Large Language Models (LLMs) have become significantly popular in the last few years as they provide human-like interaction for many Generative AI (GenAI) applications like question-answering, code development and content creation. Out of all these, Question and Answering (Q&A) applications have found a significant acceptance among the users. Applications like ChatGPT, which have different capabilities, have made LLMs mainstream and accessible to a wider audience. A few of the capabilities are- ChatGPT can act as a virtual assistant, customer support and expert advisor.
This article showcases a code sample on how to compile LlamaCpp-python for the SYCL backend and develop an AI travel agent for answering travel and tourism related queries on Intel® Core™ Ultra Processors (AI PCs). AI PCs are the new generation of personal computers, which includes a CPU, GPU, and a neural processing unit (NPU).
Why LLM Agents?
LLMs are neural networks that are trained to generate text based on the provided context and are great at processing information. They can use external tools for a specific functionality based on the usage instructions given in the prompt. LLMs when combined with external tools are called LLM Agents or simply Agents.
These LLM Agents are extremely important for building Q&A systems which require access to real-time and/or external data and tools to answer user queries. Here, we will illustrate how to create an AI Travel Agent, that will be able to answer queries related to tourism, top attractions, places to visit, itinerary planning, nearest airport, flight availability and cheapest flights.
Components of an LLM Agent
An LLM Agent will have the following components:
- LLM: The brain of the agent is the LLM model, that is trained on vast amounts of data. It is responsible for processing the user query and generating appropriate responses (example: Meta Llama 3.1 model).
- Prompt: Prompt is a set of instructions or rules to be followed by the LLM for understanding the context and generating better responses to the user.
- Tools: Tools are the interfaces that LLM can use to interact with the real world (example: Wikipedia tool).
LangChain’s Structured Chat Agent
LangChain is a framework for building LLM applications. It has a collaboration with a wide range of tools and toolkits that makes the development of LLM applications much easier and simpler.
For the AI travel agent, we use structured chat agent from LangChain to create the agent which supports multi-input tools. A structured chat agent accepts messages from the users as input and generates structured responses. Here, the efficiency of the response/answers depend on the quality of the model used.
Get Started with the AI Travel Agent
The code sample shows how to create and execute an AI Travel Agent on the integrated GPU (iGPU) of the AI PC. For this, we should first compile Llamacpp-python for SYCL backend. This is required to run inference on the iGPU. By default, it runs on the CPU. Next, we create an agentic workflow for the AI travel agent.
I. Setting up environment
- Install Intel® oneAPI Base Toolkit - This Base toolkit is prerequisite to compile the LlamaCpp-Python and follow the instructions on this page to install the toolkit.
- Clone the AI travel agent code repo using the command below.
git clone https://github.com/intel/AI-PC_Notebooks.git
- Activate oneAPI environment as shown below.
@call "C:\Program Files (x86)\Intel\oneAPI\setvars.bat" intel64 –force
- Create a conda environment
conda create -n gpu_llmsycl python=3.11
conda activate gpu_llmsycl - Set the environment variables
set CMAKE_GENERATOR=Ninja
set CMAKE_C_COMPILER=cl
set CMAKE_CXX_COMPILER=icx
set CXX=icx
set CC=cl
set CMAKE_ARGS="-DGGML_SYCL=ON -DGGML_SYCL_F16=ON -DCMAKE_CXX_COMPILER=icx -DCMAKE_C_COMPILER=cl" - Compile the Llamacpp-Python for SYCL backend
pip install llama-cpp-python -U --force --no-cache-dir –verbose
- Install the pip packages required for the AI Travel Agent
pip install -r requirements.txt
II. Create an agentic workflow
1. Local LLM Configurations
The local LLM used for illustration here is Meta Llama 3.1 8B Q4 K_S and download the model with below commands:
from huggingface_hub import hf_hub_download
hf_hub_download(
repo_id="bartowski/Meta-Llama-3.1-8B-Instruct-GGUF",
filename="Meta-Llama-3.1-8B-Instruct-Q4_K_S.gguf",
local_dir="./models"
)
When loading the model on iGPU, initialize the model with the following parameters.
llm = LlamaCpp(
model_path=model_path, # Model file path.
n_gpu_layers=-1, # Use all available GPU layers.
seed=512, # Random seed for reproducibility.
n_ctx=4096, # Context window size (tokens the model can handle).
f16_kv=True, # Use 16-bit floating point for key-value pairs.
verbose=True, # Enable verbose output.
temperature=0, # Deterministic output (no randomness).
top_p=0.95, # Top-p sampling for controlling diversity.
n_batch=512, # Batch size for inference.
)
2. Tools
The agent is given access to the following three tools from LangChain v0.3:
- LangChain Google Serper API - The following snapshot depicts the tool definition.
from langchain_community.utilities import GoogleSerperAPIWrapper from langchain_core.tools import Tool search = GoogleSerperAPIWrapper() # Initialize the search wrapper to perform Google searches google_search_tool = Tool( name="Google Search tool", func=search.run, description="useful for when you need to ask with search", ) - LangChain Amadeus toolkit - for flight information such as closest_airport near a queried location and flight_search that gives flight availability between two places. The following snapshot depicts the toolkit definition.
from amadeus import Client from langchain_community.agent_toolkits.amadeus.toolkit import AmadeusToolkit amadeus_client_secret = os.getenv("AMADEUS_CLIENT_SECRET") amadeus_client_id = os.getenv("AMADEUS_CLIENT_ID") amadeus = Client(client_id=amadeus_client_id, client_secret=amadeus_client_secret) amadeus_toolkit = AmadeusToolkit(client=amadeus, llm=llm) amadeus_tools = amadeus_toolkit.get_tools() - LangChain SerpAPI tool - a real-time API to access Google search results.
from langchain.agents import load_tools serp_tools = load_tools(["serpapi"])Next, we need to combine all the tools.
tools = [google_search_tool] + amadeus_tools + serp_tools
3. Prompt Template
Prompt plays an important role in making an LLM understand what the user is expecting as the response. The following snapshot shows how the prompt template is customized for the AI Travel Agent and its usage of tools.
PREFIX = """[INST]Respond to the human as helpfully and accurately as possible. You have access to the following tools:"""
FORMAT_INSTRUCTIONS = """Use a json blob to specify a tool by providing an action key (tool name) and an action_input key (tool input).
Use the closest_airport tool and single_flight_search tool for any flight related queries. Give all the flight details including Flight Number, Carrier, Departure time, Arrival time and Terminal details to the human.
Use the Google Search tool and knowledge base for any itinerary-related queries. Give the day-wise itinerary to the human. Give all the detailed information on tourist attractions, must-visit places, and hotels with ratings to the human.
Use the Google Search tool for distance calculations. Give all the web results to the human.
Provide the complete Final Answer. Do not truncate the response.
Always consider the traveller’s preferences, budget constraints, and any specific requirements mentioned in their query.
Valid "action" values: "Final Answer" or {tool_names}
Provide only ONE action per $JSON_BLOB, as shown:
```
{{{{
"action": $TOOL_NAME,
"action_input": $INPUT
}}}}
```
Follow this format:
Question: input question to answer
Thought: consider previous and subsequent steps
Action:
```
$JSON_BLOB
```
Observation: action result
... (repeat Thought/Action/Observation N times)
Thought: I know what to respond
Action:
```
{{{{
"action": "Final Answer",
"action_input": "Provide the detailed Final Answer to the human"
}}}}
```[/INST]"""
SUFFIX = """Begin! Reminder to ALWAYS respond with a valid json blob of a single action. Use tools if necessary. Respond directly if appropriate. Format is Action:```$JSON_BLOB```then Observation:.
Thought:[INST]"""
HUMAN_MESSAGE_TEMPLATE = "{input}\n\n{agent_scratchpad}"
Every LangChain agent has a set of instructions specific to its type. For the structured chat agent, to customize as a travel agent, we add some instructions to the original prompt template for better results. Additionally, we mention how to use the prompt template by providing prefix, suffix to the input, template for human messages and instructions for formatting responses.
Agent & Agent Executor
We can combine LLM, Tools and prompt together to create an agent as follows.
from langchain.agents import StructuredChatAgent
agent = StructuredChatAgent.from_llm_and_tools(
llm, # LLM to use
tools, # Tools available for the agent
prefix=PREFIX, # Prefix to prepend to the input
suffix=SUFFIX, # Suffix to append to the input
human_message_template=HUMAN_MESSAGE_TEMPLATE, # Template for human messages
format_instructions=FORMAT_INSTRUCTIONS, # Instructions for formatting responses
)
Next, we will create an agent executor. An agent executor is important for managing interactions with the LLM model and available tools because it provides the runtime environment for an agent, facilitating the execution of actions and returning outputs for continuous processing.
from langchain.agents import AgentExecutor
agent_executor = AgentExecutor(
agent=agent, # The structured chat agent
tools=tools, # Tools to be used by the agent
verbose=True, # Enable verbose output for debugging
handle_parsing_errors=True, # Allow error handling for parsing issues
max_iterations=1, # Limit the number of iterations. Can change based on requirement
early_stopping_method='generate' # Method to use for agent early stopping
)
Here, to allow error handling for parsing issues, we define the variable handle_parsing_errors as True. To prevent the agent from talking to itself or getting into infinite loop of iterations, limit the iterations by setting the max_iterations to 1 and to prevent the agent from stopping because of max iteration limit, set the early_stopping_method to ‘generate’.
The command to run the agent by invoking the agent executor is -
agent_executor.invoke({"input": "What are the top places to visit in Dubai"})
Analyze the Agentic Execution
The following figure depicts the process flow for the AI Travel Agent for a user query.
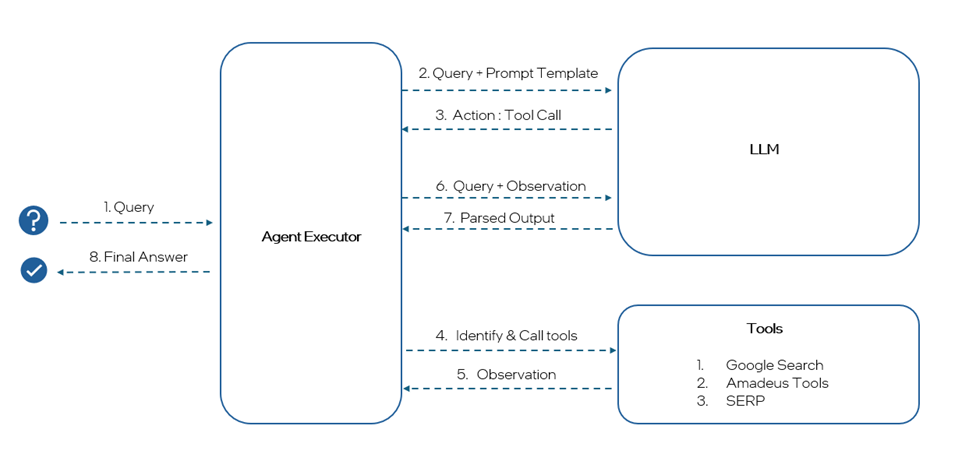
From Figure 1, we can observe that when a user asks a query, the query and prompt template are fed to the LLM by the agent executor. Internally within the agent, the user query prompt and the prompt template are vital in analyzing actions that are required to be taken. After processing the initial thought, the agent decides to choose a relevant tool as per the prompt instructions and this is called Agentic Action.

A relevant tool is identified and called by the agent executor from the available set of tools based on the user query. Here, as it is a search query, google search is the tool selected to provide the information from the API. The tool then gives the response as an observation to the agent. The following image shows the observation for the above user query.

The agent executor sends the original user query and the observed tool response to the LLM to fetch the relevant information for the final answer. The LLM then rephrases and formats the final answer from the observations as per the formatting instructions mentioned in the prompt template and parses the output in the mentioned format as shown below (in the json format). The final answer is then shared to the user.

Summary
In this article, we have seen how to compile Llama-Cpp python bindings with SYCL support to load the model on the iGPU for inference. We also developed an agentic workflow that makes use of LLM, prompt and tools. Then, this agent is tested on the iGPU of AI PC Intel® Core™ Ultra Processors having 16GB RAM. The LLM models used here are Meta Llama 3.1 8B Q4 K_S and Qwen 2.5-7B-Instruct-Q4_K_S. Meta Llama 3.1 has given better accuracy and faster responses when compared to Qwen 2.5.
The code sample shows that we can load a quite powerful 7/8B model, develop and run LLM based applications like Q&A systems with agents on AI PC, all while leveraging the iGPU on AI PC. This goes on to show the new AI PCs systems are capable for GenAI workloads.
What’s Next
Explore the GenAI playground GitHub repository that contains different example notebooks which shows how to develop end-to-end GenAI applications on AI PCs.
We encourage you to also check out and incorporate Intel’s other AI/ML Framework optimizations and tools into your AI workflow and learn about the unified, open, standards-based oneAPI programming model that forms the foundation of Intel’s AI Software Portfolio to help you prepare, build, deploy, and scale your AI solutions.