Introduction
As data center server technology has become more sophisticated over the last decade or so, there has been an accelerating trend toward loading more networking capability onto servers. Alongside this is a wide proliferation of tooling, both in server and network interface hardware, and in the software stack that utilizes them, to speed the delivery of network data to and from where it most needs to be. Several of these tools are undergoing rapid development right now; many of them in open source projects.
Many people are curious about the advanced technologies in networking, even if they aren’t explicitly working in traditional high-volume fields such as telecommunications. This guide aims to differentiate and explain the usage of some of the most prominent of these (mostly open source) tools, at an overview level, as they stand today. We’ll also attempt to explain the scenarios under which various tools or combinations of tools are desirable.
A Starting Point: Why Server Networking Became So Important
In the beginning (say, the 90s, more or less), things were pretty simple. A single server had a network interface card (NIC), and an operating system (OS) driver for that NIC, upon which a desired software network stack (like TCP/IP, usually, although there are many others) would run. The NIC driver used interrupts to demand attention from the OS kernel when new network packets would arrive or depart.
With the arrival of virtualization as a major shift in server usage, this same model was replicated into virtual machines (VMs), wherein virtual NICs serve as the way to get network packets into and out of the virtualized OS. To facilitate this, hypervisors integrated a software-based bridge.
The bridge had the physical NIC connected on a software port, and all of the virtual NICs attached to the same bridge via their own software ports. A common variant of this (today) is Linux* bridging, which is built directly into the Linux kernel. The hypervisor side of the VM NICs could be represented by a number of underlying types of virtual NIC, most commonly a tap device (or network tap) that emulates a link-layer device.
Simple virtualization setups still use this method without much of a problem. However, there are two main reasons why something more complex is called for: security and performance.
On the security side, as virtualized infrastructure became more prevalent and dense, the need to separate packet flows from neighboring VMs on the same host became more pressing. If a single VM on a host were to be compromised, it is certainly for the best if it remained on its own isolated switch port, rather than sharing a bridge with many other VMs and the physical NIC. This certainly isn’t the only security issue, but it’s the one we’ll address first.
On the performance side, all of the interrupts from the virtual NICs add up quickly. Simple switching reduces some of this load (but there will be much more on this part of the equation as we move along).
Beyond Bridging: Open vSwitch*
Enter the virtual switch. This is a sophisticated software version of what used to be done only in (usually expensive) hardware components. While there are several software switches in the marketplace today, we will keep our focus to the most prominent of open source variants: Open vSwitch* (OvS*).
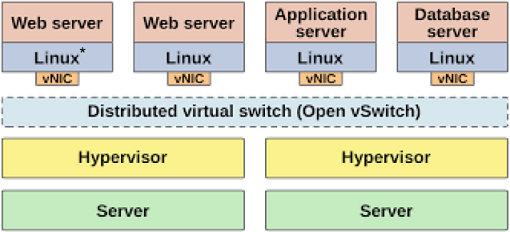
Figure 1. Graphic: By Goran tek-en (own work derived from: virtual networking)
[CC BY-SA 3.0 (https://creativecommons.org/licenses/by-sa/3.0)], via Wikimedia Commons
OvS offers a robust, extensible switching architecture that enables sophisticated flow control and port isolation. It is used as the underlying basis for many of the more advanced technologies that will be discussed later in this article. Due to its extensibility, it can also be modified by vendors who want to add proprietary technologies of their own. As such, OvS is frequently a critical piece of the modern data center.
It is also programmable, both with OpenFlow* and with its own management system. This makes it a common choice as an underlying technology for VM and container management and orchestration systems (notably OpenStack*, which we will cover later).
Getting Help from Hardware: SR-IOV
Returning to performance as an issue in dense, virtualized environments, let’s take a look at some in-hardware solutions that have arisen to help matters.
Earlier, we mentioned interrupts as being problematic as the number of virtual devices on a server host proliferates. These interrupts are a constant drain on the OS kernel. Furthermore, if you think about how the networking we’ve described so far works, there are multiple interrupts being generated for each packet that arrives or departs on the physical wire.
For example, if a packet arrives at the physical NIC, a processor core running the hypervisor will receive an interrupt to deal with it. At this point it will be dispositioned using the kernel’s native network stack, and forwarded to the virtual NIC it is bound for. Forwarding in this case means copying that packet’s contents to the appropriate memory space for the virtual NIC it is bound for, and then a new interrupt is sent to the hypervisor for the core that is running that VM. Already we’ve doubled the number of interrupts, memory addresses, and processor cores that have to deal with the packet. Finally, inside the VM, yet another interrupt is delivered to the virtual kernel.
Once we add in potential additional forwards from more complicated scenarios, we will end up tripling, or more, the amount of work that the server host has to perform for each packet. This comes along with the overhead of interrupts and context switches, so the drain on system resources becomes very significant, very rapidly.
Relieving Major Bottlenecks in Virtualized Networking
One of the first ways to alleviate this problem was a technology introduced in Intel® network interface cards, called Virtual Machine Device Queues* (VMDQ*). As the name implies, VMDQ allocates individual queues within the network hardware for virtual machine NICs. This way, Layer-2 sorting of packets on the wire can be directly copied to the memory of the VM that it is bound for, skipping that first interrupt on the hypervisor core. Likewise, outbound packets from VMs are copied directly to the allotted queue on the NIC. [Note: VMDQ support is not included in the Linux/kernel-based virtual machine (KVM*) kernel, but it is implemented in several other hypervisors.]
This removal of Layer-2 sorting from the hypervisor’s work provides a definite improvement over basic bridging to VMs. However, even with VMDQ, the kernel is still operating with interrupt-based network I/O.
SR-IOV: It’s Like Do Not Disturb Mode for Hypervisors
Single root input/output virtualization, (SR-IOV), is a mouthful to say, but it is a boon to operators that require high-speed processing of a high volume of network packets. A lot of resources exist to explain SR-IOV, but we will try to distill it to its essence. To use SR-IOV, hardware that implements the specification must be used, and the technology enabled. Usually this capability can be turned on via the server BIOS.
Once available, a hypervisor can equip a given virtual machine with a virtual function (VF), which is a lightweight virtual Peripheral Component Interconnect express (PCIe) device pointer unique to that VM. By accessing this unique handle, the VM will communicate directly with the PCIe NIC on its own channel. The NIC will then directly sort incoming packets to the memory address of the virtual NIC of the VM, without having to communicate with the hypervisor at all. The sole interrupt is delivered directly to the VM’s kernel. This results in substantial performance improvements over bridging, and frees up the host kernel to manage actual workloads, rather than spending overhead on packet manipulation.
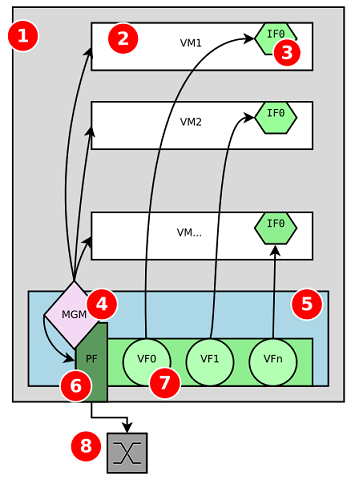
Figure 2. Diagram of SR-IOV. 1=Host, 2=VM, 3=Virtual NIC, 4 = Hypervisor (for example, KVM*), 5=Physical NIC, 6 = Physical Function, 7 = Virtual Function, 8 = Physical Network.
Graphic: By George Shuklin (own work)
[CC BY-SA 3.0 (https://creativecommons.org/licenses/by-sa/3.0)], via Wikimedia Commons
This performance boost does come with a caveat that should be well understood. In completely bypassing the host OS kernel, there is no easy way to filter or internally route traffic that is delivered over SR-IOV VFs. So, for example, virtual NICs won’t be plumbed into an OvS, where they can be directed out onto specific VLANs or otherwise manipulated. For another example, they can’t be firewalled by the host.
What this means is that using SR-IOV technology should be a careful and deliberate choice: to favor speed over flexibility, in certain ways. While it is the fastest way to deliver traffic over a shared physical NIC to VMs, there are other, more flexible methods of doing so that also avoid interrupt proliferation.
Power to the User: Data Plane Development Kit (DPDK)
We’ve discussed performance quite a bit at this point. Let’s return for a moment to the question of security. When packets are all processed within the host server’s kernel, this results in a somewhat weaker security profile. A single VM that becomes compromised could conceivably elevate privilege and have access to all packet flows on the host. Just as we run virtual machines in user mode to prevent that privileged access, we can remove network packet processing from the kernel and into user mode as well. As an additional benefit, we can improve performance at the same time by polling physical network devices instead of requiring them to interrupt the host kernel.
The way we accomplish these results is with the Data Plane Development Kit (DPDK). The DPDK is a set of libraries that can be used to speed applications that perform packet processing. Therefore, to take advantage of the DPDK, we need to run applications that are programmed and linked with these libraries. Fortunately, one application that can be relatively easily enabled for DPDK usage is OvS!
Major Linux distributions such as CentOS* and Ubuntu* provide DPDK-enabled versions of OvS in their distribution repositories for easy installation. Once installed and configured correctly, the DPDK-enabled OvS supports user space data paths. Physical NICs that are configured for use with the DPDK driver, instead of the normal kernel driver, do not route traffic through the kernel at all. Instead, traffic is handled directly by OvS outside of the kernel.
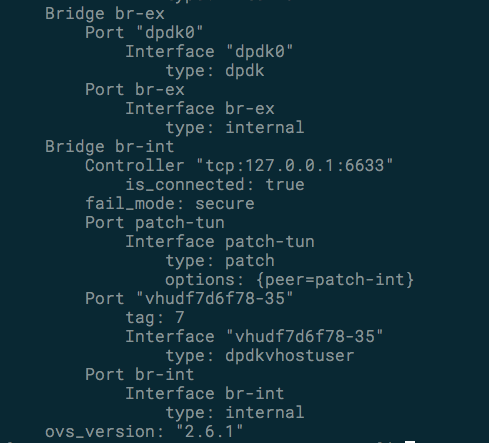
Figure 3. Output from an OvS* command that shows DPDK*-enabled ports. The top ‘dpdk0’ port is a physical interface, while ‘vudf7d6f78-36’ is a dpdkvhostuser port attached to a running VM.
Also, the DPDK-enabled OvS can support poll mode drivers (PMD). When a NIC device, controlled by the DPDK driver, is added to an OvS bridge, a designated processor core or cores will assume the responsibility of polling the device for traffic. There is no interrupt generated. VMs added to the same bridge in OvS will use the ‘dpdkvhostuser’ port (or the newer ‘dpdkvhostuserclient’) to enable the virtual NIC. On Linux/KVM, the VM will use the well-known virtio driver to represent the port. The dedicated core(s) will handle traffic direction without disrupting other cores with floods of interrupts, especially in a high-volume environment.
The DPDK also utilizes HugePages* on Linux to directly access memory regions in an efficient manner. When using the DPDK, virtual machine memory is mapped to HugePage regions, which OvS/DPDK is then able to use for direct reads and writes of packet contents. This memory utilization further speeds packet processing.
OvS flexibility enables a high-performing virtual networking environment while still being able to route and filter packets. Note that this routing and filtering must be accomplished via other user-space processes, since the OS kernel is not receiving or viewing the packet flows.
The DPDK offers far more than just the PMD and functionality with OvS. These are known use cases that work in high-volume networking installations. Any network application can be coded to use the DPDK and benefit from the direct delivery and retrieval of packet contents to its own memory addresses. In the next segment, we’ll look at a technology that also uses the DPDK (but not OvS), to power an innovative packet processing engine.
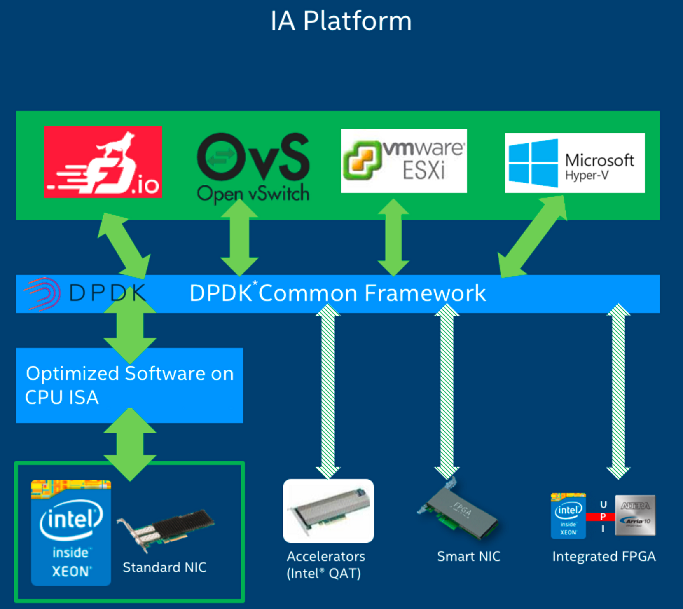
Figure 4. The many technologies that DPDK interrelates. Shown here supporting OvS* and VPP switches, along with others, are different varieties of NICs, accelerators, and field programmable gate array (FPGA) devices.
[Graphic: Intel]
The Software Data Plane: FD.io* and VPP
Our next technology is actually software that has been around since 2002, running on specialized networking hardware. With the most up-to-date and powerful data center server offerings, however (such as the Intel® Xeon® Scalable processor family), it is capable of performing very well on general-purpose servers. It is also now open source, enabling a rapidly-growing development community to make it even better. The technology is called vector packet processing (VPP), an innovative take on dealing with high-volume network traffic.
For clarity around names: FD.io* (pronounced Fido by its community) stands for Fast Data–Input/Output, and is the name of the Linux Foundation* project that sponsors VPP development, along with related technologies and development libraries. Sometimes we see FD.io, VPP, and FD.io VPP used interchangeably, even though they are not all quite the same thing. Throughout this article, we will primarily refer to VPP specifically.
VPP functions by working with bursts of packets, rather than individual packets at a time. It processes this burst, or frame, or vector of packets on a single processor core, which allows for efficient use of the core’s instruction cache. This works well because, essentially, the same set of operations needs to be performed on each packet regardless of its content (read the header, determine next-hop, and so on).
VPP also relies on the statistical likelihood that many of the packets in a given frame are part of the same communication, or at least bound for the same location. This results in efficient use of the core’s data cache in a similar fashion as the instructions. By exploiting the processor cache well, repetitive instructions and data are utilized to maximize packet throughput.
VPP is extensible, using a graph node architecture that can accommodate externally developed plugins as full partners. For example, the initial node that an incoming frame encounters is solely tasked with sorting traffic by protocol: IPv4, IPv6, address resolution protocol (ARP), multiprotocol label switching (MPLS), and so on. The frame isn’t broken up, but the sorter ascertains the most efficient node for that grouping of packets—if the majority are IPv4, then the frame will be forwarded to the IPv4 node. Frames move to the next node that is assigned to that particular protocol’s input processing role.
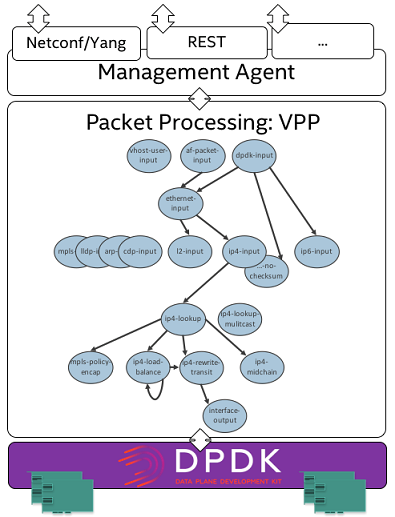
Figure 5. Some of the native VPP nodes displayed in the node graph layout. DPDK underpins and controls the physical NICs.
This process continues with the packets moving like a train through the nodes of the graph until they encounter the output node, where they are forwarded to their destinations. Plugins can be written that insert into this graph of nodes at any point a developer desires, allowing for rapid, specialized processing.
VPP already integrates many components, and can fully replace software switches and routers with its own variants. It is written to take full advantage of DPDK and uses the dpdkvhostuser semantics natively. Like DPDK, it is also a set of libraries that developers can use to improve their network application performance. The goals of the FD.io project teams are ambitious, but achievable—they look forward to achieving up to 1Tb/s throughput on an industry standard, two-socket server with Intel Xeon Scalable processors.
Moving Up the Stack: Network Function Virtualization (NFV)
We will very briefly touch on some higher-level technologies that utilize those we already discussed. Most details here are outside the scope of this article, but links are included, should you wish to dive further into this realm.
Network Function Virtualization
The compelling market advantage of dense virtualization extends to more than just general-purpose computing. Just like OvS and VPP implement a hardware network switch in software, many other purpose-built network components that have traditionally been sold as discrete pieces of hardware can be implemented and run in software as virtual network functions, or VNFs. These run in specialized virtual machines, and each VNF specializes in a particular network function. (We’ll note here that VNFs themselves can greatly benefit in performance from being developed with FD.io libraries!)
Examples of typical VNFs include firewalls, quality-of-service implementations, deep packet inspectors, customer premises equipment (CPE) and similar high-capacity packet processing functions. Putting together an infrastructure that supports the use of VNFs results in NFVI: network function virtualization infrastructure.
There are many components to a proper NFVI. We will review some of them here, but a full examination of NFVI is outside of our scope. It is enough, here, to realize that the technologies we have introduced have combined to make NFV a reality in the industry. These technologies underpin much of what constitutes NFVI.
On the Control Plane: Software-Defined Networking
At the heart of many NFVI deployments is a software-defined networking (SDN) infrastructure. We mentioned earlier that OvS can be programmed remotely via OpenFlow or native commands. An SDN control surface can exploit this capability to allow for the automatic creation, update, and removal of distributed networks across a data center infrastructure. The controller can then itself expose an application programming interface (API), and allow automated manipulation of the entire data center’s virtualized network infrastructure.
SDNs are core components of many cloud computing installations for this reason.
OpenDaylight* is an open source example of an SDN. Another project of the Linux Foundation, it can work with OvS (among many other technologies) on the control plane, and can be driven by the OpenStack Neutron* cloud networking service.
Virtualized Infrastructure Management: Orchestrating NFVI
Though OpenStack is mostly known as a cloud computing and cloud storage system, in the NFVI world it can function as a virtualized infrastructure management (VIM) solution. When combined with other NFVI components and layered over an SDN, which is in turn using the advanced networking capabilities outlined earlier in this article, a VIM can work as a full-featured NFV factory, generating and scheduling VNFs in response to demand, and tying them together in a process known as service chaining.
To put all that together, if OpenStack were laid over an OpenDaylight SDN, which in turn was in control of servers enabled with OvS and DPDK, using KVM for virtualization, we would have an NFV-capable infrastructure.
VIMs are not limited to OpenStack. For example, there is much interest in Kubernetes* as a VIM. Kubernetes is newer and natively works with container technology, which can be a good fit for VNFs in some cases. It is less feature-rich than OpenStack, and requires additional tooling choices for managing virtual networks and other functions, but some appreciate this leaner approach.
The aim of the Open Platform for Network Function Virtualization* (OPNFV*) project is to specify and create reference platforms for exactly this kind of infrastructure.
Summary
Clearly, the world of advanced networking is burgeoning with advancements and rapid development. Dense virtualization has offered both challenge and opportunity for network throughput. It is an exciting time for networking on commodity data center server components.
OvS implements a sophisticated software switch that is fully programmable. When it is built against the DPDK, it achieves high throughput by enabling direct insertion of packets off the wire into the memory space of the VMs attached to it, and removes the performance and security problems of kernel-mode, interrupt-driven network stack usage.
SR-IOV offers phenomenal performance by giving each VM on a system its own lightweight PCIe extension. Hardware enabled for SR-IOV can bypass the host OS entirely and place packets directly into the memory space of the VM they are bound for. This offers very high throughput, but does come at the cost of some reduced flexibility for on-host routing and filtering.
FD.io/VPP, like OvS, works with DPDK, and is an innovative software technique for maximizing the use of a server’s CPU caching. It also offers ready-made switches and routers (and many other components), along with libraries for developers to use its high-throughput capabilities for their own networking applications.
Up the stack, NFV infrastructure works with software-defined networking control plane deployments, such as OpenDaylight, to automate the creation, update, and removal of networks across the data center. SDNs can work with OvS-DPDK and VPP to maximize throughput across the data center on commodity servers. NFVI is managed by a virtualized infrastructure manager (such as OpenStack), to deploy and maintain service chains of VNFs.
We hope this overview is of use to the curious; it is, of course, very high level and general. We offer the following selection of linked resources to further your understanding of these technologies.
Resources
Open vSwitch
- Production Quality, Multilayer Open Virtual Switch.
SR-IOV
- Intel SR-IOV Explanation. This video, while quite old, still offers the best and clearest explanation of how SR-IOV works.
DPDK
- DPDK: Data Plane Development Kit.
- Open vSwitch with DPDK. The manual instructions for enabling DPDK in OvS. Still useful if using the RPM* or Debian* packaging, since configuration after installation takes some work as well.
FD.io/VPP
- FD.io - The Fast Data Project: The Universal Dataplane.
NFV/SDN/Further Up the Stack
- Intel Developer Zone: Networking.
- Nitrogen Released: Download the latest version of the OpenDaylight platform, OpenDaylight.
- OPNFV.
About the Author
Jim Chamings is a Sr. Software Engineer at Intel Corporation. He only recently took on NFV and advanced networking as a specialty, pairing it with an extensive background in cloud computing. He works for the Intel Developer Relations Division, in the Data Center Scale Engineering team. You can reach him for questions, comments, or just to say howdy, at jim.chamings@intel.com.