Introduction to Vhost/Virtio
Vhost/virtio is a semi-virtualized device abstract interface specification that has been widely applied in QEMU* and kernel-based virtual machines (KVM). It is usually called virtio when used as a front-end driver in a guest operating system or vhost when used as a back-end driver in a host. Compared with a pure software input/output (I/O) simulation on a host, virtio can achieve better performance, and is widely used in data centers. Linux* kernel has provided corresponding device drivers, which are virtio-net and vhost-net. To help improve data throughput performance, the Data Plane Development Kit (DPDK) provides a user state poll mode driver (PMD), virtio-pmd, and a user state implementation, vhost-user. This article will describe how to configure and use vhost/virtio using a DPDK code sample, testpmd. Performance numbers for each vhost/virtio Rx/Tx path are listed.
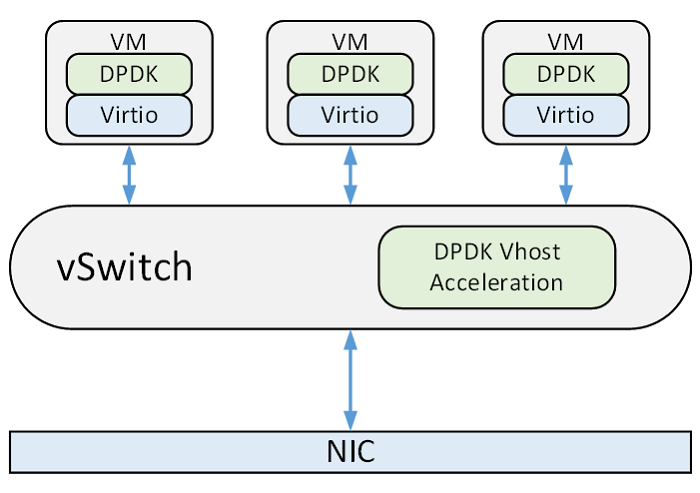
A typical application scenario with virtio
Receive and Transmit Paths
In DPDK’s vhost/virtio, three Rx (receive) and Tx (transmit) paths are provided for different user scenarios. The mergeable path is designed for large packet Rx/Tx, the vector path for pure I/O forwarding, and the non-mergeable path is the default path if no parameter is given.
Mergeable Path
The advantage of using this receive path lies in that the vhost can organize the independent mbuf in an available ring into a linked list to receive packets of larger size. This is the most widely adopted path, as well as the focus of performance optimization of the DPDK development team in recent months. Receive and transmit functions used by this path are configured as follows:
eth_dev->tx_pkt_burst = &virtio_xmit_pkts;
eth_dev->rx_pkt_burst = &virtio_recv_mergeable_pkts;The path can be started by setting the flag VIRTIO_NET_F_MRG_RXBUF during the connection negotiation between the vhost and QEMU. Vhost-user supports this function by default and the commands for enabling this feature in QEMU are as follows:
qemu-system-x86_64 -name vhost-vm1
…..-device virtio-net-pci,mac=52:54:00:00:00:01,netdev=mynet1,mrg_rxbuf=on \
……
DPDK will choose the corresponding Rx functions according to the VIRTIO_NET_F_MRG_RXBUF flag:
if (vtpci_with_feature(hw, VIRTIO_NET_F_MRG_RXBUF))
eth_dev->rx_pkt_burst = &virtio_recv_mergeable_pkts;
else
eth_dev->rx_pkt_burst = &virtio_recv_pkts;
The difference between the mergeable path and the two other paths is that the value of rte_eth_txconf->txq_flags won’t be affected as long as mergeable is on.
Vector Path
This path utilizes single instruction, multiple data (SIMD) instructions in the processor to vectorize the data Rx/Tx actions. It has better performance in pure I/O packet forwarding scenarios. The receive and transmit functions of this path are as follows:
eth_dev->tx_pkt_burst = virtio_xmit_pkts_simple;
eth_dev->rx_pkt_burst = virtio_recv_pkts_vec;
Requirements for using this path include:
- The platform processor should support the corresponding instruction set. The x86 platform should support Streaming SIMD Extensions 3(SSE3), which can be examined by rte_cpu_get_flag_enabled (RTE_CPUFLAG_SSE3) in DPDK. The ARM* platform should support NEON*, which can be examined by rte_cpu_get_flag_enabled (RTE_CPUFLAG_NEON) in DPDK.
- The mergeable path in the Rx side should be closed, which can be examined by the function in DPDK. The command to shut down this function is as follows:
qemu-system-x86_64 -name vhost-vm1 ….. -device virtio-net-pci,mac=52:54:00:00:00:01,netdev=mynet1,mrg_rxbuf=off \ …… - The Offload function, which includes VLAN offload, SCTP checksum offload, UDP checksum offload, and TCP checksum offload, is not enabled.
- rte_eth_txconf->txq_flags need to be set to 1. For example, in the testpmd sample provided by DPDK, we can configure virtio devices in the virtual machine with the following command:
testpmd -c 0x3 -n 4 -- -i --txqflags=0xf01
It can be seen that the function of the vector path is relatively limited, which is why it didn’t become a key focus of DPDK performance optimization.
Non-mergeable Path
The non-mergeable path is rarely used. Here are its receive and transmit paths:
eth_dev->tx_pkt_burst = &virtio_xmit_pkts;
eth_dev->rx_pkt_burst = &virtio_recv_pkts;
The following configuration is required for the application of this path:
- Mergeable closed in Rx direction.
- rte_eth_txconf->txq_flags need to be set to 0. For example, in testpmd, we can configure virtio devices in the virtual machine with the following commands:
#testpmd -c 0x3 -n 4 -- -i --txqflags=0xf00
PVP Path Performance Comparisons
Performance of the different DPDK vhost/virtio receive and transmit paths are compared using a Physical-VM-Physical (PVP) test. In this test, testpmd is used to generate the vhost-user port as follows:
testpmd -c 0xc00 -n 4 --socket-mem 2048,2048 --vdev 'eth_vhost0,iface=vhost-net,queues=1' -- -i --nb-cores=1
In the VM, testpmd is used to control the virtio device. The test scenarios are shown in the diagram below. The main purpose is to test the north-south data forwarding capability in a virtualized environment. An Ixia* traffic generator sends the 64 byte packet to the Ethernet card at a wire-speed of 10 gigabits per second, the testpmd in the physical machine calls vhost-user to forward packets to the virtual machine, and the testpmd in the virtual machine calls virtio-user to send the packet back to the physical machine and finally back to Ixia. Its send path is as follows:
IXIA→NIC port1→Vhost-user0→Virtio-user0→NIC port1→IXIA
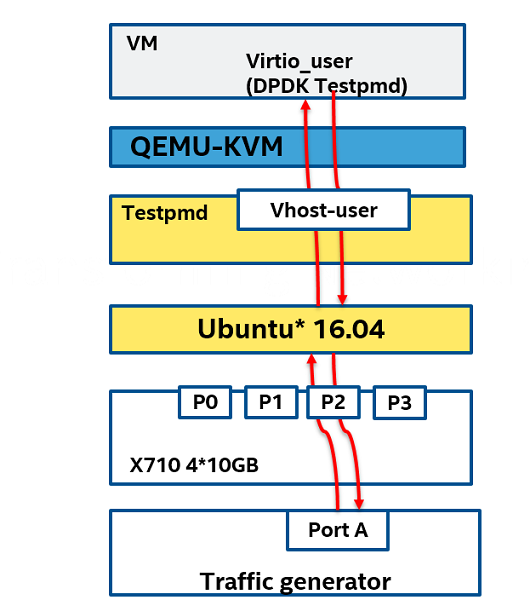
The send path
I/O Forwarding Throughput
Using DPDK 17.05 with an I/O forwarding configuration, the performance of different paths is as follows:
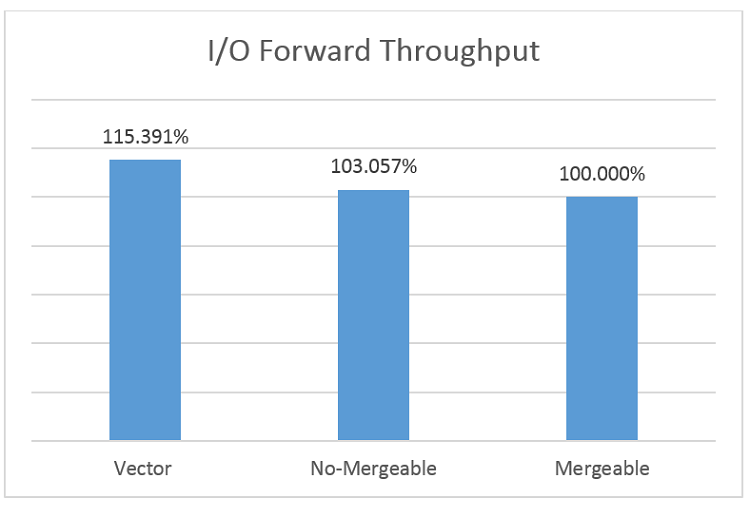
I/O Forwarding Test Results
In the case of pure I/O forwarding, the vector path has the best throughput, almost 15 percent higher than mergeable.
Mac Forwarding Throughput
Under the MAC forwarding configuration, the forwarding performance of different paths is as follows:
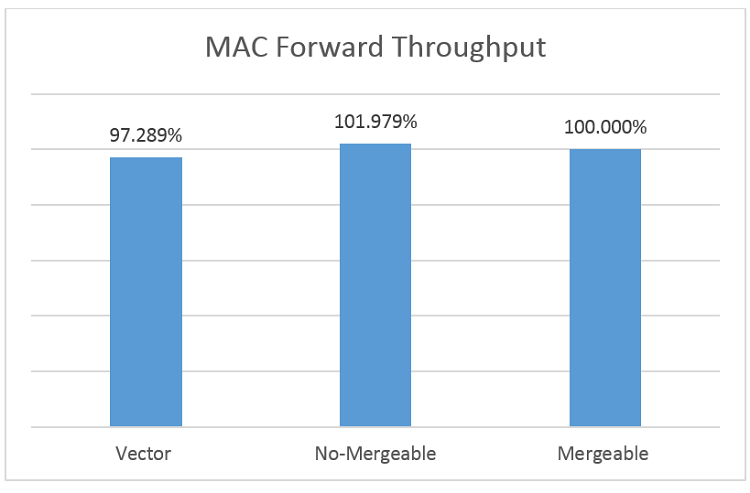
MAC Forwarding Test Results
In this case, performance of the three paths is almost the same. We recommend using the mergeable path because it offers more function.
PVP MAC Forwarding Throughput
The chart below shows the forwarding performance trend of PVP MAC on the x86 platform starting with DPDK 16.07. Because of the mergeable path’s broader application scenarios, DPDK engineers have been optimizing it since then, and the performance of PVP has improved by nearly 20 percent on this path.
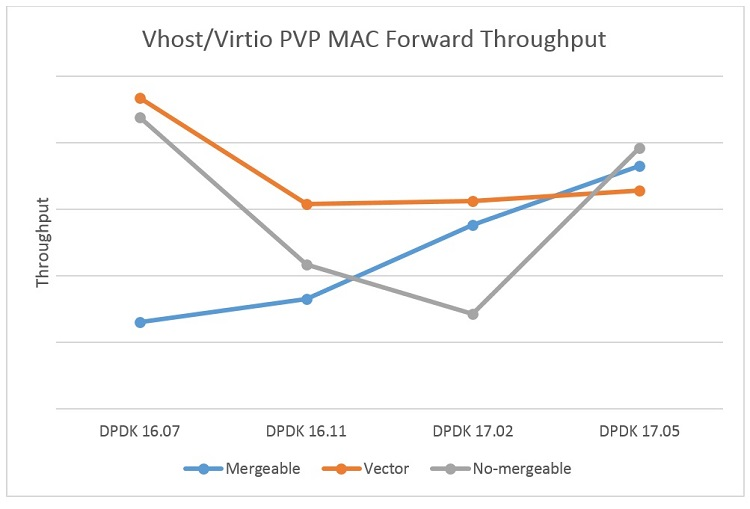
PVP MAC Forwarding Test Results
Note: The performance drop on DPDK 16.11 is mainly due to the overhead brought by the new features added, such as vhost xstats and the indirect descriptor table.
Test Bench Information
CPU: Intel® Xeon® CPU E5-2680 v2 @ 2.80GHz
OS: Ubuntu 16.04
About the Author
Yao Lei is an Intel software engineer. He is mainly responsible for the DPDK virtualization testing-related work.
Notices
Software and workloads used in performance tests may have been optimized for performance only on Intel microprocessors. Performance tests, such as SYSmark* and MobileMark*, are measured using specific computer systems, components, software, operations and functions. Any change to any of those factors may cause the results to vary. You should consult other information and performance tests to assist you in fully evaluating your contemplated purchases, including the performance of that product when combined with other products.
For more information go to http://www.intel.com/performance.
Intel technologies’ features and benefits depend on system configuration and may require enabled hardware, software or service activation. Performance varies depending on system configuration. Check with your system manufacturer or retailer or learn more at intel.com.