Intel continues to enable support and optimize performance for open-source models to accelerate AI solutions across datacenter, client, and edge environments. Following up on the recent release of Qwen3, the latest addition to the Qwen family of large language models (LLMs), we are thrilled to share our initial performance benchmarking results and use case demos.
Qwen3 launches a family of LLMs ranging in models from 0.6B to 235B parameters, two of which are Mixture-of-Experts (MoE) models - Qwen3-30B-A3B and Qwen3-235B-A22B. MoE models are gaining in popularity as they can be computationally more efficient; by breaking down tasks into subtasks and then delegating subtasks into smaller, specialized “expert” models, MoE models like Qwen3-30B-A3B can be computationally more efficient to process vs. traditional (“dense”) models. In addition, Qwen3 deploys a dual-mode system, allowing users to toggle between depth/complexity (“thinking mode”) and speed/responsiveness (“non-thinking mode”), depending on the task. Coupled with increased multilingual support and agentic abilities that integrate with external tools, Intel is excited to support Qwen3 models running across our many product lines.
AI PCs
PCs and Edge devices are at the forefront of delivering AI experiences designed to assist users while remaining personalized and private. Intel enables AI language models to run locally on AI PCs powered by Intel® Core™ Ultra processors that feature a neural processing unit (NPU) with a built-in Intel® Arc™ GPU, or on Intel® Arc™ discrete GPUs with Intel® Xᵉ Matrix Extensions (Intel® XMX) AI acceleration. The Qwen3 release includes models that are ideal for on-device inference including highly efficient reasoning on the Qwen3-30B-A3B MoE model. For example, we ran this MoE model on an Intel® Core™ Ultra 9 285H processor with a built-in Intel® Arc™ GPU and saw a throughput of 34 tokens per second.
Along with the MoE models, Qwen3 has launched six dense models, including Qwen3-8B. You can see below the results of Qwen3-8B running across our Intel® Arc™ GPUs in two configurations: (1) built-in Intel® Arc™ GPU in our Intel® Core™ Ultra 7 258V processor, and (2) a discrete Intel® Arc™ B580 desktop graphics card:

Figure 1. Qwen3-8B throughput on Intel® Arc™ GPU
Through our extensive ecosystem and enablement, Intel is also the only company to support Qwen3 language models running on the NPU, at launch, also commonly referred to as providing Day 0 support. Intel has a long history of supporting the open-source ecosystem, providing more diverse and targeted platform support for different models and application scenarios. Below you can see several Qwen3 LLMs running on the NPU of the Intel® Core™ Ultra 7 258V processor.
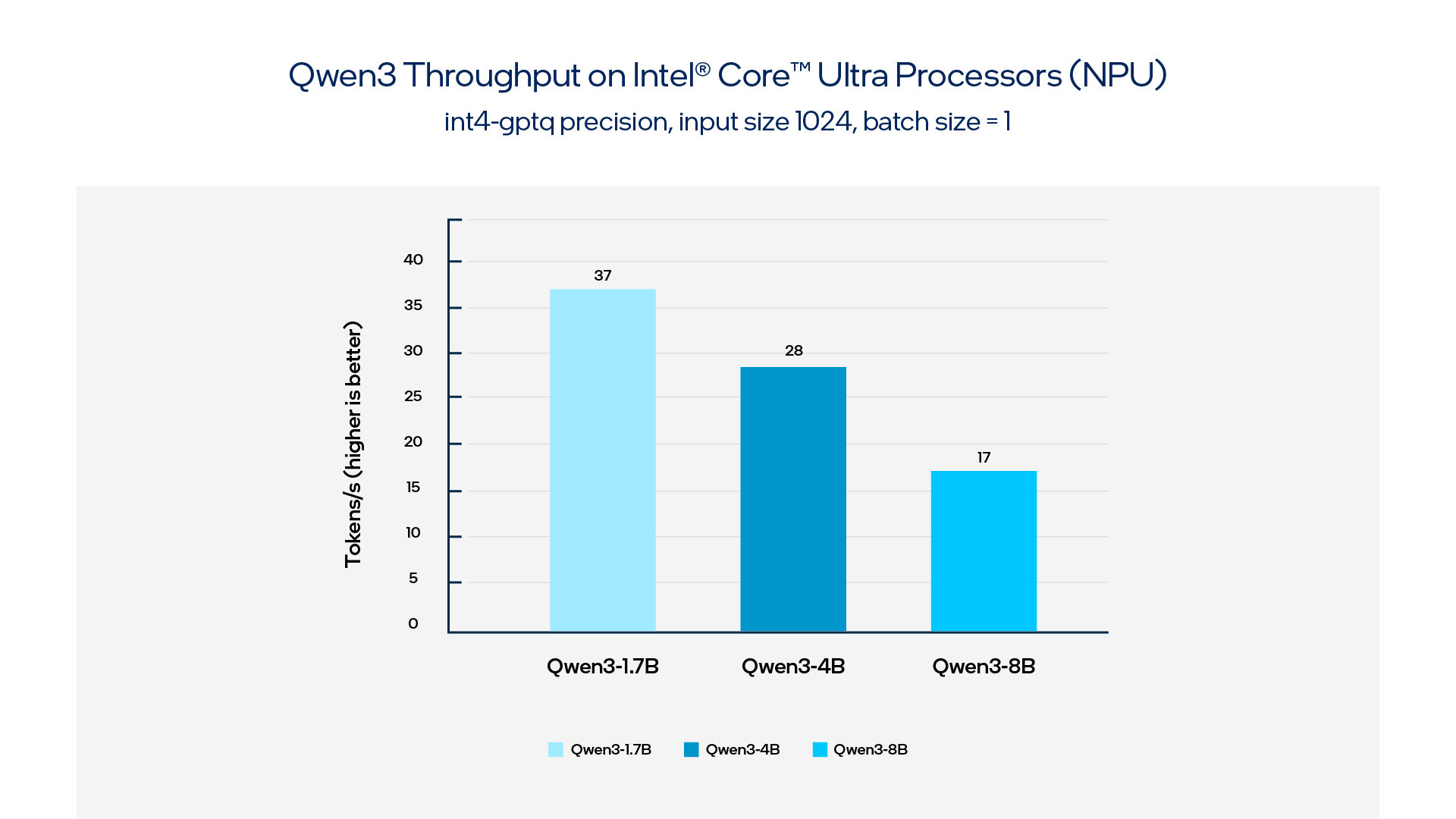
Figure 2. Qwen3 throughput on Intel® Core™ Ultra Processors (NPU)
Smaller LLMs offer the advantage of flexible, efficient lightweight deployment, supporting quicker iterations and model updates. However, smaller LLMs trade-off depth and breadth of their knowledge while handling complex tasks. By fine-tuning these small LLMs with the help of specific datasets, end-users can improve model intelligence and optimize their user experience. To this end, based on Unsloth and Hugging Face’s Parameter-Efficient-Fine-Tuning (PEFT) framework, Intel has established a complete set of device-side solutions to improve smaller models, allowing for more personalized intelligent assistants.

Demo 1. Fine-tuning client AI models with domain specific datasets to improve the accuracy of image search
Qwen3 also introduces a significant improvement in the LLM long context capability. By implementing dynamic sparse attention, Intel has provided an efficient solution to leverage long context abilities in Qwen3 while avoiding an exponential increase in computing resources. In doing so, Intel is helping to maximize LLM applications on local clients and expand to broader audiences and applications, helping unlock more applications for device-side agents. Check the below demo to see the difference in first-time-to-token with the optimizations on (~34 seconds) vs. optimization off (~1m 28s).

Demo 2. Deploying dynamic sparse attention to boost long context window processing time and performance (32K context length)
Intel continues to embrace the open-source and AI ecosystem, and we are ready with Ollama and PyTorch* support for Qwen3 series models, including the MoE models. In doing so, we are enabling developers to use the Ollama and PyTorch framework to build intelligent applications based on the Qwen3 series of models across AI PCs powered by Intel® Core™ Ultra processors and Intel® Arc™ graphics. At the same time, Intel remains committed to delivering the best performance, efficiency and experience on AI PCs with the OpenVINO™ toolkit, an open-source toolkit that speeds up AI inference and improves latency and maximizes throughput. Developers can effortlessly deploy Qwen3 on Intel hardware using the OpenVINO™ toolkit, empowering them to create a diverse array of LLM-based applications to run on AI PCs while effectively leveraging heterogeneous compute for efficient AI inference.
Intel® Gaudi® AI Accelerators
Intel® Gaudi® 3 AI accelerators are designed from the ground up for AI workloads and benefit from vector processors, and eight large Matrix Multiplication Engines compared to many small matrix multiplication units that a GPU has. This leads to reduced data transfers and greater energy efficiency. Intel Gaudi 3 is equipped with 128GB HBM2e to help with the smooth running of the model. We have benchmarked the throughput for inference and the performance metrics are detailed below.

Table 1. Qwen3 inference on Intel® Gaudi® 3 Accelerators
Intel® Xeon® Processors
Intel® Xeon® processors address more demanding end-to-end AI workloads. It is offered as an excellent choice for deploying small-to-medium-sized LLMs. Intel Xeon’s substantial memory capacity makes it an advantage of running MoE models in deployments with small to medium concurrency. Widely available through major cloud service providers, Intel® Xeon® Scalable Processors have Intel® Advanced Matrix Extensions (Intel® AMX) in each core, enhancing performance for both inference and training tasks. Intel® Xeon® 6 processors with Intel AMX instructions, substantial memory capacity, and increased memory bandwidth with MRDIMMs, offer a cost-effective solution for deploying MoE models like Qwen3-30B and middle-size dense model like Qwen3-14B.

Table 2. Qwen3 inference on Intel® Xeon® 6 Processors
The table above shows the concurrency, latency and throughput for real time inference scenarios, while for offline inference scenarios, Intel Xeon can provide much bigger throughput because of the memory capacity advantage.
Summary
In conclusion, Intel AI PCs support Qwen3 models at launch, and Intel is the only company to provide Day 0 support for running these models on the NPU. For more demanding end-to-end AI solutions, Intel Xeon processors are well-suited for MoE models and offer an option for broader deployments across standard servers. For high-performance acceleration of Generative AI and LLMs, deploying Qwen3 models with vLLM on Intel Gaudi 3 accelerators offers optimal throughput. While more performance enhancements are on the way, developers can start deploying Qwen3 today on Intel platforms by following the steps below:
Product and Performance Information
(“Arrow Lake”) Intel® Core™ Ultra 9 285H Processor Configuration:
Laptop Model: Intel CSRD (Reference Design), CPU: Intel® Core™ Ultra 9 285H processor, Memory: 64GB LPDDR5-8400MHz, Storage: 1TB, OS: Windows 11, OS Version: 24H2 (26100.3775), Graphics: Intel Arc 140T GPU, Graphics Driver Version: 32.0.101.6737, Resolution: 2880 x 1800 200% DPI, NPU Driver Version: 32.0.100.3967, PC BIOS: -, Screen Size: 15", Power Plan: Balanced, Power Mode (Win 11 Feature): Best Performance, Power App Setting (OEM's Power App): -, VBS: OFF, Defender: Running, Long Duration Package Power Limit (W): 65, Short Duration Power Limit (W): 70, Key Software Version: OpenVINO 2025.2.0-dev20250427, Openvino-genai 2025.2.0.0-dev20250427, OpenVINO-tokenizers 2025.2.0.0-dev20250427, Transformers 4.49.0. Tested on April 28th, 2025.
(“Lunar Lake”) Intel® Core™ Ultra 7 258V Processor Configuration:
Laptop Model: Lenovo Yoga Air 15s ILL9, CPU: Intel® Core™ Ultra 7 258V processor, Memory: 32GB LPDDR5-8533MHz, Storage: WD PC SN740 1TB, OS: Windows 11, OS Version: 24H2 (26100.3624), Graphics: Intel Arc 140V GPU, Graphics Driver Version: 32.0.101.6737, Resolution: 2880 x 1800 200% DPI, NPU Driver Version: 32.0.100.3967, PC BIOS: NYCN66WW, Screen Size: 15", Power Plan: Balanced, Power Mode (Win 11 Feature): Best Performance, Power App Setting (OEM's Power App): Extreme Performance, VBS: OFF, Defender: Running, Long Duration Package Power Limit (W): 30, Short Duration Power Limit (W): 37, Key Software Version: OpenVINO 2025.2.0-dev20250427, Openvino-genai 2025.2.0.0-dev20250427, OpenVINO-tokenizers 2025.2.0.0-dev20250427, Transformers 4.49.0. Tested on April 28th, 2025.
(“Battlemage”) Intel® Arc™ B580 Desktop Graphics Card Configuration:
CPU: Intel® Core™ i7-14700K, Memory: 32GB DDR5-5600MHz, Storage: SAMSUNG 980 PRO 1TB, OS: Windows 11, OS Version: 24H2 (26100.3775), Graphics Driver Version: 32.0.101.6737, Resolution: 2560 x 1440, NPU Driver Version: n/a, PC BIOS: 2801, VBS: OFF, Defender: Running, Long Duration Package Power Limit (W): -, Short Duration Power Limit (W): -, Key Software Version: OpenVINO 2025.2.0-dev20250427, Openvino-genai 2025.2.0.0-dev20250427, OpenVINO-tokenizers 2025.2.0.0-dev20250427, Transformers 4.49.0. Tested on April 28th, 2025.
Intel® Gaudi® AI Accelerator: Measured with 1 Intel® Gaudi® server with 1 or 4 Intel® Gaudi® 3 AI Accelerators. 2 socket Intel® Xeon® Platinum 8480+ CPU @ 2.00GHz. 1TB System Memory. OS: Ubuntu 22.04. Intel Gaudi software suite, version 1.20.0-543. vLLM from https://github.com/HabanaAI/vllm-fork/tree/dev/qwen3. Tested on May 2nd, 2025.
Intel® Xeon® Processor: Measurement on Intel® Xeon® 6 Processor (formerly code-named: Granite Rapids) using: 2x Intel® Xeon® 6 6980P with P-cores, HT On, Turbo On, NUMA 6, Integrated Accelerators Available [used]: DLB [8], DSA [8], IAA[8], QAT[on CPU, 8], Total Memory 1536GB (24x64GB MRDIMM 8800 MT/s [8800 MT/s]), BIOS BHSDCRB1.IPC.3544.D02.2410010029, microcode 0x11000314, 1x Ethernet Controller I210 Gigabit Network Connection 1x Micron_7450_MTFDKBG960TFR 894.3G, CentOS Stream 9, 6.6.0-gnr.bkc.6.6.16.8.23.x86_64. Test by Intel on 29th Aprill 2025. Detail benchmarking steps can be found at https://github.com/intel/intel-extension-for-pytorch/blob/2.8-pre-qwen3/docs/index.md
Notices & Disclaimers
Performance varies by use, configuration and other factors. Learn more on the Performance Index site. Performance results are based on testing as of dates shown in configurations and may not reflect all publicly available updates. See backup for configuration details. No product or component can be absolutely secure. Your costs and results may vary. Intel technologies may require enabled hardware, software or service activation.
Intel Corporation. Intel, the Intel logo, and other Intel marks are trademarks of Intel Corporation or its subsidiaries. Other names and brands may be claimed as the property of others.
AI Disclaimer
AI features may require software purchase, subscription or enablement by a software or platform provider, or may have specific configuration or compatibility requirements. Details available at http://www.intel.com/AIPC. Results may vary.