Introduction
Message passing interface (MPI) is a programing model that can run a multiprocessor program in a distributed computing environment. With the introduction of the Intel® oneAPI DPC++/C++ Compiler, developers can write a single source code that can be run on a wide variety of platforms including CPU, GPU, and FPGA. By combining MPI and SYCL language, developers can take advantage of scaling across diverse platforms while running the application in a distributed computing environment. This article shows developers an example of this combination, how to compile the MPI application with the DPC++ compiler, and how to run it on a Linux* operating system.
Integrating MPI and DPC++
The code sample gives an example of combining MPI code and DPC++ code. The application is basically an MPI program computing the number Pi (π) by dividing the work equally to all the MPI processes (or ranks). The number Pi can be computed by applying its integral representation:
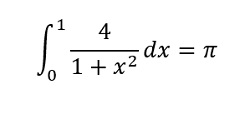
Each MPI rank computes a partial result of the number Pi according to the above formula. At the end of the computation, the MPI primary rank adds all the partial results from other ranks, and then prints the results. The source code is part of the Samples for the Intel oneAPI Toolkit Samples, and can be downloaded from GitHub* (released under MIT License). The source code sample illustrates different approaches, including MPI, to calculate the number Pi. This article focuses on the MPI implementation, the mpi_native function.
In the main function, DPC++ functionality is started when a device queue is created. Host code uses the queue myQueue to submit the device code to a device for execution. This example uses a default selector so that SYCL* runtime would select the best device on the system. The SYCL runtime tracks and initiates the work.
int main(int argc, char** argv) {
int num_steps = 1000000;
int groups = 10000;
char machine_name[MPI_MAX_PROCESSOR_NAME];
int name_len=0;
int id=0;
int num_procs=0;
float pi=0.0;
queue myQueue{property::queue::in_order()};
auto policy = oneapi::dpl::execution::make_device_policy(
queue(default_selector{}, dpc_common::exception_handler));
// Start MPI.
if (MPI_Init(&argc, &argv) != MPI_SUCCESS) {
std::cout << "Failed to initialize MPI\n";
exit(-1);
}
// Create the communicator, and retrieve the number of MPI ranks.
MPI_Comm_size(MPI_COMM_WORLD, &num_procs);
// Determine the rank number.
MPI_Comm_rank(MPI_COMM_WORLD, &id);
// Get the machine name.
MPI_Get_processor_name(machine_name, &name_len);
std::cout << "Rank #" << id << " runs on: " << machine_name
<< ", uses device: "
<< myQueue.get_device().get_info<info::device::name>() << "\n";
Next, the program runs an MPI initialization MPI_Init. MPI_Comm_size and reports the number of processes created. Each MPI process gets its process number and the name of the processor by calling MPI_Comm_rank and MPI_Get_processor_name, respectively.
To compute the partial result of the number Pi, each MPI rank calls the mpi_native function as shown in the following main function:
int num_step_per_rank = num_steps / num_procs;
float* results_per_rank = new float[num_step_per_rank];
// Initialize an array to store a partial result per rank.
for (size_t i = 0; i < num_step_per_rank; i++) results_per_rank[i] = 0.0;
dpc_common::TimeInterval T6;
// Calculate the Pi number partially by multiple MPI ranks.
mpi_native(results_per_rank, id, num_procs, num_steps, myQueue);
float local_sum = 0.0;
// Use the DPC++ library call to reduce the array using plus
buffer<float> calc_values(results_per_rank, num_step_per_rank);
auto calc_begin2 = oneapi::dpl::begin(calc_values);
auto calc_end2 = oneapi::dpl::end(calc_values);
local_sum =
std::reduce(policy, calc_begin2, calc_end2, 0.0f, std::plus<float>());
// Master rank performs a reduce operation to get the sum of all partial Pi.
MPI_Reduce(&local_sum, &pi, 1, MPI_FLOAT, MPI_SUM, master, MPI_COMM_WORLD);
if (id == master) {
auto stop6 = T6.Elapsed();
std::cout << "mpi native:\t\t";
std::cout << std::setprecision(3) << "PI =" << pi;
std::cout << " in " << stop6 << " seconds\n";
}
delete[] results_per_rank;
The following mpi_native function is written in DPC++. This function takes five arguments:
- results (points to the array of results of each compute unit)
- rank_num (the MPI rank number)
- num_procs (the number of MPI processes)
- total_num_steps (the number of points)
- q (the queue)
Each DPC++ host code, executed by the MPI rank on the host, launches the SYCL application. The host code orchestrates data movement and computes offload to devices.
void mpi_native(float* results, int rank_num, int num_procs,
long total_num_steps, queue& q) {
float dx, dx2;
dx = 1.0f / (float)total_num_steps;
dx2 = dx / 2.0f;
default_selector device_selector;
try {
// The size of amount of memory that will be given to the buffer.
range<1> num_items{total_num_steps / size_t(num_procs)};
// Buffers are used to tell SYCL which data will be shared between the host
// and the devices.
buffer<float, 1> results_buf(results,
range<1>(total_num_steps / size_t(num_procs)));
// Submit takes in a lambda that is passed in a command group handler
// constructed at runtime.
q.submit([&](handler& h) {
// Accessors are used to get access to the memory owned by the buffers.
accessor results_accessor(results_buf,h,write_only);
// Each kernel calculates a partial of the number Pi in parallel.
h.parallel_for(num_items, [=](id<1> k) {
float x = ((float)rank_num / (float)num_procs) + (float)k * dx + dx2;
results_accessor[k] = (4.0f * dx) / (1.0f + x * x);
});
});
} catch (...) {
std::cout << "Failure" << std::endl;
}
}
In the try block, a buffer object is created to connect data between the host and the device. Buffers provide an abstract view of memory. The buffer results_buf is created to store data of results.
The command group is then submitted to the queue q created. The command group takes handler h that contains all requirement for a kernel to execute.
Because the host and device cannot access the buffer directly, the results_accessor accessor is created to allow the device to write to the results_buf buffer.
The parallel_for function expresses the basic kernels that creates the number of instances that are executed in parallel in the device. The function takes two arguments: num_items specifying the number of steps to launch, and the kernel function to be executed in each index. Each instance computes a single value of the result and writes to the results_buf buffer. The SYCL runtime then copies the results to the results array in the host. This completes the computation of a partial of the number Pi for each MPI rank.
Finally, the primary MPI rank sums all partial results from all the MPI ranks in the main() function.
Compile and Run MPI/DPC++ Program in Linux
This section describes how to compile and run the program in Linux. For the purpose of this test, two Intel® systems are used. These systems are powered by Intel® Iris® Pro Graphics 580, an Intel® Core™ i7 processor, and they run Ubuntu* 18.04. Note that Intel Iris Pro Graphics 580 is a version of Intel® Processor Graphics Gen9 that is supported by Intel® oneAPI Toolkits. The host names of these systems are host1 and host2 with IP addresses 10.54.72.150 and 10.23.3.154, respectively.
The following steps explain how to compile and run an MPI program written with DPC++:
- Install Intel® oneAPI Base Toolkit and Intel® oneAPI HPC Toolkit, which includes Intel® C++ Compiler and Intel® MPI Library. For the purpose of this article, the Gold version is used for testing. Any version later than the Gold version should work with this code sample.
In this example, Intel oneAPI is installed in both machines in the default path /opt/intel/. - Disable the firewall on the machine where the MPI program started.
$ sudo ufw disable Firewall stopped and disabled on system startup $ sudo ufw status Status: inactive - Set up the password-less SSH login on these two machines.
- Set up the oneAPI environment variables.
To generate an executable from the code sample, you need to source the oneAPI script in the host where you run the program.$ source /opt/intel/inteloneapi/setvars.sh - Compile the MPI program.
After you set up the environment variables, use the mpiicpc script to compile and link MPI programs written in C++. The script provides the options and special libraries needed for MPI programs.
This script uses the Intel® C++ Compiler (mpicc that resides in the oneAPI HPC toolkit). The command mpiicpc is the Intel® MPI Library compiler command for Intel® C++ Compiler. The -show option displays how the underlying Intel® C++ Compiler. It also shows the required compiler flags and options when running the following command:
The previous command displays the command lines if you invoke the mpiicpc script for a C++ program. The Intel® C++ Compiler icpc is used to compile and link the C++ program.$ mpiicpc -show icpc -I'/opt/intel/oneapi/mpi/2021.1.1/include' -L'/opt/intel/oneapi/mpi/2021.1.1/lib/release' -L'/opt/intel/oneapi/mpi/2021.1.1/lib' -Xlinker --enable-new-dtags -Xlinker -rpath -Xlinker '/opt/intel/oneapi/mpi/2021.1.1/lib/release' -Xlinker -rpath -Xlinker '/opt/intel/oneapi/mpi/2021.1.1/lib' -lmpicxx -lmpifort -lmpi -ldl -lrt -lpthread
On the other hand, Intel® oneAPI DPC++ compiler dpcpp must be used to compile DPC++ programs. DPC++ consists of C++ with SYCL and extensions. To compile and link MPI programs written in DPC++, you need to replace icpc with dpcpp in the previous command. For this particular program, there are other functions that use Intel® oneAPI Threading Building Blocks (oneTBB), and hence, you also need to link with the oneTBB library (-ltbb):
Alternately, you can also compile the MPI program with the following commands:$ dpcpp -I'/opt/intel/oneapi/mpi/2021.1.1/include' -L'/opt/intel/oneapi/mpi/2021.1.1/lib/release' -L'/opt/intel/oneapi/mpi/2021.1.1/lib' -Xlinker --enable-new-dtags -Xlinker -rpath -Xlinker '/opt/intel/oneapi/mpi/2021.1.1/lib/release' -Xlinker -rpath -Xlinker '/opt/intel/oneapi/mpi/2021.1.1/lib' -lmpicxx -lmpifort -lmpi -ldl -lrt -lpthread -ltbb main.cpp -o dpc_reduce
The previous commands show how to compile an MPI program written in SYCL called main.cpp. The flag -o specifies the name of executable file dpc_reduce.$ export I_MPI_CXX=dpcpp $ mpiicpc -fsycl -std=c++17 -lsycl -ltbb main.cpp -o dpc_reduce - Transfer the executable file to the other machine.
As you run the command on one host (host1 in this case), you need to transfer the executable file to the other host (host2 whose IP address is 10.23.3.154):$ scp dpc_reduce 10.23.3.154:~/ - Run the MPI executable in a two-node cluster using the mpirun command.
Now, you can run the executable on both hosts. The option -n specifies the number of MPI ranks per node. The option -host specifies the host where the MPI ranks are running. The colon “:” separates the two nodes (host1 and host2). The following command runs one MPI rank on the first host host1 and one MPI rank on the second host host2. Each MPI rank calculates a partial result of the number Pi by using Data Parallel C++. The SYCL runtime chooses the best available device to offload the kernel. In this case, the SYCL runtime chooses the GPU available on both systems to execute the kernels in parallel.$ mpirun -n 1 -host localhost ./dpc_reduce : -n 1 -host 10.23.3.154 ./dpc_reduce Rank #1 runs on: host2, uses device: Intel(R) Graphics [0x591b] Rank #0 runs on: host1, uses device: Intel(R) Graphics [0x193b] Number of steps is 1000000Cpu Seq calc: PI =3.14 in 0.00973 seconds Cpu TBB calc: PI =3.14 in 0.00239 seconds oneDPL native: PI =3.14 in 0.261 seconds oneDPL native2: PI =3.14 in 0.215 seconds oneDPL native3: PI =3.14 in 0.0038 seconds oneDPL native4: PI =3.14 in 0.00769 seconds oneDPL two steps: PI =3.14 in 0.002 seconds oneDPL transform_reduce: PI =3.14 in 0.0013 seconds mpi native: PI =3.14 in 0.243 seconds mpi transform_reduce: PI =3.14 in 0.0011 seconds successYou can run the executable with other MPI environment variables. For example, to print debugging information, you can set the I_MPI_DEBUG=<level> environment variable:
$ I_MPI_DEBUG=5 mpirun -n 1 -host localhost ./dpc_reduce : -n 1 -host 10.23.3.82 ./dpc_reduce [0] MPI startup(): Intel(R) MPI Library, Version 2021.1 Build 20201112 (id: b9c9d2fc5) [0] MPI startup(): Copyright (C) 2003-2020 Intel Corporation. All rights reserved. [0] MPI startup(): library kind: release [0] MPI startup(): libfabric version: 1.11.0-impi [0] MPI startup(): libfabric provider: tcp;ofi_rxm [0] MPI startup(): Rank Pid Node name Pin cpu [0] MPI startup(): 0 31373 host1 {0,1,2,3,4,5,6,7} [0] MPI startup(): 1 2659783 host2 {0,1,2,3,4,5,6,7} [0] MPI startup(): I_MPI_ROOT=/opt/intel/oneapi/mpi/2021.1.1 [0] MPI startup(): I_MPI_MPIRUN=mpirun [0] MPI startup(): I_MPI_HYDRA_TOPOLIB=hwloc [0] MPI startup(): I_MPI_INTERNAL_MEM_POLICY=default [0] MPI startup(): I_MPI_DEBUG=5 Rank #1 runs on: host2, uses device: Intel(R) Graphics [0x591b] Rank #0 runs on: host1, uses device: Intel(R) Graphics [0x193b] Number of steps is 1000000 Cpu Seq calc: PI =3.14 in 0.01 seconds Cpu TBB calc: PI =3.14 in 0.00249 seconds oneDPL native: PI =3.14 in 0.26 seconds oneDPL native2: PI =3.14 in 0.205 seconds oneDPL native3: PI =3.14 in 0.00318 seconds oneDPL native4: PI =3.14 in 0.00601 seconds oneDPL two steps: PI =3.14 in 0.00224 seconds oneDPL transform_reduce: PI =3.14 in 0.000841 seconds mpi native: PI =3.14 in 0.228 seconds mpi transform_reduce: PI =3.14 in 0.000803 seconds success
Summary
DPC++ allows you to reuse code across hardware targets such as CPU, GPU, and FPGA. To take advantage of this feature, MPI programs can incorporate DPC++. This article shows developers how to compile and run MPI/DPC++ programs using the Intel® oneAPI DPC++/C++ Compiler.