
Continuous Delivery (CD) and Continuous Integration (CI) are two related and important concepts in modern software engineering and software product development. Doing integration is a prerequisite to doing delivery and deployment, and getting a CI flow in place is often the hardest part of getting to CD. Doing CI for general-purpose software on a general-purpose computer like a server or web system is comparatively straight-forward, but doing it for embedded systems is a bit more difficult. I recently found a very good technical talk online on the topic of Continuous Delivery for embedded systems, and how to achieve it. One thing I did notice was the obvious role and need for simulation in such a development and testing flow.
Mike Long’s (Inspiring) Talk
The talk that inspired me to revisit this topic is called “Continuous Delivery of Embedded Systems”, and can be found at at Vimeo. The speaker is Mike Long from Praqma*, a Scandinavian consulting house in software delivery with a focus on embedded systems. It is a very good introduction to the topic. I recommend looking at the talk before continuing.
![]()
You did look at it, right?
To me, the key take away from the talk is that tools and processes matter greatly, and that embedded systems can benefit from good processes enabled by the right tools just as much as any other area of software development. The key is to find tools and build flows that work for systems that by definition have a broad interface to their environment. Many of his points are familiar, and he also had some good new observations.
Main Points
Mike Long’s most important message is really that software development methods and tools matter, and that being “embedded” is no excuse not to work in a modern and efficient way. In his experience, quite a lot of embedded software is done as an unimportant afterthought to the development of the physical system. He talks about developers not using version control or automated build system. Instead they make a copy of the existing source code as the starting point for the next product, build their binaries on their laptop, and simply deliver the resulting binary to the production system. Going back to reproduce a previous version is impossible, and each delivery requires a lot of manual work.
This kind of system is not exactly a scalable system that promotes software quality. What any embedded software organization (actually, any software organization) should do is to set up a CI system.
It is not really what I am used to seeing. It appears that I have had the fortune to talk to sophisticated embedded systems companies that do have CI in place for their software, and are using continuous delivery and even continuous deployment to increase the customer value of the systems they are providing. It takes work to get there, but it is worth it. There are some tooling issues that come up, which I will get back to.
Mike Long’s view of CI for embedded systems is that you have an individual developer step where you do basic integration after a commit, and then you do the main CI flow asynchronously. He sketches a flow that looks like this (redrawn from the illustrations shown in the video):
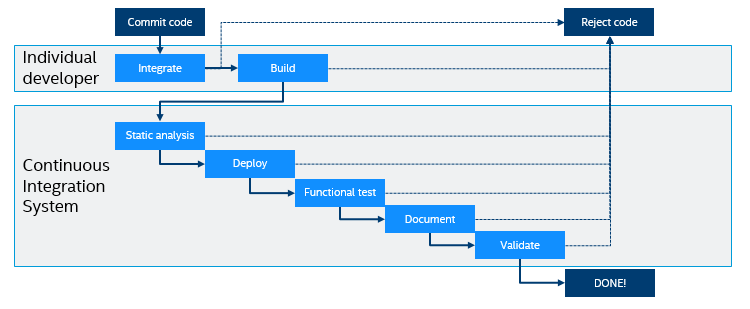
An important point that I had not thought much about before is that the commit and basic code integration (merge) and build have to be decoupled from the main CI flow. The main CI pipeline can take hours or even days to run for a commit, and you would not want to block a developer for that long.
I find it refreshing to see static analysis and documentation shown as phases in the continuous integration pipeline. I myself have tended to focus mostly on running code in various contexts, but the approach presented here goes beyond to include more techniques to improve software quality (static analysis) as well as the steps needed to make the software ready for delivery (documentation and final validation).
However, I can see a risk if the testing pipeline gets too long – that developers keep integrating code that eventually gets rejected. We once saw this at a customer, where the validation testing took a week to run on hardware. This meant that problems kept being reintroduced and caught in regression testing, since the testing results came back too late to help.
The key to avoiding that is doing things in an order that will produce feedback as soon as possible. In this case, starting with static analysis will likely find lots of small issues early on. Once that is passed, going to deployment to a test system and running all the functional tests will find code-level issues as soon as reasonably feasible. This means that code-related feedback will be sent to the developers as soon as feasible.
Documentation and final validation only happens once the code itself has passed functional tests and is fairly solid. Issues found there are likely to be higher-level and not necessarily related to a small code change. The later stages of any CI pipeline are likely to take days or even weeks, depending on the requirements of the domain.
Tooling Up to Solve the Hardware Problem
A core part of the problem as described by Mike Long is that a developer needs access to "production-like environment". You want to make sure software can be flashed and booted on the real thing – but in practice, hardware will be late, or prototype stage, or flaky, or all of the above. This is one of the problems where virtual platforms can really make a difference – they provide a stable execution platform that is close enough to the real platform that functional tests can be run using the real code.
Once code is running, the next part of CI for embedded software is to make sure the code gets reasonable inputs from the world. Embedded software not only involves communicating with other code or other computer systems, but also an environment via sensors and other interfaces. Tests need to send representative data to the system under test, via the hardware interfaces used in the real system.
Thus, real-world physical test labs for embedded systems need to deal with several unique challenges:
- Making the right hardware available to run tests on – need to know what you can run on that makes sense
- Loading software onto the hardware – which can be easy or hard depending on the nature of the software stack on the hardware
- Integrating the environment – you need to provide reasonable stimuli to the hardware to make the code believe it is running in the real world and observe its reactions to the real-world situation
A typical hardware lab setup looks like this:
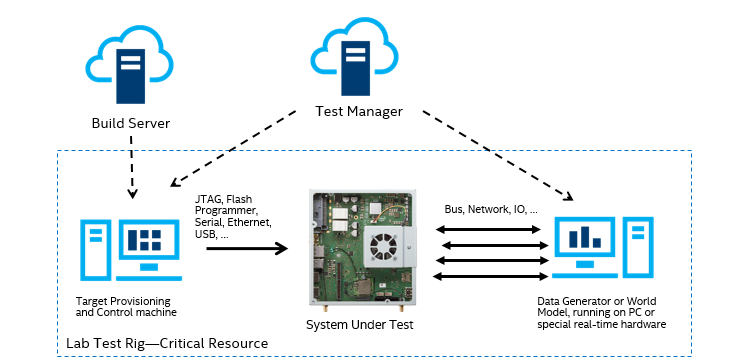
You have special hardware to run tests on, and you need two more machines. One to control and provision the system under test, and one to provide the various inputs it needs. As Mike Long notes, sometimes you add stubs to the software under test to simplify the work of the data generator. But you cannot get away from the need to provide some kind of stimulus from a simulation. You cannot in general just put the system into its real-world context to test it – such testing is typically hard, dangerous, contrary to industry regulations, or impossible to squeeze into a lab. The external environment (the world) just has to be simulated.
By combining the world simulation with a virtual platform model of the system hardware, we can turn the entire setup into a software workload that can run on any server or PC.
Like this:
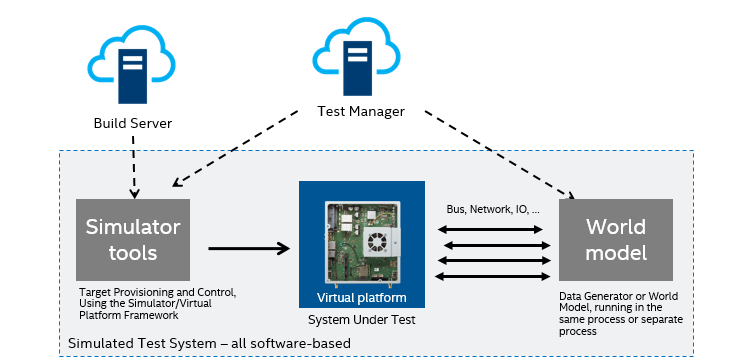
This makes hardware availability issues mostly go away, and makes tests much more reliable. Even if the simulation setup is an amalgamation of many separate simulators, as long as it is all software, it is possible to automate and control it in a way that is just not feasible for pure hardware.
A software simulation like this can be scaled up in a way that hardware labs cannot– each hardware lab instance has to be built and maintained. A software simulation can be replicated onto more servers or PCs very easily, increasing test system availability to the point where it does not slow down progress. If test system availability is a limiting factor for testing, you will naturally have to test less in order to ensure progress. This leads to worse software due to having to limit testing and test coverage to squeeze the test runs into the available test execution time budget.
This is what the users I talked about before with the week-long regression testing did – they used many virtual platform instances in parallel to remove the execution platform as the bottleneck. This enabled them to run through a complete regression suite overnight instead of over a week. In this way, the window to reintroduce errors was reduced, leading to much less frustration among the developers and higher code quality.
More Variation
Regardless of the use of physical or virtual platforms, using simulation to generate the real-world stimulus opens up for testing scenarios that would be hard to get in the real world. Simulation lets you break out of the narrow set of scenarios you could induce in the final system, as well as to replicate strange situations that have been observed in the real world.
As I described in a previous blog:
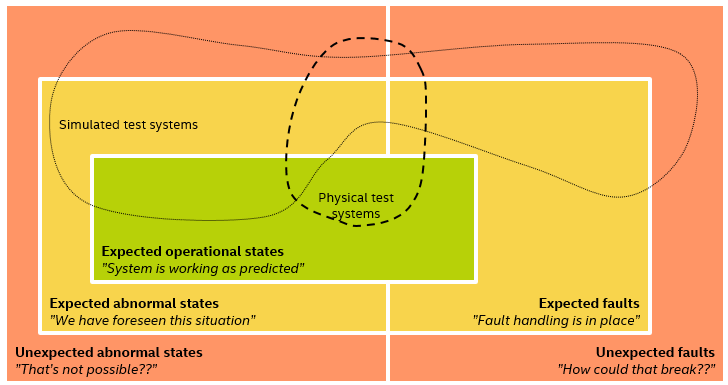
Note that simulation does not have to be software-based… Mike Long points to a cute hardware simulator built using LEGO* Mindstorms*, and used to test a small radar sensor in a repeatable fashion. However, if you put that into the lab, you are back to having a few hardware resources as a testing bottleneck – but then again, you can now test the electronics of the real thing, which is necessary for final validation and testing.
In general, bouncing back and forth between the real world, simulated physical systems, and software-based simulation provides the richest possible test environment. Software-based simulation allows software testing to expand and become entirely automated, while hardware-based simulation is necessary to test the final hardware and software together.
Another variation aspect that Mike Long mentions is the use of multiple different compilers in the build as a way to improve code quality – a long-standing favorite technique of mine. You want to inject variation anywhere you can – but variation that is predictable and repeatable.
Final Notes
I have written rather extensively about how virtual platforms and software simulation simplifies continuous integration for embedded systems. I found this particular talk from Mike Long to be a very good exposition of the importance of CI and CD, with lots of anecdotes and real-world examples from various companies. Towards the end, he talks about how Tesla is able to quickly deploy new software to their cars, taking the software from continuous delivery to continuous deployment thanks to having an update mechanism in place and a user base that accepts ongoing updates.
Moving to continuous delivery is a key competitive advantage for embedded systems. As more and more systems get connected, being able to easily deploy updated software is going to go from a nice bonus to expected feature. Just like it is already expected for desktop and mobile apps and operating systems. Being in a CD flow makes for happier developers, and makes it easier to attract key talent.
To make that work, testing embedded software has to go from a complete dependency on hardware to simulation and virtual platforms. Not just for early software development, but for the entire lifecycle of a product.