Introduction
Rapid advancements in generative AI (GenAI) have led to countless new ways for companies to interact with and drive value from their data. Large language models (LLM) have become adept at generating meaningful output for virtually any multimodal input. Embedding models and vector databases have made it possible to use LLMs for even the most niche applications by "grounding" the model's responses with data specific to the use case.
A popular application of this is retrieval augmented generation (RAG). RAG involves retrieving relevant documents through a semantic search over their embedding representations. These documents are then used as added context to the LLM prompt. While the value brought from techniques like RAG can be immense, building them requires developers to be up-to-date with a constantly evolving GenAI stack.
Learn how GenAI solutions like RAG can be simplified with Google Cloud* AlloyDB service and the 4th and 5th generations of Intel® Xeon® Scalable processors. AlloyDB is a PostgreSQL-compatible database service with built-in generative AI capabilities. A downloadable version, AlloyDB Omni, is available: It lets you deploy a streamlined edition of AlloyDB in your own computing environment.
While its integrations with popular GenAI services and tools can make it easier to build and iterate on your GenAI solutions, performance boosts from the Intel® Advanced Matrix Extensions (Intel® AMX) accelerator allow you to run your embedding generation and search directly on 4th and 5th generation Intel® Xeon® processors. Andi Gutmans, general manager of databases at Google Cloud* enterprise services, highlights its importance: "The combination of powerful embedding models with vector search and indexing is emerging as a critical component for building GenAI apps. It's great to see how Intel's new architectures are enabling the generation of CPU embeddings, giving AlloyDB customers the opportunity to generate their own embeddings in any environment without the need for specialized hardware."
What is AlloyDB?
AlloyDB is a PostgreSQL-compatible database service on Google Cloud. It provides superior performance compared to standard PostgreSQL with 4x better performance for transactional workloads, up to 100x faster analytical queries, and up to 4x faster vector queries. While it can be used as a fully managed service backed by the infrastructure of Google Cloud, AlloyDB also offers a portable, containerized version that can be run virtually anywhere outside of the cloud. The portability of AlloyDB Omni lets it run in a wide variety of environments, including data centers, cloud-based virtual machine (VM) instances, and laptops. AlloyDB Omni is well suited to run in multiple public clouds or hybrid environments with both private and public clouds.
Both AlloyDB and AlloyDB Omni offer built-in generative AI capabilities including:
- Pgvector integration for storing and searching embedding data
- Integration with popular GenAI tools such as LangChain*
- Integration with Vertex AI* to register and call Google-hosted models
-
Ability to register and call custom embedding models
AlloyDB AI and Vector Search
AlloyDB AI is based on the pgvector extension for PostgreSQL. The integration of pgvector into AlloyDB allows you to work with vector embeddings, which are essential for building GenAI applications that use LLMs. This integration facilitates the storage, indexing, and querying of vector embeddings directly within the AlloyDB environment.
The pgvector PostgreSQL extension lets you use vector-specific operators and functions when you store, index, and query text embeddings in your database. The optimizations made in AlloyDB in conjunction with pgvector allow you to significantly speed up embedding operations such as index creation and semantic search.
AlloyDB AI also introduces the alloydb_scann, a highly efficient nearest-neighbor index powered by the ScaNN algorithm that has shown state-of-the-art performance on approximate nearest neighbor (ANN) benchmarks. The ScaNN index can provide up to 4x faster vector queries–up to 8x faster write throughput—and uses 3-4x less memory compared to Hierarchical Navigable Small World (HNSW) indexes. AlloyDB also includes a scalar quantization feature for Inverted File (IVF) indexes. Scalar quantization is easier to enable and requires no tuning. It can significantly speed up queries that have larger dimensional vectors and lets you store vectors with up to 8,000 dimensions.
AlloyDB Embedding Model API
Before you can begin indexing and searching through your data, you need to generate embeddings that can be used by nearest-neighbor algorithms. AlloyDB's model endpoint management makes this simpler by allowing you to register and call any model regardless of where it is hosted.
Vector-Embedding Generation
AlloyDB gives you the flexibility to use existing models or your own custom models deployed on VertexAI to generate embeddings for your data.
To use AlloyDB for vector generation, start by setting up an AlloyDB instance and installing all the necessary extensions to handle vector operations. Next, create a table with a vector column to store the generated embeddings.
The following example shows how to generate and store embeddings alongside the original data.
UPDATE <TABLE_NAME> SET <EMBEDDING_COLUMN_NAME> = embedding('MODEL_ID', SOURCE_TEXT_COLUMN_NAME);
This code snippet can be used to generate embeddings with any model from the Model Garden on Vertex AI. Custom models, whether they are hosted on Vertex AI or your own VM, can be called the same way but must first be registered with AlloyDB model endpoint management. The following example shows how to register a custom model hosted on Vertex AI or anywhere else on Google Cloud.
CALL google_ml.create_model(
model_id => '<model_name>',
model_request_url => '<vertex_ai_request_to_model>',
model_type => 'model_type',
model_in_transform_fn => <custom_embedding_input_transform_function>',
model_provider => 'google',
model_auth_type =>'alloydb_service_agent_iam',
model_out_transform_fn => '<custom_embedding_output_transform_fucntion>');
After you register your model and generate embeddings, use AlloyDB optimized vector extensions to index and query your data.
Embedding Models on Intel Xeon Processors
AlloyDB can store and query your embeddings with high performance and scalability, however, generating embeddings without creating a bottleneck in your pipeline requires a performant model. This involves not only choosing the right model but also the right hardware. Discrete accelerators aren't necessary for all applications and for those running on-premise, they may not even be available.
With the 4th and 5th generations of Intel Xeon Scalable processors, you can run embedding generation and search without the need for GPUs. The 4th and 5th generation Intel Xeon platforms introduce Intel AMX, a dedicated hardware accelerator that helps optimize deep learning workloads by accelerating underlying matrix operations. The Intel AMX architecture supports bfloat16 and int8 data types and can accelerate mixed precision and quantized models out of the box. Intel AMX includes two main components:
- Tiles: Eight two-dimensional registers, each 1 KB in size, that store large chunks of data.
- Tile Matrix Multiplication (TMUL): An accelerator engine attached to the tiles that performs matrix-multiply computations for AI.
To fully use Intel AMX and reduce development time, Intel has worked closely with popular open source frameworks, such as TensorFlow* and PyTorch*, to provide further optimizations on Intel hardware with minimal code changes. For example, using Intel AMX with PyTorch can be as simple as loading the model, casting it to the bfloat16 data type, and running inference:
# Load model
model = ...
#Cast to BF16
with torch.cpu.amp.autocast(dtype=torch.bfloat16):
output = model(input)
GenAI solutions, such as RAG, rely on additional context for tailored responses. This requires accurate, yet performant embedding models. The Massive Text Embedding Benchmarking on Hugging Face* hosts a leaderboard for text-embedding models tested across a wide range of natural language processing (NLP) tasks. While many LLMs perform well on these tasks, their size can lead to performance bottlenecks. For many use cases, a model of this size isn't necessary. There are a number of models with a fraction of the size that reach competitive accuracies and low latencies without the need for GPUs. These models can be further optimized with Intel AMX so they can run on your 4th generation and higher Intel Xeon CPUs while meeting your application's accuracy and latency requirements.
Custom Container from Intel
To make things even simpler for developers, we've released an Intel-Optimized Model for Embedding. It is a 23M parameter, BERT-based model distilled from UAE-Large-v1, a 335M parameter model that is one of the best performing models under 1B parameters on the Massive Text Embedding Benchmark (MTEB) leaderboard. The model architecture was chosen after thorough benchmarking of several BERT-based models. The current architecture delivers a balance between performance and accuracy with 83% FP32 semantic similarity accuracy on MTEB datasets and less than 1% accuracy loss for bfloat16 and int8.
As shown in the following figures, instances of 5th generation Intel Xeon processors achieve up to 5.9x throughput for bfloat16 and up to 3x for int8 compared to instances of 3rd generation Intel Xeon processors.
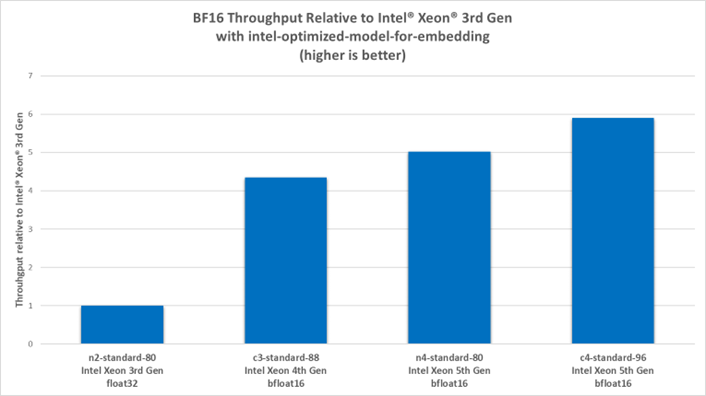
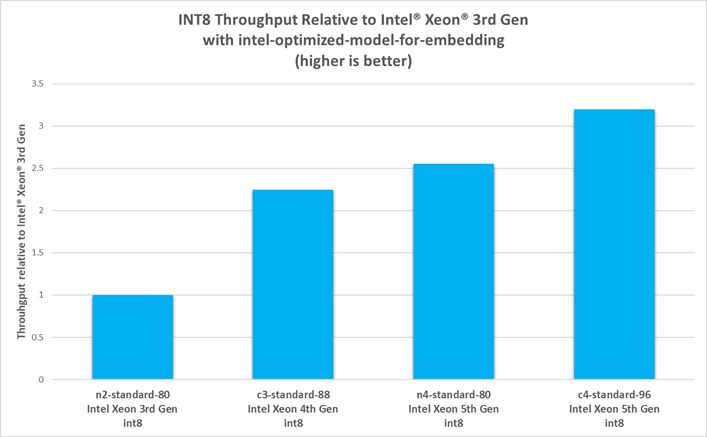
While this data is collected under a throughput-optimized scenario, instances of 4th and 5th generation Intel Xeon processors can still see latencies as low as 70 ms for bfloat16 and 50 ms for int8—a 5x and 2.5x improvement, respectively, compared to instances of 3rd generation Intel Xeon processors. Further tuning can be done for latency-critical applications by modifying the model’s configuration options. For performance tuning advice, see TorchServe with Intel® Extension for PyTorch*.
The FP32/bfloat16 and int8 models are available on Hugging Face, as well as part of a TorchServe container optimized for Intel Xeon processors and Intel AMX. Developers can deploy the container on-premise or to a managed service like Vertex AI and get optimized inference performance out of the box. The container source code is also available on GitHub*.
Conclusion
Building GenAI solutions doesn't need to be difficult. Google AlloyDB and 4th and 5th generation Intel Xeon processors make it easier by offering the following:
- Better performance compared to standard PostgreSQL
- Optimized ScaNN extension in AlloyDB for storing and querying vector-embedding data
- AlloyDB Model endpoint management and integrations with other AI tools and services such as Vertex AI and LangChain
- On-premise support with AlloyDB Omni
-
Intel AMX for faster AI inference without GPUs
Intel is also leading the way for open source, end-to-end AI software as a contributor to the Open Platform for Enterprise AI (OPEA). Go to OPEA for end-to-end RAG components to pair with AlloyDB.