhub. Make sure the Operator Lifecycle Manager (OLM) is installed and run the following command:
kubectl create -f https://operatorhub.io/install/ovms-operator.yaml
Next, create an `Ovms` resource using the deployment configuration file.
wget
https://raw.githubusercontent.com/openvinotoolkit/model_server/main/extras/ovms-operator/config/samples/intel_v1alpha1_ovms.yaml
vi intel_v1alpha1_ovms.yaml
kubectl apply -f intel_v1alpha1_ovms.yaml
Below you will find a list of all features included in the Operator. You can also skip ahead to “Accessing Cluster Services” to learn how client applications can connect to the OpenVINO™ model server service for inference operations.
Key Features
The Helm chart and the Operator can manage OpenVINO™ toolkit deployments in several scenarios. Some of the most common use cases are described below, along with explanations of the prerequisites and parameters.
Using Cloud Storage for Model Repository
OpenVINO™ model server can deploy models hosted in cloud storage buckets like S3, MinIO, Azure Blob or Google Cloud Storage. This is a convenient option in distributed environments. Data Scientists and Deep Learning Software Engineers can save fully trained models in cloud storage buckets, so they are immediately available for serving. Like local storage, the model repository also requires using a specific directory structure. Each directory with a model requires numerical subdirectories that represent model versions. Each subdirectory must include model files in OpenVINO™ toolkit Intermediate Representation or ONNX format.
model/
├── 1
│ ├── model.bin
│ └── model.xml
└── 2
└── model.onnx
When deploying with Helm or the Operator, the location of the model data is set using the parameter `model_path`. The prefixes `s3://`, `gs://` or `az://`are supported. Models are often confidential and protected by access restrictions, so you will need to provide credentials to help securely download non-public model files.
Each storage vendor has different sets of parameters to configure the credentials. See below:
| Storage type | Parameters |
| S3/Minio | aws_access_key_id aws_secret_access_key aws_regionaws_secret_access_key s3_compat_api_endpoint |
| Google bucket | gcp_creds_secret_name |
| Azure blob | azure_storage_connection_string |
Note that when deploying OpenVINO™ model server with Google Cloud Storage, you must create a Kubernetes secret resource with the access token. See below:
kubectl create secret generic --from-file gcp-creds.json
If you are running an on-premises cluster and model storage is hosted in the cloud, be sure to apply the correct proxy settings, if this is required. Proxy settings can be adjusted using `https_proxy` parameter:
https_proxy: https://proxy:port
Storing Models in Persistent Volumes and Local Storage
Your model repository can be hosted in any storage class supported as Kubernetes Persistent Volumes. This includes classes like NFS, CephFS, StorageOS and many more. The prerequisite for deploying OpenVINO™ model server is creating a Kubernetes Persistent Volume Claim and copying the model repository.
In the Helm chart and Operator deployment configuration, there is a parameter called `models_volume_claim` with the name of the Persistent Volume Claim (PVC) record. This will be mounted in the OpenVINO™ model server container as a `/models/` folder. In this scenario, the parameter `model_path` should start with `/models/` followed by the path the specific model inside the mounted volume.
In smaller deployments, a simple approach is to use local storage on the Kubernetes nodes for the model repository. The model repository can be stored on the local file system of each node. To enable this, set the parameter `models_host_path` with the path on the local file system. It will be mounted inside the OpenVINO™ model server containers as `/models/` folder. Similar to the previous scenario, the `model_path` must start with `/models/` followed by the path to the specific model inside the mounted volume. For example, with model files stored in `/opt/host_models/resnet/1/` folder on the node, the deployment parameters should include:
models_host_path: /opt/host_models
model_path: /models/resnet
By default, the OpenVINO™ model server process starts inside the container as a non-privileged user called ‘ovms` with uid 5000. In case any mounted files have access restrictions, you may need to change the security context of the ovms service. It can be adjusted with the `security_context` parameter:
security_context:
runAsUser: 2000
runAsGroup: 1000
This will match the uid/gid with the account, which needs read access to the models.
Scalability Parameters
There are several methods for scaling the OpenVINO™ model server service in Kubernetes to adjust for capacity and latency requirements. The Helm chart and Operator can control assigned resources to each container. The administrator can set the CPU limits on container level or define a reservation of CPU resources to ensure it will not be consumed by other services in the cluster.
It is also possible to assign additional devices using the installed device plugins. OpenVINO™ model server can support iGPU and VPU, which can be managed by leveraging the Intel Device Plugins for Kubernetes.
A few examples of the configuration:
resources:
requests:
cpu: 4.0
memory: 256Mi
limits:
cpu: 8.0
memory: 512Mi
or
resources:
limits:
gpu.intel.com/i915: 1
Learn more about managing resources in the Kubernetes documentation.
The more CPU resources assigned to a container, the more inference requests it can handle. Some models, however, will not scale very well with a high number of CPU cores. That is the case especially for small models. In such cases, throughput of the OpenVINO™ model server service can be increased by adjusting the number of OpenVINO™ toolkit streams. This allows parallel execution of multiple requests coming from one or more clients. The number of processing streams can be set in the device plugin configuration.
plugin_config: {\"CPU_THROUGHPUT_STREAMS\":\"1\"}
or
plugin_config: {\"CPU_THROUGHPUT_STREAMS\":\"8\"}
The default value of the plugin config is "CPU_THROUGHPUT_STREAMS": "CPU_THROUGHPUT_AUTO” which is the most universal setting.
Learn more about the device plugin configuration options in the OpenVINO™ toolkit documentation.
Inference execution can be scaled by increasing the number of pod replicas. Change the parameter like in example below:
replicas: 10
This will deploy the defined number of containers in the cluster on all available nodes. All replicas will be exposed as a single service and endpoint for clients calling the API. Kubernetes will load balance between all containers automatically.
To summarize, OpenVINO™ model server can be scaled vertically by adding more resources to each container, or horizontally by multiplying the pod replicas and/or increasing the number of nodes. Throughput and concurrency in inference processing can be also tuned by modifying the device plugin configuration like CPU_THROUGHPUT_STREAMS.
Single Model and Multi-Model Configuration
OpenVINO™ model server can be started in two modes:
- with a single model and all model parameters defined as arguments
- with a configuration file that defines multiple models and/or DAG pipelines
The Helm chart and the Operator both support single model and multi-model deployments, but slightly different deployment configuration parameters are used in each scenario. For the simpler case, with a single model, you just need to set model parameters in the deployment configuration. Only the `model_name` and `model_path` are required. The rest can use the default values.
| Patameter name | Parameter description |
| model_name | model name, start OVMS with a single model, excluding with config_configmap_name and config_path parameter |
| model_path | model path, start OVMS with a single model, excluding with config_configmap_name and config_path parameter |
| target_device | Target device to run inference operations |
| nireq | Size of inference queue |
| plugin_config | Device plugin configuration used for performance tuning |
When serving multiple models, a configuration file is required. It gives flexibility but also adds a few more steps. First, you need to create a json configuration file which defines the required models and/or DAG pipelines. Check out the documentation to learn how you create this file.
The config.json can be attached to the OpenVINO™ model server pods in Kubernetes via two methods:
- add the config.json file to the configmap
This can be done with a command:
kubectl create configmap ovms-config --from-file config.json
While the config map is created the only required parameter on the operator and helm chart is ` config_configmap_name`. For example:
config_configmap_name: ovms-config
Note that the config file attached to the containers as a config map is static and cannot be changed in the container runtime.
- mounting the config file together with models
If for any reasons, the option with the config map is not convenient, the config map can be mounted with the same Kubernetes storage just like the models.
Copy the config.json to PVC volume or the local filesystem on the nodes as we described earlier. In the Helm chart and Operator configuration, define the parameter ` config_path` like below:
config_path: /models/config.json
Changes in the config.json will be applied on all the OVMS instances in the runtime.
Service Configuration
The Helm chart and the Operator both create the Kubernetes service as part of the OpenVINO™ model server deployment. Depending on the cluster infrastructure, you can adjust the service type. In a cloud environment, you can set LoadBalancer type to expose the service externally. Setting NodePort exposes a static port for the node IP address. Setting ClusterIP keeps the service internal to other cluster applications.
Examples
Below are examples showing how model server can be configured to deploy an inference service.
Single Model from a Public Google Storage Bucket
Here is a configuration example that takes advantage of the recently created model repository in a public bucket.
apiVersion: intel.com/v1alpha1
kind: Ovms
metadata:
name: ovms-sample
spec:
# Default values copied from /helm-charts/ovms/values.yaml
aws_access_key_id: ""
aws_region: ""
aws_secret_access_key: ""
config_configmap_name: ""
gcp_creds_secret_name: ""
grpc_port: 8080
image_name: openvino/model_server:latest
log_level: INFO
model_name: "resnet"
model_path: "gs://ovms-public-eu/resnet50-binary"
models_host_path: ""
models_volume_claim: ""
nireq: ""
plugin_config: '{\"CPU_THROUGHPUT_STREAMS\":\"1\"}'
replicas: 1
resources: {}
rest_port: 8081
s3_compat_api_endpoint: ""
security_context: {}
service_type: ClusterIP
target_device: CPU
https_proxy: ""
It is using all the default parameters aside from the model_name and the model_path.
Single Model from an S3 Bucket
You can also deploy models stored in an AWS S3 or MinIO storage bucket. Here are the steps showing how the folder structure should be created:
Download a face-detection model from the Open Model Zoo:
curl --create-dirs https://storage.openvinotoolkit.org/repositories/open_model_zoo/2021.3/models_bin/2/face-detection-retail-0004/FP32/face-detection-retail-0004.xml https://storage.openvinotoolkit.org/repositories/open_model_zoo/2021.3/models_bin/2/face-detection-retail-0004/FP32/face-detection-retail-0004.bin -o model/1/face-detection-retail-0004.xml -o model/1/face-detection-retail-0004.bin
model/
└── 1
├── face-detection-retail-0004.bin
└── face-detection-retail-0004.xml
Copy the model folder to an S3 bucket:
aws s3 cp model s3://bucket/ --recursive
Now, the service can be deployed with the following resource:
apiVersion: intel.com/v1alpha1
kind: Ovms
metadata:
name: ovms-sample
spec:
aws_access_key_id: "<access key id>"
aws_region: "<aws region name>"
aws_secret_access_key: "<secret access key>"
config_configmap_name: ""
gcp_creds_secret_name: ""
grpc_port: 8080
image_name: openvino/model_server:latest
log_level: INFO
model_name: "face-detection"
model_path: "s3://<bucket>/model"
models_host_path: ""
models_volume_claim: ""
nireq: ""
plugin_config: ""
replicas: 1
resources: {}
rest_port: 8081
s3_compat_api_endpoint: ""
security_context: {}
service_type: ClusterIP
target_device: CPU
https_proxy: ""
Multi-Model Pipelines
The Operator can also be used to deploy OpenVINO™ model server with more complex configurations like a multi-model OCR pipeline. The OCR pipeline reference includes two AI models and a custom node implemented as a dynamic library in C++.
To setup the reference pipeline, create a Persistent Volume Claim (PVC) called `model-storage`, which will be used to store all required data for OCR pipeline serving. Next, create a model repository, configuration file (config.json) and then build the custom node library for OCR using the guide in the documentation. Modify the config.json to change the three base_path parameter prefixes from “/OCR” to “/models/OCR”.
Then, copy the OCR folder to the `models-storage` PVC. This can be achieved by deploying a temporary pod with the PVC mounted and running `kubectl cp` command. Inside the mounted volume you should see directory and files like this:
OCR
├── config.json
├── crnn_tf
│ └── 1
│ ├── frozen_graph.bin
│ └── frozen_graph.xml
├── east_fp32
│ └── 1
│ ├── model.bin
│ └── model.xml
└── lib
└── libcustom_node_east_ocr.so
After completing the steps above, set up the Operator configuration as follows:
apiVersion: intel.com/v1alpha1
kind: Ovms
metadata:
name: ovms-sample
spec:
# Default values copied from <project_dir>/helm-charts/ovms/values.yaml
aws_access_key_id: ""
aws_region: ""
aws_secret_access_key: ""
config_configmap_name: ""
config_path: "/models/OCR/config.json"
gcp_creds_secret_name: ""
grpc_port: 8080
image_name: openvino/model_server:latest
log_level: INFO
model_name: ""
model_path: ""
models_host_path: ""
models_volume_claim: "model-storage"
nireq: ""
plugin_config: ""
replicas: 1
resources: {}
rest_port: 8081
s3_compat_api_endpoint: ""
security_context: {}
service_type: ClusterIP
target_device: CPU
https_proxy: ""
Accessing Cluster Services
Generating inference requests from the cluster is a typical use case. Both the OpenVINO™ model server service and the client applications run inside the cluster and all API communication is local.
Below is a Dockerfile that creates an image with a sample Python-based client:
FROM ubuntu:20.04
RUN apt update && apt install -y python3-pip git
RUN git clone https://github.com/openvinotoolkit/model_server
WORKDIR /model_server/example_client
RUN pip3 install -r client_requirements.txt
Build the image with the following command:
docker build -t <registry/image_name> .
Push the image to a registry:
docker push <registry/image_name>
Assuming the Operator is installed already, deploy a OpenVINO™ model server instance, which will serve a ResNet model from a public Google Cloud Storage bucket:
kubectl apply -f https://raw.githubusercontent.com/openvinotoolkit/model_server/main/extras/ovms-operator/config/samples/intel_v1alpha1_ovms.yaml
vi intel_v1alpha1_ovms.yaml
Confirm the service is running:
kubectl get service
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
ovms-sample LoadBalancer 10.97.182.162 <pending> 8080:30710/TCP,8081:30432/TCP 93s
Create and apply the following Kubernetes job:
apiVersion: batch/v1
kind: Job
metadata:
name: ovms-client
spec:
template:
spec:
containers:
- name: ovms-client
image: <registry/image_name>
command: ["python3"]
args: ["grpc_serving_client.py", "--grpc_address", "ovms-sample", "--grpc_port", "8080",
"--model_name", "resnet",
"--images_numpy_path", "./imgs.npy",
"--input_name", "0", "--output_name", "1463",
"--transpose_input", "False",
"--iterations", "1000"]
restartPolicy: Never
Get the logs from the job to see the results:
kubectl logs kubectl logs job.batch/ovms-client
……
Iteration 995; Processing time: 12.24 ms; speed 81.67 fps
imagenet top results in a single batch:
0 gorilla, Gorilla gorilla 366
Iteration 996; Processing time: 10.18 ms; speed 98.25 fps
imagenet top results in a single batch:
0 magnetic compass 635
Iteration 997; Processing time: 38.19 ms; speed 26.19 fps
imagenet top results in a single batch:
0 peacock 84
Iteration 998; Processing time: 15.29 ms; speed 65.41 fps
imagenet top results in a single batch:
0 pelican 144
Iteration 999; Processing time: 11.03 ms; speed 90.69 fps
imagenet top results in a single batch:
0 snail 113
Iteration 1000; Processing time: 18.08 ms; speed 55.33 fps
imagenet top results in a single batch:
0 zebra 340
processing time for all iterations
average time: 18.20 ms; average speed: 54.93 fps
median time: 14.00 ms; median speed: 71.43 fps
max time: 62.00 ms; min speed: 16.13 fps
min time: 6.00 ms; max speed: 166.67 fps
time percentile 90: 36.00 ms; speed percentile 90: 27.78 fps
time percentile 50: 14.00 ms; speed percentile 50: 71.43 fps
time standard deviation: 11.00
time variance: 121.03
External Access
The Helm chart and the Operator do not expose the inference service externally by default. If you need the service exposed externally, you can leverage existing features in Kubernetes and OpenShift.
The recommended method is to use an ingress controller and ingress records. This provides a more secure connection over TLS for both for HTTP used by the REST API and HTTP2 used by the gRPC API.
Below is a simple ingress configuration for the REST API, without traffic encryption, in an OpenShift environment.
apiVersion: networking.k8s.io/v1
kind: Ingress
spec:
rules:
- host: ovms-sample.apps-crc.testing
http:
paths:
- backend:
service:
name: ovms-sample
port:
number: 8081
path: /
pathType: ImplementationSpecific
With this record, it is possible to connect to the service using a simple curl command:
curl http://ovms-sample.apps-crc.testing/v1/models/resnet
{
"model_version_status": [
{
"version": "1",
"state": "AVAILABLE",
"status": {
"error_code": "OK",
"error_message": "OK"
}
}
]
}
Ingress can be used also to expose gRPC interface over TLS protocol. Read this document to learn how it can be done in OpenShift and HAProxy ingress controller.
Our sample gRPC client code supports TLS traffic encryption. Be sure to double check that the correct certificates are enabled on both the client and the ingress side.
Additionally, gRPC can be exposed using an nginx-ingress controller. To learn more about the required annotations, see the nginx documenation.
Conclusions
In summary, inferencing with OpenVINO™ toolkit can be scaled up and down in Kubernetes and OpenShift using OpenVINO™ model server. Either by adjusting the resources assigned to each container or by changing the number of nodes and pod replicas. Managing the instances of OpenVINO™ model server can be simplified by using the Helm chart or the Operator. The Operator is also quite easy to use with OpenShift because it can be configured and managed via the graphical web interface.
Finally, these methods enable deployment of scalable and optimized inference services across a variety of Intel® architectures from edge to cloud.
Notices and Disclaimers
Performance varies by use, configuration and other factors. Learn more at www.Intel.com/PerformanceIndex.
Performance results are based on testing as of dates shown in configurations and may not reflect all publicly available updates. See backup for configuration details. No product or component can be absolutely secure.
Your costs and results may vary.
Intel technologies may require enabled hardware, software or service activation.
© Intel Corporation. Intel, the Intel logo, and other Intel marks are trademarks of Intel Corporation or its subsidiaries. Other names and brands may be claimed as the property of others.