Introduction
In this article, we describe how we achieved 35% faster performance in GTC-P APEX code using Intel® Advisor on an Intel® Xeon Phi™ processor code named Knights Landing (KNL). Using Intel® Advisor, we identified the five top most time consuming loops, four of which were scalar. The goal of our work was to try to vectorize these loops and get the best possible vectorization efficiency out of it that would increase the overall performance of the application. The main and the most time consuming loop was taking 86% of the whole execution time. By vectorizing this loop, we improved the overall application performance by 30%. The rest 5% of performance gain is achieved by vectorizing the other four loops that Intel® Advisor identified.
This article is divided into several sections. Firstly, we will describe Intel® Advisor in more details. Compilation and execution of the GTC-P APEX code will be discussed afterwards. Next, we will briefly describe KNL memory architecture. Analysis of the GTC-P APEX code will be covered next. Finally, we will conclude our article with our findings.
Intel® Advisor
Intel® Advisor is one of the analysis tools provided in the Intel® Parallel Studio XE suite. It has two main functionalities which are threading design and vectorization advisor. Threading design is used when a developer is unsure where to introduce parallelism in his/her single threaded application. In this case, Intel® Advisor can analyze the application, detect regions of code where parallelism would be beneficial and estimate the potential performance speedup the application would gain if parallelism is introduced in these specified code regions. Furthermore, if the developer decides to make the specified code regions parallel, Intel® Advisor can analyze the code to detect data sharing issues that would happen. Thus, the biggest advantage of threading design is that during the design stage Intel® Advisor can help by suggesting where to introduce parallelism, estimate potential speedup from it, and detect potential data sharing issues even before the developer decides to implement these changes.
The second functionality, and the one we will use in this article, is vectorization advisor. There are several analyses that vectorization advisor provides:
- Survey collection - provides detailed information about your application from vectorization stand point. It analyzes your code, reports all the loops it detected, whether they were vectorized or not, reasons for compiler not vectorizing scalar loops, vectorization efficiency for each vectorized loop, recommendations on how to improve the vectorization efficiency if it is low and suggestions on how to enable vectorization for scalar loops.
- Tripcount collection - collects information about the tripcounts and number of call times for each loop. The tripcount information is useful when you don't know whether vectorization would benefit a loop or when you try to understand why vectorization efficiency is low.
- Dependencies analysis - helps identify whether a loop has any data dependency issues that would prevent it from being vectorized.
- Memory Access Pattern (MAP) analysis - identifies the distribution of different memory access patterns existing in a loop body. There are three different memory access patterns in Advisor, which are unit strided, constant strided and variable strided accesses. Vectorization works best with unit strided accesses, and you get lower vectorization efficiency with a loop that has constant or variable strided accesses. Thus, MAP analysis can help you understand how much efficiency can you expect from vectorization depending on the distribution of the accesses the analysis reports.
Compilation and running the GTC-P APEX code
To compile the code on a KNL machine, you need to make a copy of Makefile.generic file located in ARCH subfolder of the main directory, and modify it to include the following options:
- -xMIC-AVX512 - flag that tells the compiler to create a binary suitable for KNL and to apply auto vectorization on the loops.
- -qopt-report=5 - flag that dumps compiler optimization and vectorization report for each source file to a corresponding file.
- -g - to get the symbol names corresponding to variable names, functions, classes etc in the code.
The following options were used in our Makefile file to compile the GTC-P APEX code for this work:
CC= mpiicc
CFLAGS = -std=gnu99 -Wall -Wextra -D_GNU_SOURCE -g -xMIC-AVX512 -qopt-report=5
CGTCOPTS += -DCACHELINE_BYTES=64
CFLAGSOMP = -qopenmp
COPTFLAGS = -O3
CDEPFLAGS = -MD
CLDFLAGS = -limf
EXEEXT = _knl_icc
The GTC-P APEX code is a hybrid MPI and OpenMP code. All tests were run on one KNL node with 1 MPI rank and 128 OMP threads. The executable can be run using the following command on KNL machine:
mpiexec.hydra -n 1 numactl -m 1 ./bench_gtc_knl_icc B-1rank.txt 400 1
KNL Memory Architecture
A KNL machine has two memory subsystems. In addition to DDR4 memory, there is also a high bandwidth on package memory called MCDRAM. MCDRAM can be configured in 3 modes on boot time, which are Cache mode, Flat mode and Hybrid mode. In Cache mode, 16GB of MCDRAM is configured as Last Level Cache (LLC), whereas in Flat mode it is configured as a separate Non-Uniform Memory Access (NUMA) node. The Hybrid mode is the configuration of partial Cache and partial Flat modes. You can find out the MCDRAM configuration on a KNL system using numastat -m command as seen below:
Per-node system memory usage (in MBs):
| Node 0 | Node 1 | Total | |
| MemTotal | 98200.81 | 16384.00 | 114584.81 |
| MemFree | 88096.82 | 11403.77 | 99500.60 |
| MemUsed | 10103.99 | 4980.23 | 15084.21 |
| Active | 2494.45 | 4417.58 | 6912.03 |
| Inactive | 3128.38 | 10.65 | 3139.02 |
| Active(anon) | 2435.44 | 4412.72 | 6848.16 |
| Inactive(anon) | 93.94 | 0.66 | 94.59 |
| Active(file) | 59.01 | 4.86 | 63.87 |
| Inactive(file) | 3034.44 | 9.99 | 3044.43 |
| Unevictable | 0.00 | 0.00 | 0.00 |
| Mlocked | 0.00 | 0.00 | 0.00 |
| Dirty | 0.00 | 0.00 | 0.00 |
| Writeback | 0.00 | 0.00 | 0.00 |
| FilePages | 3093.59 | 14.86 | 3108.45 |
| Mapped | 4.75 | 0.04 | 4.79 |
| AnonPages | 23.64 | 0.02 | 23.66 |
| Shmem | 0.12 | 0.00 | 0.12 |
| KernelStack | 59.89 | 0.06 | 59.95 |
| PageTables | 1.52 | 0.00 | 1.52 |
| NFS_Unstable | 0.00 | 0.00 | 0.00 |
| Bounce | 0.00 | 0.00 | 0.00 |
| WritebackTmp | 0.00 | 0.00 | 0.00 |
| Slab | 731.95 | 97.56 | 829.51 |
| SReclaimable | 155.30 | 14.47 | 169.77 |
| SUnreclaim | 576.65 | 83.09 | 659.75 |
| AnonHugePages | 0.00 | 0.00 | 0.00 |
| HugePages_Total | 0.00 | 0.00 | 0.00 |
| HugePages_Free | 0.00 | 0.00 | 0.00 |
| HugePages_Surp | 0.00 | 0.00 | 0.00 |
The above configuration shows that our KNL machine was configured in Flat mode, with Node 0 representing 98GB of DDR4, and Node 1 corresponding to 16GB of MCDRAM memory. Based on application’s data access pattern, you can decide which memory mode would be more beneficial to run the application in. With Flat mode, you can also choose which data objects to be allocated on MCDRAM and DDR4 respectively. The advantage of allocating the data on MCDRAM is that it provides ~4x more memory bandwidth than the DDR4. This means that if an application is memory bandwidth bound, then MCDRAM could drastically improve the performance of the application compared to DDR4 allocation.
In this work, we specify that we want to allocate all the data on MCDRAM using numactl –m 1 option in the command line. This option will work fine if all the data created in the application fits into MCDRAM size. However if the data won’t fit into MCDRAM with numactl –m 1 option, then the application will crash. To avoid this kind of situations, you can use numactl –p 1 option instead, which ensures that the leftover data that didn’t fit into MCDRAM will be allocated in DDR4. Moreover, you can also selectively choose specific data objects that you want to put in MCDRAM and the rest of the data in DDR4. This can be accomplished using libmemkind library calls that can be instrumented in the code instead of the traditional memory allocation routines.
Analysis of the GTC-P APEX code using Intel® Advisor
#!/bin/bash
export KMP_AFFINITY=compact,granularity=fine
export KMP_PLACE_THREADS=64c,2t
mpiexec.hydra -n 1 numactl -m 1 advixe-cl -collect survey -project-dir knl-orig -interval=20 -no-stack-stitching -no-auto-finalize -search-dir all=../src/ -data-limit=102400 -- ../src/bench_gtc_knl_icc B-1rank.txt 400 1
We used the above script to run survey analysis in Intel® Advisor. Please notice the usage of “-no-auto-finalize” option in the command line. Intel® Advisor runs in two steps which are collection and finalization of data. Collection step profiles application and collects raw data from it. Finalization step converts the raw data to a database data that is then read via Intel® Advisor GUI. This step can take quite a lot of time if the raw data is huge. In addition to that, finalizing result on very low CPU frequency, such as the ones that KNL cores have (1.3 GHz), will even further slowdown this step. Thus, it is advisable to use “no-auto-finalize” option when collecting the profiled data on KNL system, then to run the finalization step separately on any other Xeon based system with higher CPU frequency rate. The finalization step will automatically take place once you open your project directory using Intel® Advisor GUI. In addition, you may want to decrease the number of threads running in order to decrease the overhead Advisor incurs in performing deep-dive analyses.
 Figure 1 Survey Report
Figure 1 Survey Report
The Survey report is the first collection that needs to be run in Intel® Advisor. This collection generates a detailed report, shown in Figure 1, about every loop in the code and whether it was vectorized or not. If a loop is vectorized by the compiler, the survey report will show the vectorization efficiency level shown in Efficiency column. This metric will give you an idea how well your loop was vectorized, whether you achieved the maximum performance out of vectorizing the loop or not. If the efficiency metric is low, Vector Issues column will give an idea why vectorization didn't gain 100% efficiency. If a loop is not vectorized by the compiler, Why No Vectorization column will give a reason why the compiler couldn't vectorize it. The Type column will show what type of loop it is i.e. scalar, threaded, vectorized, or both threded and vectorized. There are two time metrics shown in the report, which are Self Time and Total Time. Self time shows the time it takes to execute a loop body excluding function calls. If there is a function call inside the loop body, the time to execute the function will be included in the Total time metric. Thus, Total time metric will comprise the time from Self time and the time it takes to execute function calls inside the loop.
Figure 1 shows the top 10 most time consuming loops in the code, where orange and blue colors represent vectorized and non-vectorized loops respectively. In this article, we will focus on the first top 5 loops and try to vectorize non-vectorized loops and improve vectorization efficiency for vectorized loops.
Code Change #1
The very first loop in the list is not vectorized and it takes 86.5% of all the execution time. The reason why this loop was not vectorized is because the inner loop inside it was already vectorized by the compiler, as shown in Figure 1 in Why No Vectorization column. The default compiler policy for vectorization is to vectorize inner most loops first whenever possible. Sometimes, though, outer loop vectorization might be more beneficial in terms of application performance in cases when outer loop trip count is larger than the inner loop's tripcount and memory access pattern inside the loop body is appropriate for outer loop vectorization. Our outer loop starts at line #306 in push.c file. The compiler optimization report shows that the compiler skipped vectorizing this loop at line #306 because the inner loop at line #355 was vectorized instead, as seen in Figure 2.
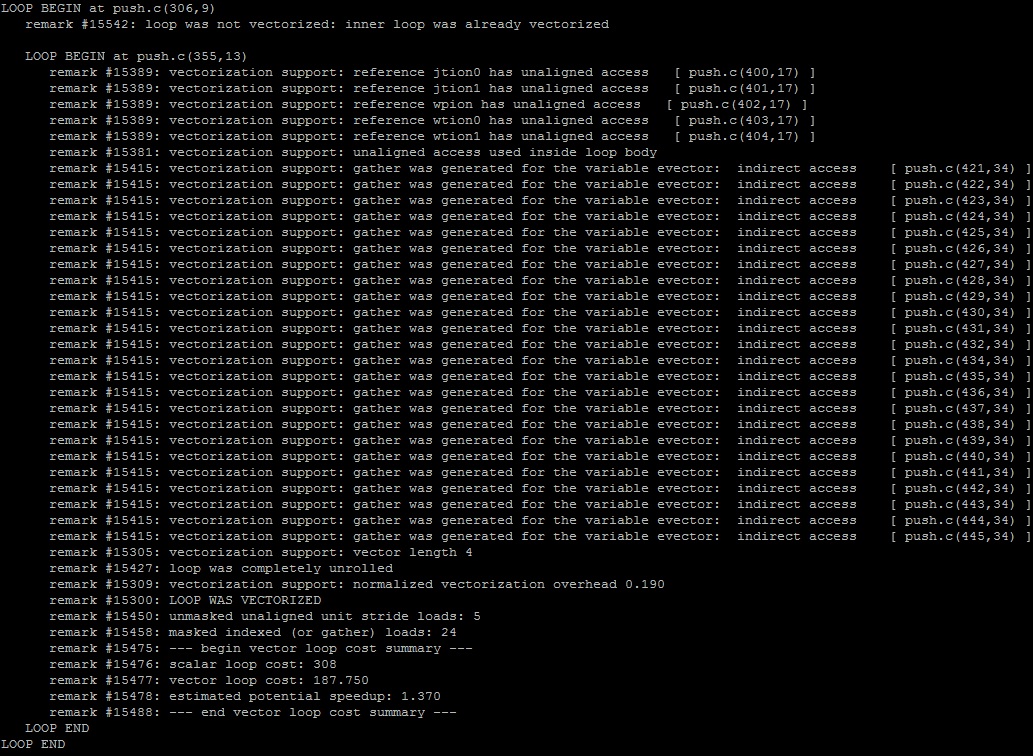 Figure 2 Compiler optimization report for push.c file
Figure 2 Compiler optimization report for push.c file
Figure 3 and 4 show the source code for loops at line #306 and line #355, respectively.
 Figure 3 Source code for loop at line #306 in push.c file
Figure 3 Source code for loop at line #306 in push.c file
From the source code, we clearly see that the loop at line #355 is only 4 iterations in total and still it is being vectorized. Whereas, the loop at line #306 has much larger tripcount, which is determined by mi variable and in our test case it ranges in millions, was left not vectorized. The first change that we will make in the code is to prevent the compiler from vectorizing the inner loop using pragma novector directive, and to remove the assert statement in the outer loop body that prevents it from vectorization. This change will be marked as change1.
Table 1 shows the comparison of the execution time report of the original code against the modified change1 code with “pragma novector” directive. The modified change1 version is almost 5% faster than the original code, which means vectorizing inner loop actually decreased the performance. Figure 5 shows that the outer loop at line #306 is still not vectorized but the total time for the loop has decreased from 6706 to 5212 seconds.
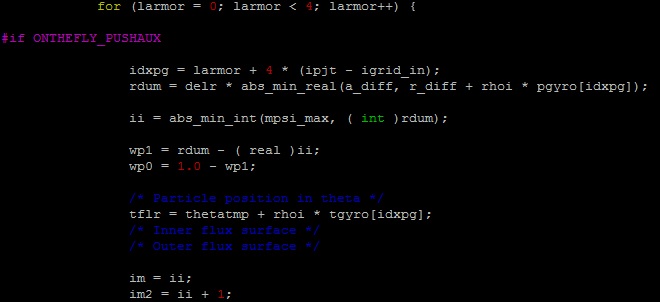 Figure 4 Source code for loop at line #355 in push.c file
Figure 4 Source code for loop at line #355 in push.c file
Code Change #2
Why No Vectorization field in Figure 5 also suggests to consider using SIMD directive, which is the directive that forces the compiler to vectorize a loop. So the next change in the code, marked as change2, will be to use pragma simd directive explicitly on this loop.
 Figure 5 Survey report for change1 code
Figure 5 Survey report for change1 code
| Original Code | Change1 code |
|
Total time: 128.848269 s Charge 51.835024 s (40.2295) Push 69.949501 s (54.2883) Shift_t 0.000677 s (0.0005) Shift_r 0.000201 s (0.0002) Sorting 5.833193 s (4.5272) Poisson 0.279117 s (0.2166) Field 0.365359 s (0.2836) Smooth 0.566864 s (0.4399) Setup 19.028135 s Poisson Init 0.032476 s |
Total time: 122.644956 s Charge 54.230016 s (44.2171) Push 60.748115 s (49.5317) Shift_t 0.000926 s (0.0008) Shift_r 0.000268 s (0.0002) Sorting 6.163052 s (5.0251) Poisson 0.370527 s (0.3021) Field 0.405065 s (0.3303) Smooth 0.696573 s (0.5680) Setup 21.083826 s Poisson Init 0.033654 s |
Table 2 shows the performance comparison between the original code, the modified code with change1, and the modified code with change2.
| Original Code | Code with change1 | Code with change2 |
|
Total time: 128.848269 s Charge 51.835024 s (40.2295) Push 69.949501 s (54.2883) Shift_t 0.000677 s (0.0005) Shift_r 0.000201 s (0.0002) Sorting 5.833193 s (4.5272) Poisson 0.279117 s (0.2166) Field 0.365359 s (0.2836) Smooth 0.566864 s (0.4399) Setup 19.028135 s Poisson Init 0.032476 s |
Total time: 122.644956 s Charge 54.230016 s (44.2171) Push 60.748115 s (49.5317) Shift_t 0.000926 s (0.0008) Shift_r 0.000268 s (0.0002) Sorting 6.163052 s (5.0251) Poisson 0.370527 s (0.3021) Field 0.405065 s (0.3303) Smooth 0.696573 s (0.5680) Setup 21.083826 s Poisson Init 0.033654 s |
Total time: 88.771399 s Charge 52.456334 s (59.0915) Push 29.125329 s (32.8094) Shift_t 0.000685 s (0.0008) Shift_r 0.000254 s (0.0003) Sorting 5.908818 s (6.6562) Poisson 0.288442 s (0.3249) Field 0.401597 s (0.4524) Smooth 0.571354 s (0.6436) Setup 19.136696 s Poisson Init 0.031585 s |
The code modification, marked as change2, that explicitly vectorized the outer loop at line #306 in push.c using pragma simd directive gained us 30% of performance improvement, as seen in Table 2. The main time difference between the original and the change2 code is in "Push" phase, which has decreased from 69.9 seconds to 29.1 seconds and correctly represents our change in code.
 Figure 6 Top time consuming loops for original version on the top and for change2 version on the bottom
Figure 6 Top time consuming loops for original version on the top and for change2 version on the bottom
Figure 6 shows the list of top time consuming loops in original code shown on the top versus the change2 code shown on the bottom of the Figure. The most time consuming loop in original code is found to be the loop at line #306 in push.c which we vectorized in our change2 version. Thus, we clearly see that on the bottom list, the loop has disappeared which means it hasn't become one of the top time consuming loops anymore. Instead, all other loops on the list have moved one rank upper and we see that a new loop was added to the bottom list.
Code Change #3
Next, we will focus on the next two top time consuming loops in the list. Based on the survey analysis report in Figure 1, the compiler was not able to vectorize either of the loops at line #145 and #128 in shifti.c file due to existence of assumed data dependency issue. In order to confirm if there is any data dependency issue in these two loops, we ran Dependencies analysis by marking these loops for a deeper analysis.
mpiexec.hydra -n 1 -gtool "numactl -m 0 advixe-cl -collect dependencies -mark-up-list=48 -project-dir knl-orig --search-dir sym:p=src --search-dir bin:p=src --search-dir src:p=src :0" ../src/bench_gtc_knl_icc B-1rank.txt 400 1
The above command line shows how we ran Dependencies analysis. mark-up-list option tells Advisor the loop of interest, where loop id is set by Advisor during survey analysis. In order to correctly know the loop id, you can do either of these two options:
- Open the survey result directory using Advisor GUI. In Survey Report tab, select the loop of interest by checking the box under water drop column. Then, under Check Dependencies section in Vectorization workflow, click the button to get command line generated by Advisor. In the command line, you will be able to see the loop number provided for mark-up-list option. Please see Figure 7 as an example.
- You can generate report from command line interface, which will print out the loop id's for each loop as follows:
advixe-cl --report survey --project-dir ./knl-orig --search-dir src:r=./src
 Figure 7 Identifying loop id using Advisor GUI
Figure 7 Identifying loop id using Advisor GUI
The dependencies analysis showed that indeed a proven data dependency issue exists in loop at line # 128 in shifti.c, but not in loop line #145, see Figure 8. Thus, we vectorized only loop #145 in shifti.c using pragma ivdep directive which tells the compiler to ignore any vector dependency issue in the loop followed by the directive. However, vectorizing this loop did not gain us much performance improvement as seen in Table 3.
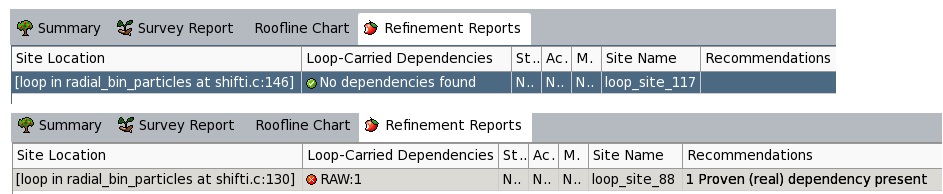 Figure 8 Report from dependencies analysis for loops at line #145 and #128 in shifti.c (The lines have shifted a bit, thus shows #146 and #130)
Figure 8 Report from dependencies analysis for loops at line #145 and #128 in shifti.c (The lines have shifted a bit, thus shows #146 and #130)
| Change2 version | Vectorized loop at line #145 in shifti.c |
|
Total time: 88.771399 s Charge 52.456334 s (59.0915) Push 29.125329 s (32.8094) Shift_t 0.000685 s (0.0008) Shift_r 0.000254 s (0.0003) Sorting 5.908818 s (6.6562) Poisson 0.288442 s (0.3249) Field 0.401597 s (0.4524) Smooth 0.571354 s (0.6436) Setup 19.136696 s Poisson Init 0.031585 s |
Total time: 87.671250 s Charge 52.588174 s (59.9834) Push 29.135723 s (33.2329) Shift_t 0.000711 s (0.0008) Shift_r 0.000298 s (0.0003) Sorting 4.668660 s (5.3252) Poisson 0.285867 s (0.3261) Field 0.402622 s (0.4592) Smooth 0.570873 s (0.6512) Setup 19.121684 s Poisson Init 0.032722 s |
Code Change #4
The next loop in the top time consuming loops list is loop at line #536 in chargei.c file which is the inner loop in the doubly nested loop shown in Figure 9.
 Figure 9 Source code for loop at line #536 in chargei.c file
Figure 9 Source code for loop at line #536 in chargei.c file
The compiler auto-vectorizes the loop at line #536 in chargei.c file, but it achieves only 50% of vectorization efficiency as shown in Figure 1. As a default behavior, the compiler auto-vectorizes the innermost loops first and leaves outer loops non-vectorized when the innermost loop is vectorized. However, in this case vectorizing the outer loop might be more beneficial since the trip count for the outer loop is much larger than the inner loop. Since there is no any data dependency issue in this doubly nested loop, we can force the compiler to vectorize the outer loop using pragma simd clause, and force the compiler to not vectorize the inner loop using pragma novector clause. These changes will be marked as change4 version.
 Figure 10 Survey report for change4 code
Figure 10 Survey report for change4 code
Changes in change4 code caused the execution time for "Charge" phase to decrease from 52.45 to 49.36 seconds which is about 6% performance increase, and cause 4% performance improvement in total execution time as seen in Table 4. Moreover, you can see that the survey report, shown in Figure 10, shows the total time for loop at line #536 in chargei.c file now has decreased to 21.9 seconds from its previous 227.2 seconds.
| Change1 | Change4 |
|
Total time: 88.771399 s Charge 52.456334 s (59.0915) Push 29.125329 s (32.8094) Shift_t 0.000685 s (0.0008) Shift_r 0.000254 s (0.0003) Sorting 5.908818 s (6.6562) Poisson 0.288442 s (0.3249) Field 0.401597 s (0.4524) Smooth 0.571354 s (0.6436) Setup 19.136696 s Poisson Init 0.031585 s |
Total time: 85.078972 s Charge 49.366594 s (58.0244) Push 28.602789 s (33.6191) Shift_t 0.000662 s (0.0008) Shift_r 0.000233 s (0.0003) Sorting 5.852659 s (6.8791) Poisson 0.281661 s (0.3311) Field 0.370580 s (0.4356) Smooth 0.585129 s (0.6877) Setup 19.006850 s Poisson Init 0.031122 s |
Finally, let’s focus on the last loop in the top time consuming loops list, which is loop at line #77 in shifti.c file. The compiler was not able to auto-vectorize this loop due to the existence of assumed data dependency issue. After checking the code, we have found out that there is definitely data dependency between iterations of the loop and thus vectorization of this loop will cause a correctness problem. Thus, we did not vectorize this loop.
In order to see the final performance improvement between the original and the vectorized versions of GTC-P APEX code, we made all the vectorization changes to the code and obtained the following results in Table 5.
| Original version | Modified version |
|
Total time: 128.848269 s Charge 51.835024 s (40.2295) Push 69.949501 s (54.2883) Shift_t 0.000677 s (0.0005) Shift_r 0.000201 s (0.0002) Sorting 5.833193 s (4.5272) Poisson 0.279117 s (0.2166) Field 0.365359 s (0.2836) Smooth 0.566864 s (0.4399) Setup 19.028135 s Poisson Init 0.032476 s |
Total time: 83.726301 s Charge 49.607312 s (59.2494) Push 28.287559 s (33.7858) Shift_t 0.000674 s (0.0008) Shift_r 0.000259 s (0.0003) Sorting 4.585134 s (5.4763) Poisson 0.280857 s (0.3354) Field 0.370222 s (0.4422) Smooth 0.576150 s (0.6881) Setup 19.010042 s Poisson Init 0.030605 s |
Conclusion
In this article we tried to vectorize and/or improve vectorization efficiency of the top 5 most time consuming loops in GTC-P APEX code reported by Intel® Advisor tool. We were able to improve vectorization efficiency of three loops in push.c, chargei.c and shifti.c files which improved the performance of the code by 35% in total against the original version of the code. Moreover, the loops at line #77 and #128 in shifti.c were not vectorized due to the data dependency issue.
To see figures in a better quality, please right click and open them in a new window, which then will show the picture in original size.