Building an entire retrieval-augmented generation (RAG) based chat question-answering pipeline from scratch is time-consuming and costly. What are the minimum hardware requirements? What software libraries and tools are needed as building blocks? Rather than spending weeks or months reinventing the wheel, it makes much more sense to leverage existing open solutions. That is where the Open Platform for Enterprise AI (OPEA) comes in – to simplify development and deployment of GenAI applications for enterprises.
OPEA is a Linux Foundation* project that provides an open source framework of building blocks called microservices for developers to incorporate into their GenAI applications. OPEA also offers GenAI examples using these microservices, including AgentQnA, ChatQnA, Code Generation, Document Summarization, Text2Image, and more. OPEA has over 50 industry partners, all experts in specific areas, contributing to the open source project. By building your application with OPEA, you are leveraging the work of these experts without having to start from scratch, and you can get something running in minutes.
Getting Started with the ChatQnA GenAI Example
Deploying the OPEA ChatQnA example with Docker* is straightforward—you can simply follow the OPEA Getting Started Guide. We will deploy on Intel Tiber AI Cloud CPU-based instances, powered by 4th Generation Intel® Xeon® Scalable processors.
In this article, we will demonstrate running the DeepSeek-R1-Distill-Qwen-1.5B model on a cost-effective VM-SPR-MED instance with 16 physical CPUs, 32GB of memory and 32GB of disk. The CPU instances guide lists all available hardware resources and pricing. You can also run OPEA GenAI examples on Intel Tiber AI Cloud using larger instances with more CPU cores, multiple nodes, GPUs, or Intel® Gaudi® AI Accelerators, but the focus here is on a more cost-effective instance.
After you have launched your instance, you’ll need to follow a few additional steps shown below to create a load balancer. Load balancing is the process of distributing a set of tasks over a set of resources to make the overall processing more efficient. All Intel Tiber AI Cloud instances have private IP addresses and require a proxy jump to access them.
First, launch a VM-SPR-MED instance on Intel Tiber AI Cloud (the second option in the image). The DeepSeek reasoning model we run requires < 32GB of RAM and is a reason why Deepseek was lauded for its breakthrough efficiency.
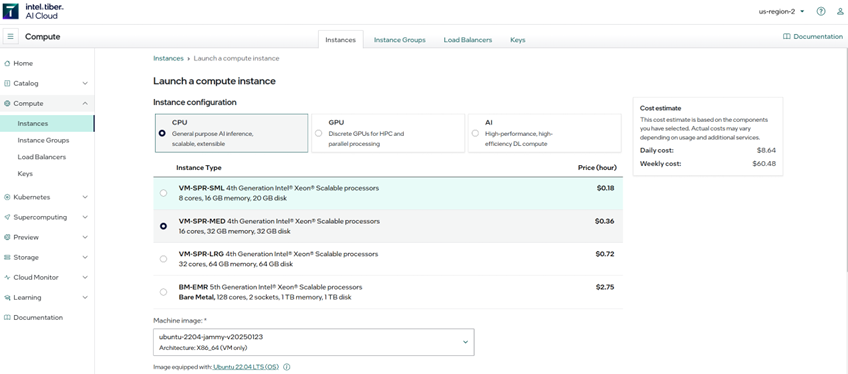
Deploying the OPEA ChatQnA Example
After logging on to your instance, the first step is to install Docker* Engine. You can follow the instructions in the docs or download and run the install_docker.sh script using the commands below:
wget https://raw.githubusercontent.com/opea-project/GenAIExamples/refs/heads/main/ChatQnA/docker_compose/install_docker.sh
chmod +x install_docker.sh
./install_docker.sh
You will also need to configure Docker to run as a non-root user with these instructions.
Next, follow the access and configuration steps in the Xeon README.md for ChatQnA. It will walk you through how to download the GenAIComps and GenAIExamples GitHub* repositories and what commands to run in your ITAC instance. For simplicity, only the minimum steps will be shown below.
Clone the GenAIExample repository and access the ChatQnA Intel® Gaudi® platform Docker Compose files and supporting scripts:
git clone https://github.com/opea-project/GenAIExamples.git
cd GenAIExamples/ChatQnA/docker_compose/intel/cpu/xeon/
Set up environment variables for your Hugging Face token and IP address:
export HUGGINGFACEHUB_API_TOKEN="Your_Huggingface_API_Token"
export host_ip=$(hostname -I | awk '{print $1}')
If you are in a proxy environment the Xeon README will have further instructions.
In the set_env.sh script, you’ll need to set LLM_MODEL_ID to the DeepSeek-R1-Distill model that corresponds to Hugging Face model card: deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B.
Modify ChatQnA’s set_env.sh to run DeepSeek-R1-Distill-Qwen-1.5B, as shown below:
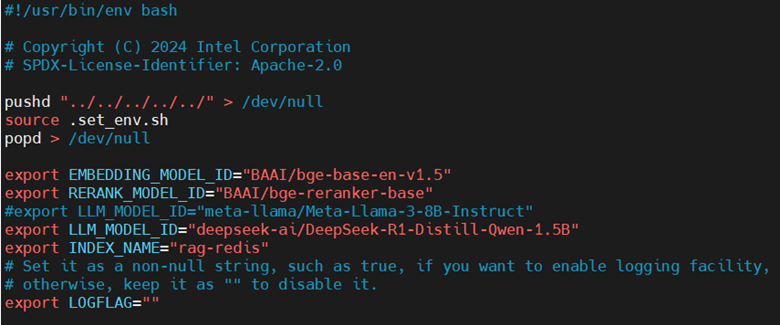
When finished, run set_env.sh to set the environment variables.
source ./set_env.sh
You may verify that environment variables like LLM_MODEL_ID are set correctly with:
echo $LLM_MODEL_ID
The final step is to run docker compose to start all the microservices and the ChatQnA megaservice. The YAML file compose.yaml is the default one to use and will use vLLM as the inference serving engine for the LLM microservice. If this is your first time running docker compose, it will take extra time to pull the docker images from Docker Hub*.
docker compose -f compose.yaml up -d
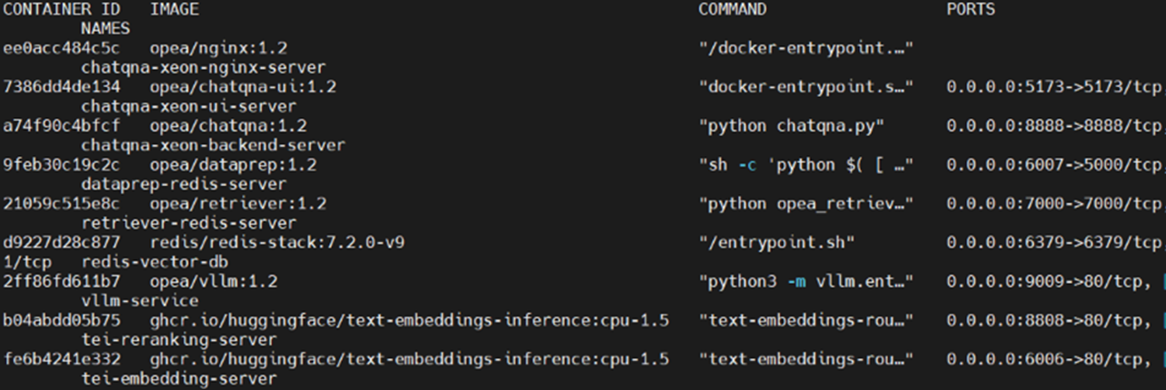
You can use docker ps to see all the containers that are running. This will take a few minutes for everything to set up. You can determine if the setup is complete if the output of this command shows vllm-service has a “healthy” status, or you can run docker logs vllm-service and confirm that you see the message “Application startup complete.”
Below, you’ll see docker ps showing the docker containers starting up. The vllm-service has a health status of “starting.”
To observe the logs of the vllm-service:
docker logs vllm-service
Below you can see that the vllm-service has completed setup:

Now that you have ChatQnA up and running, it’s time to test out the user interface (UI). Type in your local terminal:
ssh -J guest@<proxy_jump_ip_address> -L 80:localhost:80 ubuntu@<private_ip_address_of_vm
Open a web browser and navigate to the virtual IP address of your load balancer. You should see the UI looking something like this:

We recommend Deepseek reasoning models for math, science, coding, and general knowledge problems, and for situations where you’d want to follow the model’s chain-of-thought. Try asking it math problems, including quadratic functions, performing arithmetic, calculus, physics, chemistry you name it! It can reason about alternative approaches, perspectives, while imitating the human thought processes.
When you are finished and want to stop your ChatQnA session, you can do so with this command in your current directory:
docker compose down
You should see all your services spinning down.
ChatQnA with a DeepSeek Reasoning Model
A major benefit of AI reasoning models is transparency into the AI “thought process.” Reasoning models not only provide an answer, but the rationale that was used to arrive at the answer. This type of model has applications in healthcare research, legal discovery, financial analysis, and education, where users desire transparency or auditability to what information, or alternative approaches were considered, and the rationale for the final answer. Reasoning models like the DeepSeek-R1-Distill-Qwen-1.5B used here are suitable for such use cases.
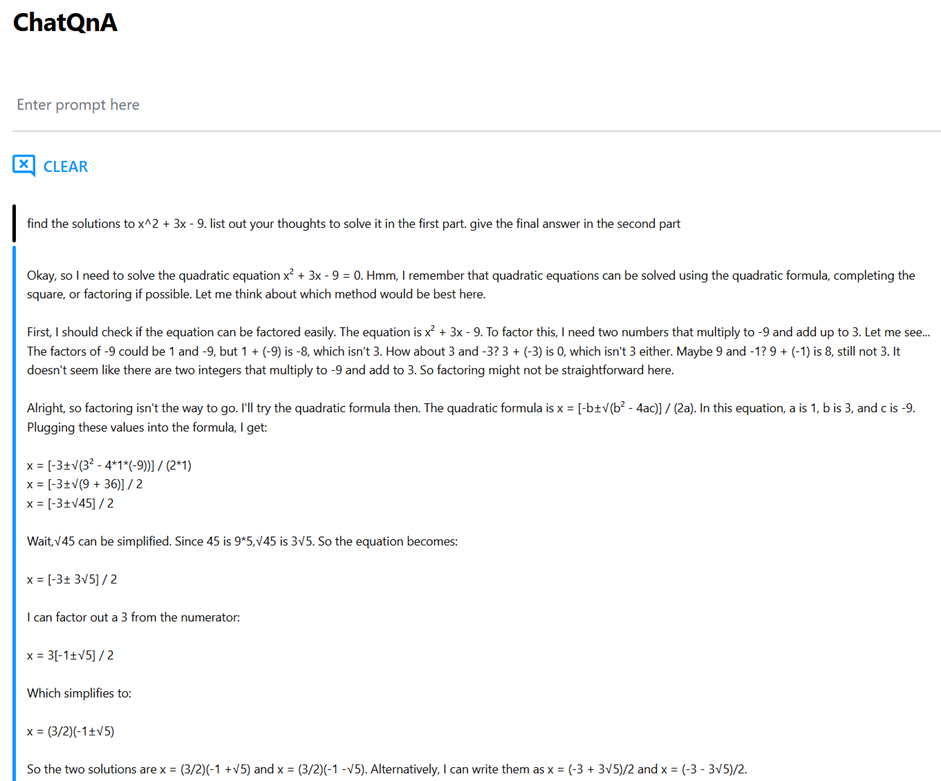
In this example, we will imagine that we’re using ChatQnA as a personal math tutor and compare the DeepSeek-R1-Distill-Qwen-1.5B reasoning model with a non-reasoning type model Qwen2.5-Math-1.5B to solve a quadratic function. We will be asking both models to find the solutions to :
x2+3x-9=0
For reference, the correct answer should be two solutions: (-3+3 sqrt(5))/2 , (-3-3 sqrt(5))/2
To show the difference, we first run OPEA ChatQnA from the previous section, setting LLM_MODEL_ID=Qwen/Qwen2.5-Math-1.5B. You can see this model picks one approach and provides a straightforward answer. It doesn’t provide the rationale for why it used its approach:
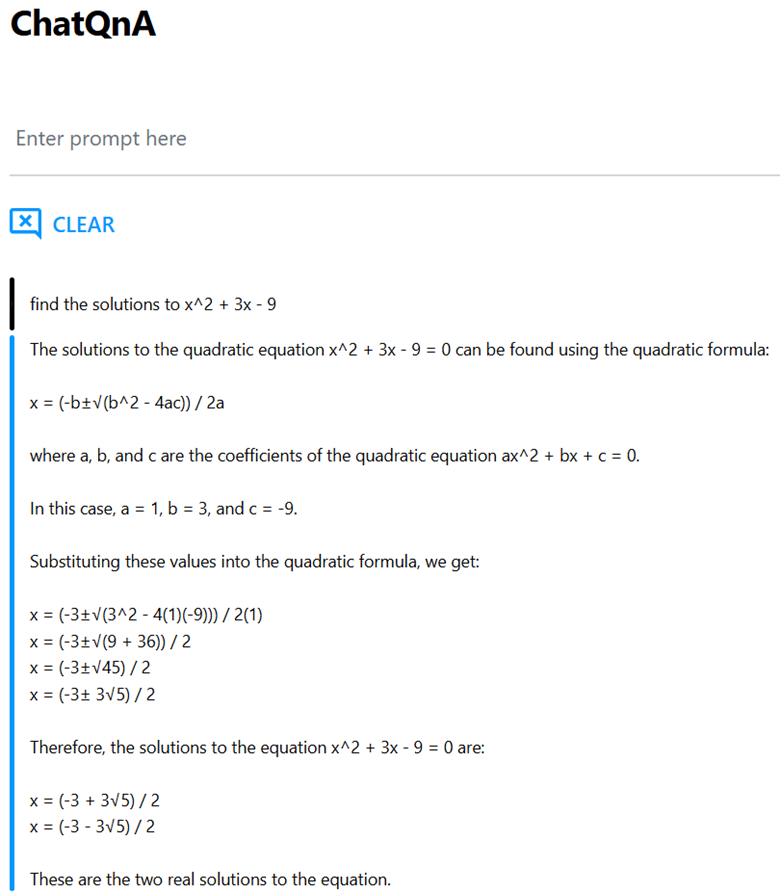
In the next figure, ChatQnA is running the DeepSeek-R1-Distill-Qwen-1.5B reasoning model and provides a more comprehensive thought process, which imitates a human thought process, to arrive at the correct answer. You’ll see that the model considers a couple approaches and provides explanation for why it opted for the approach it did, and how it double checks a calculation. The response is more human-like, and instructional.

Adding Documents to Chat QnA
A retrieval-augmented-generation (RAG) system like ChatQnA is highly advantageous because it gives your model the capability to use new data without going through the more expensive process of fine-tuning or pre-training a model.
The ChatQnA UI has a feature that allows you to upload documents to create a knowledge base. The documents are converted into embeddings using the embedding model BAAI/bge-base-en-v1.5 and stored in a Redis* vector database, although ChatQnA allows configuration of other popular vector databases as well.
During RAG, context related to the input prompt is retrieved from the vector database to create a modified prompt. This modified prompt is then used as the input to the text generation service using a model such as Deepseek-R1-Distill-Qwen-1.5B model.
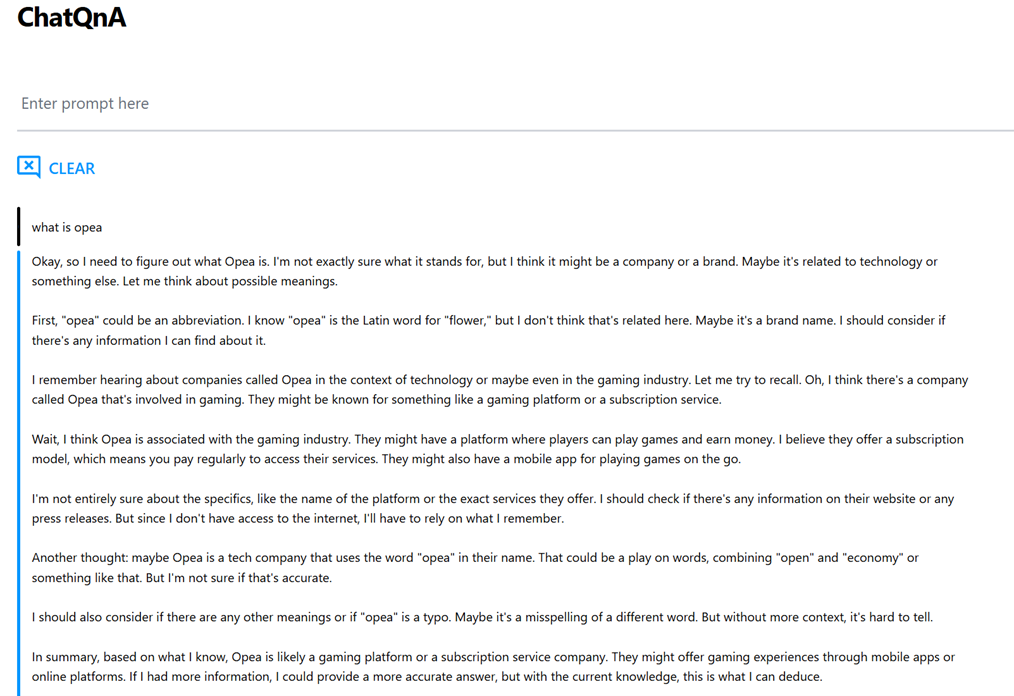
To demonstrate how RAG can help the model arrive at better answers, we ask ChatQnA what OPEA is, with and without RAG. The figure below shows that the DeepSeek-R1-Distill-Qwen-1.5B model doesn’t know what OPEA is, likely because it was trained with data from before the creation of OPEA. OPEA is definitely not related to the gaming industry:
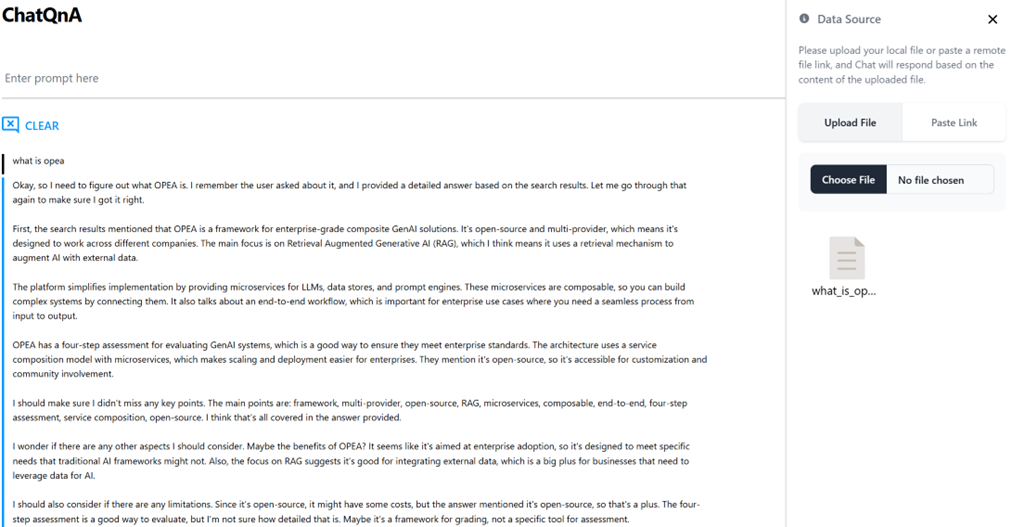
The reasoning model allows us to see that the model is lacking context to provide the correct answer. In the upper right of the UI, there is a button to upload documents. We will upload a document that gives an overview of OPEA. The figure below shows that the model provides the correct answer to the question with RAG.
Improving Your RAG ChatBot’s Performance
Using the OPEA microservices framework, you’ve seen how easy it is to deploy a RAG application. This approach allows developers to benefit from advancements in open source AI in just minutes. In this solution, you don’t need to write new code at all; simply swap out models and components to tailor your application to your specific needs. OPEA is both cloud-agnostic and hardware-agnostic, ensuring you avoid vendor lock-in and maintain flexibility.
To further optimize your RAG-based chatbot, consider the following steps:
- Model Flexibility: Experiment with different models from the Hugging Face Hub, to benefit from the latest model innovations, and find the best fit for your use case.
- Optimize Compute: Consider the price-performance requirements of your ChatQnA application vs. your use case. OPEA works with CPUs, accelerators, and GPUs.
- Experiment with More GenAI Examples: Dive into other GenAI examples provided by OPEA, such as AgentQnA, AudioQnA, CodeGen, CodeTrans, DocSum, VideoQnA, and more.
Contribute to OPEA
Like what you see? Get involved! By engaging with the OPEA community, you can contribute code, provide feedback, and help enhance the platform's capabilities while also gaining valuable exposure and collaboration opportunities.
We invite you to start building with OPEA through the Intel® Liftoff Startup program, in which you can rapidly develop and optimize your AI products with OPEA. We also welcome contributions, enabling you to integrate a new microservice or a genAI sample into the ecosystem and help expand your reach. If you’re working either of the above, we would love to collaborate with you on blogs, videos, and podcasts to showcase your innovations and thought leadership within the industry.
Resources for Learning More about OPEA and ITAC
For more information about Intel Tiber AI Cloud instances powered by Intel® Xeon® Scalable processors, OPEA, and DeepSeek-R1 models you can run on these hardware platforms and software libraries, check out the links below.
- Intel® Tiber™ AI Cloud
- opea.dev: Open Platform for Enterprise AI main site
- OPEA Documentation
- OPEA Projects and Source Code
- DeepSeek-R1
- Resources for getting started with GenAI development
© Intel Corporation. Intel, the Intel logo, Intel Tiber, and other Intel marks are trademarks of Intel Corporation or its subsidiaries. Other names and brands may be claimed as the property of others.
About the Authors
Alex Sin, AI Software Solutions Engineer, Intel
Alex Sin is an AI software solutions engineer at Intel who consults and enables customers, partners, and developers to build generative AI applications using Intel software solutions on Intel® Xeon® Scalable Processors and Gaudi AI Accelerators. He is familiar with Intel-optimized PyTorch, DeepSpeed, and the Open Platform for Enterprise AI (OPEA) to reduce time-to-solution on popular generative AI tasks. Alex also delivers Gaudi workshops, hosts webinars, and shows demos to beginner and advanced developers alike on how to get started with generative AI and large-language models. Alex holds bachelor’s and master's degrees in electrical engineering from UCLA, where his background is in embedded systems and deep learning.
Ed Lee, Sr. AI Software Solutions Engineer, Intel
Ed Lee works with startups as part of the Intel Liftoff ® startup program. The program accelerates AI startups to build innovative products with open ecosystems. At Intel he works with several open ecosystems such as OPEA, OpenVino, vLLM, and on a range of hardware and cloud services. Ed’s background spans finance, tech, and healthcare, and he has delivered solutions including large language models, graph, reinforcement learning, and cloud services. Ed is a co-inventor on patents about AI for chronic kidney disease, and modular data pipelines. He holds a master’s degree in financial engineering from UC Berkeley.
Kelli Belcher, AI Software Solutions Engineer, Intel
Kelli Belcher is an AI software solutions engineer at Intel with a background in risk analytics and decision science across the financial services, healthcare, and tech industries. In her current role at Intel, Kelli helps build machine learning solutions using Intel’s portfolio of open AI software tools. Kelli has experience with Python, R, SQL, and Tableau and holds a master of science in data analytics from the University of Texas.