Overview
The Persistent Memory Pool abstraction in the open source Persistent Memory Development Kit (PMDK) libpmemobj library simplifies access to application data that is stored in persistent memory by adding some features on top of traditional memory mapped files. In this article we discuss in detail what a pool is, how to create and access pools, and explore a full code example that demonstrates the usage of pools.
Persistent Memory
This article assumes that you have a basic understanding of persistent memory concepts and are familiar with some of the elementary features of the PMDK. If not, please visit the Intel® Developer Zone Persistent Memory Programming site, where you'll find the information you need to get started.
What are Persistent Memory Pools?
Memory mapped files are at the core of the persistent memory programming model. The libpmemobj library was introduced in order to simplify programming against these memory mapped files. The library provides an API to easily manage pool creation and access, avoiding the complexity of directly mapping and synchronizing data.
At the operating system (OS) level, persistent memory is exposed as a special block device that applications can use as byte-addressable memory from user space by memory-mapping files residing on those special devices. In PMDK terminology, these files are called Persistent Memory Pools. In every pool we have a root object. This object is necessary, and used as an entry point from which to find all the other objects created in a pool. The way that we interface with a pool in PMDK is with a special object called Pool Object Pointer (POP). The POP object resides in volatile memory and it is created with every program invocation. It keeps track of metadata related to the pool, such as the offset to the root object inside the pool. We commonly use the POP to get a pointer to the root object. Let's look at a diagram that depicts this:
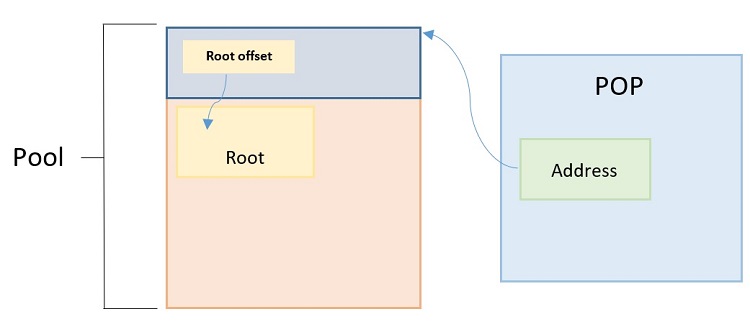
Due to the nature of virtual memory, the location of the pool in the memory address space of the process can differ between multiple executions. POP gives us a function called get_root(), which returns a usable pointer to our root object in persistent memory. Internally, this function creates a valid pointer by adding the current memory address of the mapped pool plus the internal offset to the root. Let's take a look at a sample pool called pop:
auto q = pop.get_root();
Pool Interface
Libpmemobj allows developers to easily create, open, and close pools. Let's take a look at an example:
if (access(path.c_str( ), F_OK != 0){
pop = pool<root>::create(path, "my_layout" , poolsize, S_IRWXU);
} else {
pop = pool<root>::open(path, "my_layout");
}
pop = pool<root>::close(path, "my_layout");
}
In this example we start by trying to identify whether the pool exists. If the pool doesn't exist, the pool is created using the pool::create function and automatically opened. The create() function has four arguments: The first is path, which defines the pool location (for example: path=/path/to/my_pmem_location); second, we have my_layout, which is a string that you choose to uniquely identify the pool; then we have poolsize, which defines the size of the pool in bytes; and finally, the mode flags to specify the permissions to set when creating the pool file (in our case, S_IRWXU). Since this is persistent memory, we need to create and initialize our pool only once.
If the pool exists, it is opened using the pool::open function. The open() function has two arguments: path as described above, and my_layout, which is again the string used to identify the pool. When you are done accessing the pool and it is no longer being used, you must then release it using close().
In addition to these basic functions, pools also provide additional functions to control synchronization of our data residing in persistent memory. These additional functions are flush, drain, persist, memcpy_persist, and memset_persist. Let's first discuss flush and drain, since that will help us understand persist. Although we write to persistent objects, recent writes might still sit unflushed in the CPU caches. If a power cycle were to happen at that moment, we can end up with corruption in our persistent data structures. The flush function is responsible for flushing persistent objects residing in persistent memory. Another function of pools is drain, which is used to create a barrier – a synchronization point for all impending flushes. While both these functions are important, the most commonly used function for managing synchronization of data is persist. Persist combines flush and drain, and is responsible for flushing persistent memory out of the CPU caches, while also making sure that all the flushes finish.
Depending on what the underlying hardware supports, libpmemobj will use different types of flushing inside persist. For example, if the pool file is stored in a regular block device, it will use msync() for synchronization. This involves the file system and writing whole blocks of data (usually 4KB in size) which is very inefficient. If, on the other hand, we have a supported persistent memory device, flushing involves simple CPU instructions executed from user space. In that case, flushing is done at cache line granularity.
Example
Now that we have a good idea of what a pool is and some of the functions supported by its interface, let's take a look at simple examples using persistent memory pools. In this example we will look at part of the Panaconda code sample. Panaconda is a game of Snake that demonstrates persistent memory pools, pointers, and transaction, and can be found in this GitHub* repository. You can learn more by reading the article Code Sample: Panaconda - A Persistent Memory Version of the Game Snake. Here we dive into a small code snippet:
pool<game_state> pop;
if (pool<game_state>::check(params->name, LAYOUT_NAME) == 1)
pop = pool<game_state>::open(params->name, LAYOUT_NAME);
else
pop = pool<game_state>::create(params->name, LAYOUT_NAME, PMEMOBJ_MIN_POOL * 10, 0666);
pop = pool<game_state>::close(params->name, LAYOUT_NAME);
The code snippet above was taken from the game class, which is responsible for checking to see if the game file specified already exists. Once the user specifies the persistent memory pool filename in params->name, it checks for a match with the name of an existing pool. If the pool exists, that pool is opened and the game resumes using the objects persisted in the pool.
If the pool name does not match an existing pool, a new pool is created with the specified name. Once you're done with the pool you must close it, as done in the last line after the if statement above.
Let's also look at a real example of finding the root object from the same Panaconda code sample. In Panaconda, the game class is the root object (object that anchors all other objects inside the pool). This root initialization happens in the init() function of the game—which is responsible for initializing the game at program startup. The code snippet below shows how to retrieve the root. This involves a call to the get_root function:
persistent_ptr<game_state> r = state.get_root();
Summary
The goal of this article is to introduce you to the concept of persistent memory pools and how application developers can employ this abstraction of the libpmemobj library from PMDK for persistent memory programming.
A pool is essentially a file stored on persistent memory. The three main functions in the pool interface are create, open, and close. These functions behave as their name suggest, that is, create is used to create and open a new pool, open simply opens an already existing pool, and close closes an opened pool. With pools we can also get a pointer to our root object with the get_root function, as well as synchronize data with functions such as persist. To find more persistent memory programming examples, visit the PMDK examples repository on GitHub.