Introduction
Financial service customers are constantly in need of solutions to analyze market data as fast as possible. As such, there is a continual need to improve financial algorithmic performance. Finance algorithms include a wide range of models, including Monte Carlo, Black-Scholes, Bonds, and so on. Single Instruction Multiple Data (SIMD) vector programming can speed up the aforementioned workloads. Achieving optimal SIMD performance depends on efficient memory accesses. In this paper, we perform data layout optimizations using two approaches on a Black-Scholes workload for European options valuation from the open source Quantlib library. In the first approach, we manually hand-tune the data layout for best performance, whereas and in the second approach we use SIMD Data Layout Templates (SDLT) from the Intel® C++ compiler. In this work, we analyze an SDLT implementation and do a performance comparison of the two data layout optimization methods. The results show that SDLT performs equivalent to the hand-tuned optimized version. Additionally, SDLT offers performance with minimal code changes as compared to the hand-tune version, thereby maintaining the code readability of the original source code.
QuantLib Overview
Quantlib is a free, full-featured open source financial library written in C++. It consists of a number of modules with associated classes that enable users to quickly analyze financial Instruments (bonds, options, swaps, stock, and so on) by applying popular stochastic processes (Monte Carlo, Black-Scholes, Hull-White, Libor, and so on) and term structures (zero curve, ForwardRate, yield term, and so on). Many financial organizations use similar libraries that provide an equivalent set of concepts and APIs that are used in their application code.1
SDLT Overview
SIMD Data Layout Templates is a C++11 library that implements data layout optimizations abstracted from the user to facilitate vectorization. For example, the Intel® SDLT library provides an Array of Structure (AOS) interface to the user but stores the data in Structure of Array (SOA) format in memory. The library does not require any special compiler support to work, but because of its SIMD-friendly layout it can better take advantage of the Intel® C++ Compiler's performance features, that is, OpenMP* SIMD extensions, Intel® Cilk™ Plus SIMD extensions, and SIMD/IVDEP pragmas.2
Implementation
Quantlib library provides a unit test suite, which includes option valuation for European, American, and Bermudan options. In this paper, we exercise the European option valuation using the Black-Scholes model as a test case from the original Quantlib library. Black-Scholes is a closed-form financial derivative used for European option pricing valuation, which can be exercised only on the expiration date. The Black-Scholes test case is a single-precision 32-bit floating point implementation.
Quantlib library provides a unit test suite, which includes option valuation for European, American, and Bermudan options. In this paper, we exercise the European option valuation using the Black-Scholes model as a test case from the original Quantlib library. Black-Scholes is a closed-form financial derivative used for European option pricing valuation, which can be exercised only on the expiration date. The Black-Scholes test case is a single-precision 32-bit floating point implementation.
An emphasis was made to minimize the changes in the original open source Quantlib. However, the following changes were made:
- The Observable and Observed pattern was removed because inheritance was not pertinent to the test case.
- We used the original classes from Quantlib, so that the input parameters are now instances of different classes. A few of the data members from the original classes were eliminated as they were not a part of this test case.
- The implementation was changed to include multiple option evaluation, instead of single option to mimic real world scenarios.
To get the optimized hand-tuned version, we started by optimizing the C++ version. All the methods of the input classes were inlined. To introduce vectorization, we removed the switch statements and replaced them with if-else. The samples loop was vectorized using #pragma omp simd. This is a vectorized version but does not include any optimization for data layout. We observed that with no data layout optimization, the C++ vectorized version generates gathers, which reduce the efficiency of SIMD code, as will be explained in the later section.
To get the best performance from data layout optimization and to remove the C++ overhead, we used the flattened C version of the Black-Scholes model for European option valuation4. The flattened C version is originally obtained from the paper titled “Accelerating Financial Applications on the GPU”4. Intel further optimized the OpenMP version for Intel® architecture, provided in the aforementioned paper and published a new paper. In the flattened C version, the classes were mapped to structures.
Figure 1 illustrates the AOS layout of the input data structure in the C version, where the various input classes from the C++ version are represented by a single structure, and the data member are represented as members of the structure. For hand-tuned data layout optimizations, an array of structures was converted to structures of arrays shown in Figure 2. This optimization provides excellent cache locality, alignment, and unit stride access for the critical vector loop. Intel® Threading Building Blocks (Intel® TBB) memory allocator was used for memory allocation. The benefits of Intel TBB are two-fold: memory is allocated on cache-aligned boundaries and each thread has its own memory pool, which removes reliance on the global heap and improved NUMA locality. The details of the optimized C application and the source code can be found in the paper “Accelerating Financial Applications on Intel® Architecture”.3
typedef struct
{
int type;
float strike;
float spot;
float q;
float r;
float t;
float vol;
float tol;
} optionInputStruct;
optionInputStruct* values = new optionInputStruct[num_options];
Figure 1: Array of Structure layout in the original C version.
using namespace tbb;
typedef struct
{
int* type;
float* strike;
float* spot;
float* q;
float* r;
float* t;
float* vol;
float* tol;
}
/**Memory Allocation using TBB**/
optionInputStruct* values =(optionInputStruct*)scalable_aligned_malloc(sizeof(optionInputStruct),L1LINE_SIZE);
values->type=(int*)scalable_aligned_malloc(sizeof(int)*memsize,L1LINE_SIZE);
values->strike=(float*)scalable_aligned_malloc(sizeof(float)*memsize,L1LINE_SIZE);
values->spot=( float *)scalable_aligned_malloc(sizeof(float)*memsize,L1LINE_SIZE);
values->q=( float *)scalable_aligned_malloc(sizeof(float)*memsize,L1LINE_SIZE);
values->r=( float *)scalable_aligned_malloc(sizeof(float)*memsize,L1LINE_SIZE);
values->t=( float *)scalable_aligned_malloc(sizeof(float)*memsize,L1LINE_SIZE);
values->adj_t=( float *)scalable_aligned_malloc(sizeof(float)*memsize,L1LINE_SIZE);
values->vol=( float *)scalable_aligned_malloc(sizeof(float)*memsize,L1LINE_SIZE);
Figure 2: Structure of Array version in optimized C version.
For optimizing using SDLT, we used the optimized C++ version as the baseline. We used sdlt::soa1d_container, which is the template class for "Structure of Arrays" memory layout of a one-dimensional container of Primitives providing the following features:
- Dynamic resizing with an interface similar to std::vector
- Accessor objects suitable for efficient data access inside SIMD loops to structures.
Figure 3 shows the implementation of the soa1d container./**declaring sdlt SOA 1D container for engine class**/ typedef sdlt::soa1d_container<AnalyticEuropeanEngine> OptionContainer; /**Initializing SDLT Container**/ OptionContainer europeanOption(numVals); #pragma omp simd for (int i=0; i < numVals; ++i) { AnalyticEuropeanEngine localeuropeanOption = europeanOption[i]; output[i] = localeuropeanOption.calculate(); }Figure 3: soa1d container implementation.
We need to declare SDLT primitives to describe the data layout of any structures we want to place inside a SDLT container. The data structure must follow certain rules to be used as a primitive. We actually followed these rules when creating the previous optimized C++ version, enabling the compiler to generate efficient SIMD for local variable instances of primitives inside a loop.
To declare a primitive, use the helper macro SDLT_PRIMITIVE that accepts a struct type followed by a comma-separated list of its data members, as illustrated in Figure 4.
SDLT_PRIMITIVE( AnalyticEuropeanEngine, //engine class
process_, //Data member
payoff_, //Data member
exercise_); //Data member
Figure 4: SDLT_PRIMITIVE declaration.
We declared the data members as SDLT_PRIMITIVE_FRIEND, so SDLT can access the data members of the class. An alternative is to declare the data members as public.
class AnalyticEuropeanEngine {
.
.
.
SDLT_PRIMITIVE_FRIEND;
.
.
}
Figure 5: Declaring SDLT_PRIMITVE_FRIEND as friend class.
The changes mentioned in Figures 4 and 5 for introducing SDLT are applied to all the classes whose data is accessed in the vectorized code. No changes to class methods or algorithm code were necessary, unlike the flattened C version. The high-level algorithm is still readable and maintainable. The source code for the SDLT version can be found here.5
Results
This section describes the results for various combinations of samples and iterations tests. For completeness, we included a C++ unoptimized version and a vectorized C++ version results without any manual data layout changes, along with SDLT and best-optimized C version results. Table 1 shows the results for performance comparisons.
All times in seconds (lower is better)
| Test | Samples | Iterations | C++ Unoptimized Version | C++ Vectorized Version | C++ SDLT Version | C Flattened Optimized Version |
| 1 | 100,000 | 2048 | 20.7 | 2.1 | 1.7 | 1.7 |
| 2 | 100,000 | 4096 | 41.3 | 4.1 | 3.5 | 3.5 |
| 3 | 1,000,000 | 2048 | 217.1 | 33.3 | 17.3 | 17.4 |
| 4 | 1,000,000 | 4096 | 451.3 | 66.6 | 34.7 | 34.8 |
Table 1: Single-precision performance comparison results.
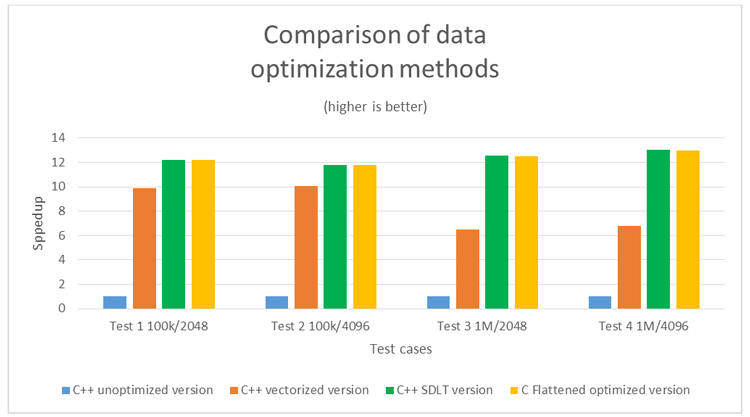
Figure 6: Speedup comparison of data optimization methods.
The C++ unoptimized version represents the baseline version with no vectorization gains. Introducing various optimizations discussed earlier gives a performance gain of up to ~10x. Data layout optimizations further improved performance by ~90 percent at higher input samples in this test case.
As shown in Table 1, SDLT performance is equivalent to the flattened optimized version. The vector report indicates that “gathers” are generated in the C++ vectorized version. The compiler generates “gather” instructions in a vector code, when the code performs non-unit strided memory accesses. In a gather instruction, data is loaded from memory to the vector register. Generally, a gather instruction is used to fetch data elements that are dispersed in memory. As a result, a latency is introduced while executing gathers, which reduces the overall performance of the application.
To get the best performance out of the C++ version, the gathers should be eliminated. This can be achieved by data layout changes. In the C++ version, the input data is spread across different classes. As a result, implementing data layout optimizations require significant changes to the original source code. This is validated as we move from C++ to C version to get the best performance. On the other hand, SDLT performs the data layout changes using templates, which are introduced in the original C++ code as demonstrated in Figures 3, 4, and 5.
Summary
Vectorization performance gains for any algorithm are tightly coupled to efficient data layout. This paper showed the performance impact of various data layout optimizations. The performance of a hand-tuned data layout optimized version was compared with the Intel® SDLT version. The performance of the SDLT approach is equivalent to a well-optimized version, which is basically a flattened C version with hand-tuned data layout changes. Note that changes implemented for introducing the SDLT require minimal changes to the original source code. On the other hand, manual data layout changes require significant code changes to achieve the best performance. Along with SOA data layout, SDLT implements aligned memory allocation and provides alignment hints to the compiler for additional optimization, hidden from the user. Therefore, the user just needs to introduce the SDLT templates as discussed earlier unlike in the hand-tuned version, where the user has to explicitly implement AOS to SOA conversions and also align the data for better performance.
About the Authors
Nimisha Raut received a Master’s degree in Computer Engineering from Clemson University and a Bachelor’s degree in Electronics Engineering from Mumbai University, India. She is currently a software engineer with Intel’s Financial Services Engineering team within Software and Services Group. Her major interest is parallel programming and performance analysis on Intel® processors and coprocessors and Nvidia* GPGPUs.
Alex Wells is a Senior Application Engineer in the Intel Technical Computing Engineering team. Alex leads enabling data-parallelism in animation film tools, specifically characters. He architected Intel SIMD Data Layout Templates as well as the open source project, XForm Building Blocks. Previous to joining Intel, Alex developed games, co-architected a cross-platform 3D engine in C++, and is alumnus of University of California, Santa Barbara.