Authors: Xu Hao, Li Tianyou, Zhang Shiyu, Andy Rudoff, and Robert Dickinson, Intel
Abstract
Data persistence refers to a characteristic that data needs to outlive its creator. In recent years, persistent memory, a new type of computer memory supporting memory-like byte-addressable access and disk-like persistence, became a promising technique for facilitating data persistence in memory and its management. So far persistent memory has been supported in many programming languages such as C, C++, and Java*. Meanwhile, it has not yet been well supported in JavaScript*, a popular scripting language for web applications development. This paper presents JavaScript Persistent Memory Development Kit (JSPMDK), a JavaScript binding to Intel’s Persistent Memory Development Kit (PMDK), to support data persistence in JavaScript using persistent memory. JSPMDK consists of (1) a JavaScript persistent object pool that serves as a persistent heap in which persistent objects are created and managed. This pool is also enhanced for guaranteeing data consistency; and (2) a set of JavaScript persistent APIs that provide programmers with a support in creating, managing, and accessing persistent data in an easy-to-use and safe manner. We have implemented JSPMDK and evaluated it against MongoDB* in Node.js* environment on microbenchmarks and real-world applications. The evaluation results show that compared with MongoDB, JSPMDK can achieve a 9.8x speedup, denoting that JSPMDK can enhance performance of Node.js applications in practice.
Introduction
Data persistence refers to a characteristic that data needs to outlive its creator. Many software applications require their data to be persistent, i.e., the data needs to be safely stored when an application completes or fails, and can as well be consistently loaded or recovered when needed. One typical solution to data persistence is to store data in external databases or file systems at runtime. For this purpose, many programming languages do provide Application interfaces (APIs) such that programmers can create, access and manage persistent data in their applications. In this situation, data structures’ transformations are usually required, as data is differently kept in memories and in storages; important properties, such as Atomicity, Consistency, Isolation and Durability (ACID), also need to be guaranteed when persistent data is stored and loaded.
In recent years, Non-volatile Memory (NVM)1 becomes a promising technique for facilitating data persistence in memory. NVM is a new type of computer memory that supports memory-like byte-addressable access and disk-like persistence. With NVM, data in persistent memory can be kept persistent; it still retains its structure in memory, without requiring error-prone data transformations. So far persistent memory has been supported in many programming languages such as C, C++, and Java. One notable effort is Persistent Memory Development Kit (PMDK)2, a set of C/C++ libraries developed by Intel. PMDK implements the NVM programming model3, providing facilities for accessing persistent memory and managing persistent data in programming. Intel has also developed PyNVM4 and PCJ5 that provide language bindings to PMDK for persistent memory programming in Python and Java, respectively.
Meanwhile, persistent memory has not yet been well supported in JavaScript, a popular scripting language for software development. Thus data persistence in JavaScript is typically achieved with the help of file or database such as MongoDB6 and the corresponding APIs. However it raises difficulties in JavaScript programming, as programmers have to carefully design and implement serialization and deserialization between JavaScript objects and persistent data records in file systems and/or databases. Having realized the potential of persistent memory in supporting data persistence, we propose JSPMDK, a unified framework that supports data persistence in JavaScript using persistent memory. JSPMDK mainly tackles two challenges of introducing persistent memory into JavaScript programming.
Challenge 1: Persistent data in persistent memory need to be efficiently accessed and managed
Ideally, data persistence using persistent memory boosts the performance of JavaScript programs: compared with the traditional data persistence using external storages and databases, data persistence in persistent memory provides engineers with several attractive persuasions, such as in-memory data storage and structural compatibility. However, objects are pervasively used in JavaScript programs, which requires a persistent data heap to be designed. The JavaScript’s native heap cannot be directly employed here, because data values in the heap are much more relevant to program status at runtime. For this reason, a value storing a memory address should not be recovered and used after a process completes even if the heap could be placed on persistent memory. To tackle this challenge, we provides a JavaScript persistent object pool (JSPOP) which serves as a persistent heap in persistent memory for persistent objects. JSPOP allows programmers to store JavaScript objects as persistent objects, without incurring much overhead. In JSPOP, relative memory addresses can be bi-directionally transformed into absolute addresses, making memory addressable.
Challenge 2: Programmers do need facilities for manipulating and managing JavaScript’s persistent objects
Facilities are needed for simplifying manipulation and management of persistent data/objects. Typically, a set of APIs are needed for creating and recovering persistent data/objects in persistent memory. These APIs also need to be encapsulated as transactions for guaranteeing data consistencies. Therefore, JSPMDK provides a set of fine-grained transactional operations that enable programmers to create and access JavaScript’s persistent objects like normal objects. PMDK is employed here, allowing transactions to meet the ACID constrains. This paper makes the next contributions:
- Object pool. JSPMDK provides with a heap-like JavaScript Persistent Object Pool (JSPOP) that supports data persistence in JavaScript using persistent memory. The pool stores persistent data/objects, and also allows them to be accessed at runtime and be recovered when the application crashes. Transactional operations and garbage collections are carefully designed for JSPOP such that data consistency can be guaranteed.
- APIs. JSPMDK provides transactional operations for JSPOP. These operations are further encapsulated in a set of APIs (JSPA), enabling programmers to create and access JavaScript’s persistent objects as if native JavaScript objects.
- Implementation and evaluation. We have implemented JSPMDK as a Node.js module and evaluated it against database-supported data persistence styles on a set of micro-benchmarks and real-world applications. The evaluation results show that compared with MongoDB’s object store, JSPMDK can achieve a 4.9× speedup; when applied to storing binary data, JSPMDK can achieve a 9.8× speedup, denoting that JSPMDK can enhance performance of Node.js applications in practice. We are now going through SDL to open source JSPMDK.
Design of JSPMDK
JavaScript Persistent Object Pool
JSPOP (JavaScript Persistent Object Pool) is heap-like object pool that allows programmers to store or load persistent objects in transactions. It is designed on the basis of libpmemobj in PMDK that memory chunks on persistent memory are allocated and deallocated in transactions, without incurring heavy memory fragmentation. Figure 1 shows the layout of JSPOP.
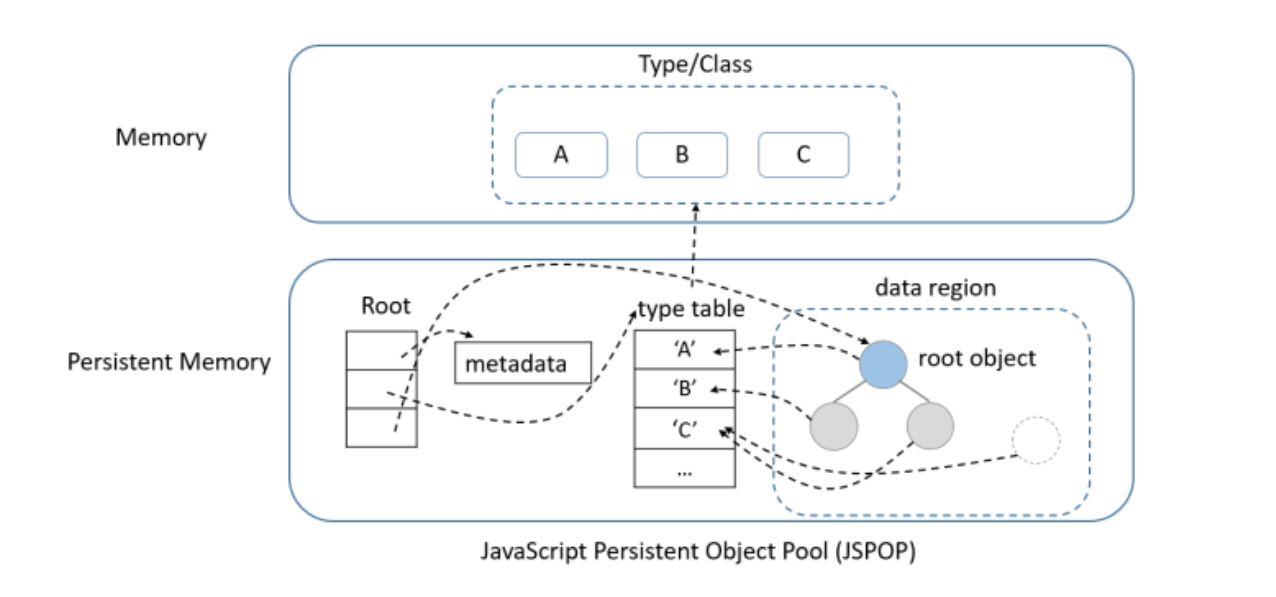
Figure 1. JavaScript Persistent Object Pool
Unlike the JavaScript's heap implemented in V8, a JavaScript engine that is used in Chrome* and Node.js, JSPOP is a simplified heap-like persistent pool that stores persistent JavaScript objects with their types. Meanwhile, the pool is still different from V8's heap. First, since the objects in the pool are persistent, the unused ones need to be released even after the program crashes. Second, the persistent types, even the primitive types like number and string, behave differently than those in JavaScript; they need to be allocated and managed by PMDK for providing atomic access, and thus a specific type system needs to be designed. In addition, compared with accessing objects in V8's heap, accessing persistent objects often incurs extra overhead due to limits of persistent memory. Thereafter, JSPOP is designed to be composed of a metadata area, a root object, a type table, and a data region. All of these components need to be persistent in persistent memory for guaranteeing the availability and consistency of JSPOP.
- Root: Root is the entry that we access the data in the pool, which is the structure that localized by the pmemobj_root() function in libpmemobj. It contains persistent pointers to the metadata area, the type table and the actual root object in the data region. In order to avoid memory leak, any object that is unreachable by traversing the object graph starting from the root object should be garbage collected. Note that persistent pointer is no longer a virtual memory address, but a tuple containing the uuid of the pool and the offset of the object in the pool.
- Type table: A persistent object in the pool is stored with an integer as its type code—an index of its type in the type table. The type table is a dynamic list of strings containing the names of the persistent types corresponding to JavaScript native type system.
- Data region: A data region contains at least one object as its root object. If the root object is not specified, an undefined object is set as the root object, which can then be changed to an object of any persistent type. If it is set to a container type (such as Array or Object), any other persistent objects can be attached to the root object and survived during garbage collection.
JavaScript Persistent API
In programming, users usually create JSPOP instances served for various applications. They are also required to define root objects as handles for accessing persistent objects even after a system reboots. Thus we design and implement JSPA (JavaScript Persistent APIs) for managing pool instances and persistent objects. We employ JavaScript Proxy to trap the setter and getter of the properties of the pools and objects, and compared with typical database’s asynchronous operations to access persistent data, JSPA provides programmers with synchronous APIs to operate persistent objects as if JavaScript native objects, making codes more readable.
Figure 2. An Example of Using JavaScript Persistent APIs
Figure 2 also shows an example illustrating how the persistent APIs are used: JavaScript programmers can invoke new_pool() and create() (line 2 and 3) to create a JSPOP instance with a specified path and the size (in bytes). The parameter path denotes an absolute path to the pool file, which can reside either in a physical persistent memory that is accessible via the Linux's DAX extensions or in the emulated persistent memory by reserving RAM to be accessed through DAX via kernel configuration. After that, programmers can allocate objects on the newly created pool by invoking create_object() (line 6). As is shown in line 7 to line 9, persistent objects can be accessed as if native JavaScript objects, however the changes is set to persistent memory and can be revisited when being reloaded.
Line 11 set the persistent object “pobj” to the root of the pool, so it becomes a root object. The root object is the only one that is visible in the pool—any other objects must be attached to it to be accessible. It is used as an entry point to access JSPOP, in particular, when a JSPOP instance is reloaded. Since we trap the setter and getter of persistent objects, a programmer can simply use an equality operator to implicitly invoke function to set root object. Similarly, “get root” function implicitly invoked at line 12 retrieves the root object as a persistent object. Besides, non-persistent objects can be directly set to the root or to the properties of other persistent objects. They will be firstly persisted in the pool and converted to persistent objects.
Data Consistency
JSPOP needs to guarantee data consistency: the pool needs to be recoverable when program aborts abnormally. Consider the code at line 8 in Figure 2, it try to set the property “b” of persistent object “pobj” as a string. This code fragment is valid when the object is volatile, while its output can be nondeterministic when it is persistent—When the program crashes during memory copying, the property may be partially set and exposed to users. In addition, consider the case to transfer money from a bank account to another, if program crash just after money is withdrawn from “bankAccountA” (line 1), inconsistency can occur.
Figure 3. An Example of Inconsistency
Thereafter, we provide programmers with two levels of data-consistency:
- Operation-level data-consistency: We firstly guarantee the atomicity of each single operation. However, so far only 8 bytes of memory can be written in an atomic way. Thus transaction APIs in libpmemobj is employed to perform consistent operations in JSPOP. In each transaction, the operations are firstly persisted to redo or undo logs, and thus they can be redone or rolled back in case of failure. A transaction in this level is performed automatically; it is blind to the end users.
- Function-level data-consistency: We also expose a transactional APIs, which provides end users with function-level consistencies. As is shown in Figure 4, users can invoke transaction() to execute codes in a transaction. Changes to the persistent objects will be committed in the end of the transaction. If the program aborts before transaction ends, all the changes will be rolled back.
Figure 4. An Example of Using Transaction
Inconsistency can also occur in the process of garbage collection (GC). Typical JavaScript GC design does not fully adapt to JSPOP: since the program can crash at any time, a GC needs to be designed whilst the pool can be recovered to a consistent state upon failure. Therefore, we utilize transaction to provide a crash-consistent GC for JSPOP. Due to the features of libpmemobj that our work is based on, we do not need to consider the memory fragmentation brought by deallocation. So we simply apply a transactional mark-sweep GC algorithm to JSPOP.
Results
We have implemented JSPMDK by Node.js addon on Node.js v8.12.0. The implementation is composed of 3K lines of C++ code and 0.5K lines of JavaScript code. We have evaluated JSPMDK's capabilities in processing persistent objects and binary data. Our evaluation is aimed at answering the following questions:
- Accessing persistent objects. Is JSPMDK effective in saving and loading persistent objects?
- Accessing persistent binary data. Is JSPMDK effective in accessing binary data?
We compared JSPMDK with two database-supported data persistence styles:
- Style 1: MongoDB's object store for persistent objects. In order to evaluate JSPMDK's capability of accessing persistent objects, we compared it with a solution that stores objects as outside structures by MongoDB. Note that objects in MongoDB are stored with the ids, allowing them to be referred by each other. On the contrary, JSPMDK stores (and accesses) them using pointers. In evaluation, we performed set and get operations on single property of persistent objects and computed the performance enhancement raised by JSPMDK.
- Style 2: MongoDB's binary store for persistent binary data. JSPMDK allows binary data to be processed through PersistentArrayBuffer (PAB) objects, which is the persistent version of JavaScript ArrayBuffer. Thus we compared it with MongoDB's on MIDIFile, an editor that read and write standard MIDI files, which are binary musical files that can be played by MIDI players. The relational database MongoDB can store files as binary buffers. In the evaluation, we loaded the buffer from MongoDB, modified it in memory, and then wrote it back to database.
Our evaluation is conducted on a machine with Intel® Core™ i7 7700k CPU, 8 cores and 32GB memory reserved for Persistent Memory Emulation among 64GB total memory. To make a fair comparison, we also put MongoDB on a ramdisk. The operating system is the Ubuntu-18.04.
Accessing Persistent Objects
As Figure 5 shows, we compared JSPMDK and MongoDB's object store on setting and getting single property of over 2000 persistent objects or records. Clearly, the results show that JSPMDK outperforms MongoDB's object store by more than 4.9x in get operations and about 2.3x in set operations. One main reason is that objects are stored as BSON structures in MongoDB, requiring extra serialization or deserialization to be accessed. Comparatively, JSPMDK can localize any part of the data by memory offset.
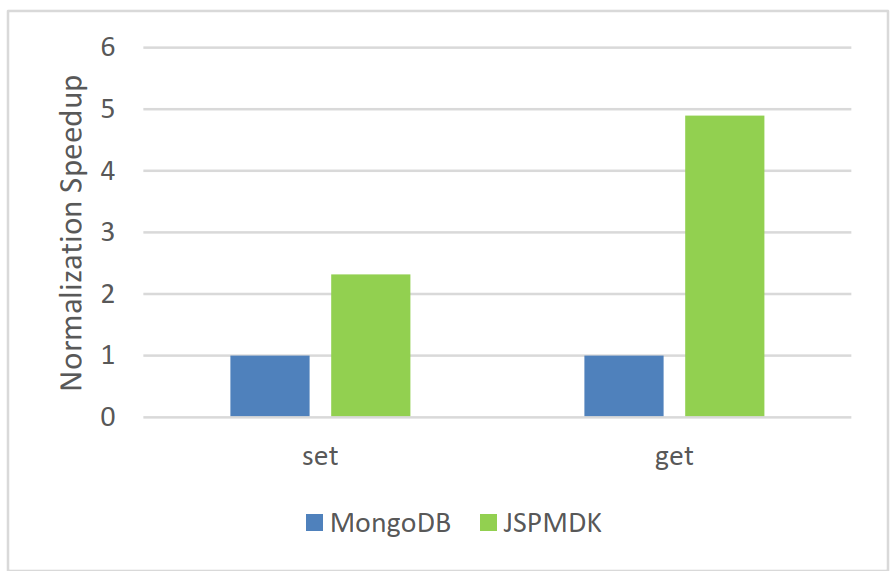
Figure 5. JSPMDK's speedup over MongoDB's object store. Note that the speedup values have been normalized
Thus we draw our first observation: JSPMDK outperforms MongoDB when accessing persistent objects by about 4.9x speedup in get operations and 2.3x speedup in set operations.
Accessing Binary Data
We conducted our evaluation by reading or modifying specific data region of thousands of MIDI files, with their sizes at 20~40KB. Using relevant APIs, we can easily access these data region such as “sound track” or “lyric” of a MIDI file. In this evaluation, we apply PAB to map the file as a persistent buffer, modify specific region, and then flush the changes.
We computed the average operation time of JSPMDK and MongoDB processing MIDI files. As Figure 6 shows, JSPMDK outperforms MongoDB by 3.2x of speedup in reading metadata of MIDI files and 9.8x of speedup in writing them. JSPMDK achieves higher performance than MongoDB, because (1) With MongoDB, the entire file is required to be loaded into memory. Instead, a PAB object maps the file to the memory space and only the metadata region in the file will be accessed; (2) when the buffer is wrote back to the file after metadata is changed, only the modified part (64 bytes in a 40KB file) will be written in a PAB object, however MongoDB need to write the whole buffer. The performance enhancement becomes significant when large files are processed.
This leads to our second observation: JSPMDK outperforms database on accessing binary MIDI files. In particular, it achieves 3.2 time speedup in reading metadata 9.8 time in writing them.
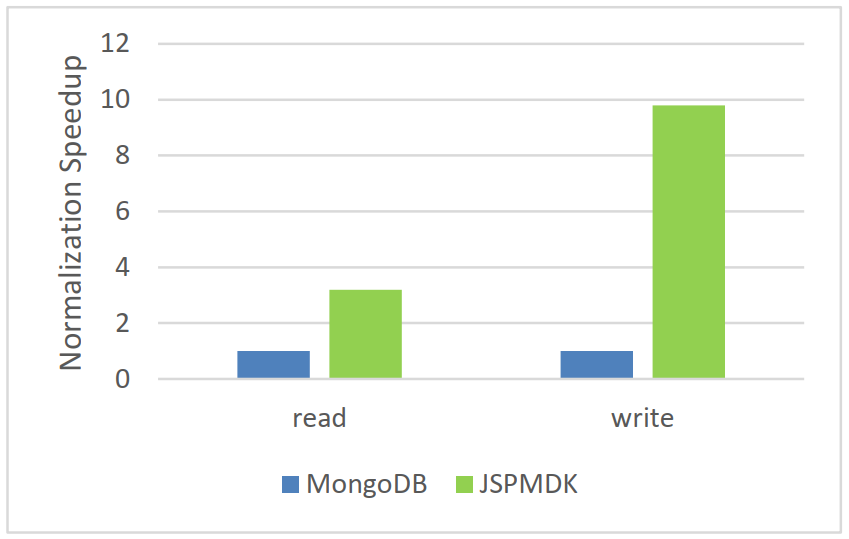
Figure 6: Comparing MongoDB and JSPMDK (PAB) in processing MIDI files
Summary
JSPMDK is an extension to JavaScript's runtime. It supports data persistence in JavaScript by (1) a JavaScript persistent object pool and (2) a set of JavaScript persistent APIs. JSPMDK also provides engineers with strong support in guaranteeing data availability and consistency. The evaluation results show that JSPMDK is compatible to many existing JavaScript applications, yet helps increase their performance.
However, although it had been proved that JSPMDK outperforms MongoDB in specific situation, it has a poorer performance in others. For example, it is much slower than MongoDB on persisting a large object. Part of the reasons is that MongoDB use backend thread to flush the changes from memory to storage, while JSPMDK is blocked until the flush is done. In addition, we also think that the performance boost brought by JSPMDK is partially due to the removal of asynchronous operations. MongoDB in Node.js uses asynchronous read or write and handle the response in callback. In contrast, JSPMDK use synchronous operations which are blocked until they are done. So when the operations are fast enough, the overhead brought by asynchronous operations can actually reduce the performance. The discussion above require further experiments as validations, we would leave them as future work.
Acknowledgments
We would like to appreciate James Wu and his team, Lei Zhai and his team, Yongnian Le and his team, for their support and guidance to our work.
References
- Krishna Parat, "Non-Volatile Memory Technology," 23 August 2009.
- "Persistent Memory Development Kit (PMDK)".
- Rudoff, Andy. "Programming models for emerging non-volatile memory technologies." Retrieved February 23 (2013): 2015.
- "PyNVM: A Python Interface to PMDK".
- "Persistent Collections for Java*".
- Chodorow, Kristina. “MongoDB: The Definitive Guide: Powerful and Scalable Data Storage,” "O'Reilly Media, Inc.", 2013.