Introduction
INT8 quantization is one of the key features in PyTorch* for speeding up deep learning inference. By reducing the precision of weights and activations in neural networks from the standard 32-bit floating point format to 8-bit integer format, INT8 quantization can significantly reduce the memory bandwidth and computational resources required for inference, allowing for faster and more energy-efficient execution. Before PyTorch 2.0, the default quantization backend on x86 CPUs was named “FBGEMM” which leveraged the FBGEMM performance library to achieve the performance speedup. In this post, we are introducing “X86” quantization backend, which is newly added in PyTorch 2.0 release and replaces FBGEMM as the default quantization backend for x86 platforms. The “X86” quantization backend offers improved INT8 inference performance compared to the original FBGEMM backend by leveraging the strengths of both FBGEMM and oneAPI Deep Neural Network Library (oneDNN) kernel libraries. It brough about 2.97X geomean INT8 inference performance speedup over FP32 (measured on a broad scope of 69 popular deep learning models) by taking advantage of HW-accelerated INT8 convolution and matmul with Intel® DL Boost and Intel® Advanced Matrix Extensions technologies on 4th Generation Intel® Xeon® Scalable Processors. The new backend is functionally compatible with the original FBGEMM backend.
Performance Benefit
We measured the performance of INT8 inference on 69 popular DL models using 4th Generation Intel® Xeon® Scalable Processors (r7iz.metal-16xl on AWS, single batch and 4 cores per instance). The new “X86” backend brought 2.97X geomean performance speedup compared to FP32 inference performance while the speedup was 1.43X with FBGEMM backend. Charts below show the per-model performance speedup comparing the new x86 backend and the FBGEMM backend, less than 2x, 2x~4x and larger than 4x respectively.
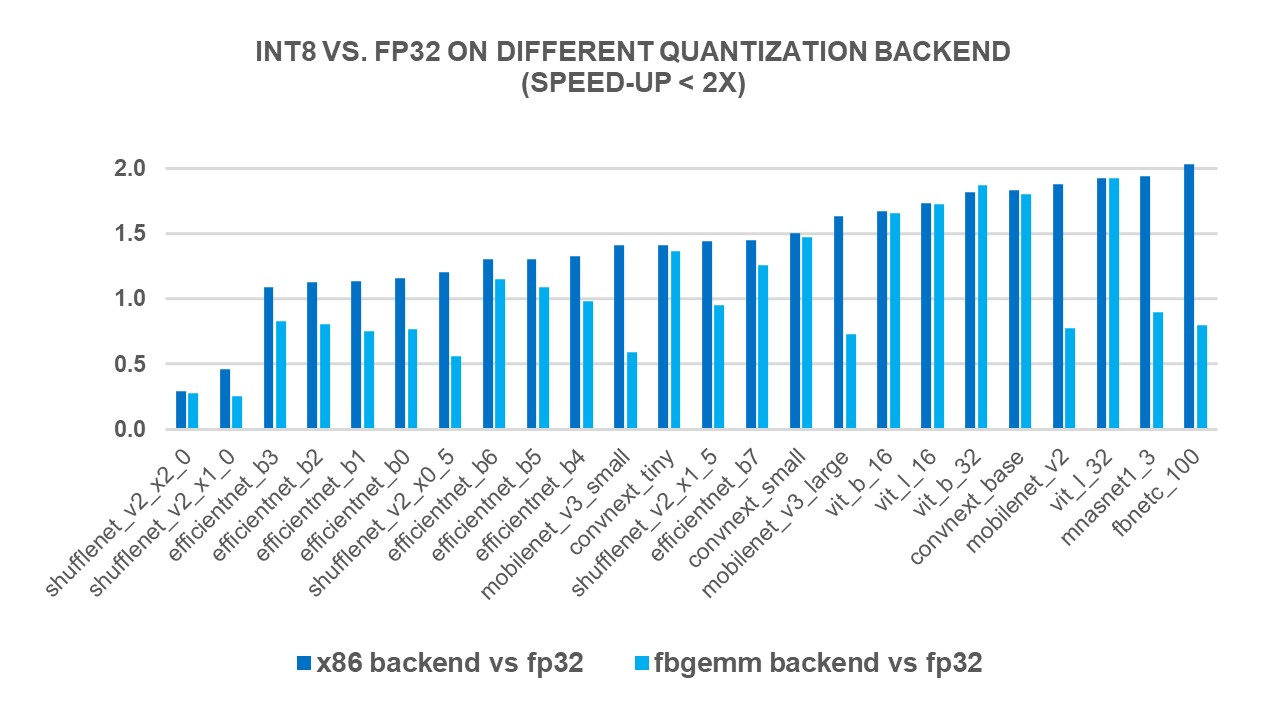
Figure 1: Models with less than 2x performance boost with the new "X86" backend
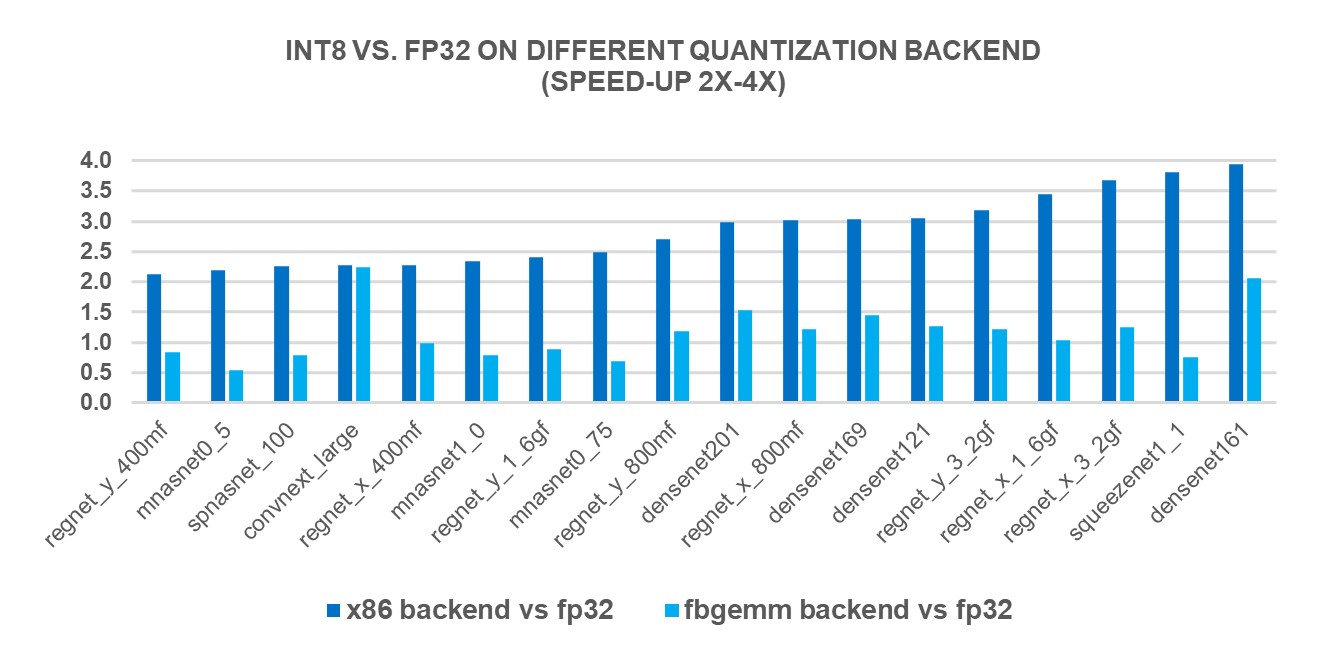
Figure 2: Models with 2x~4x performance boost with the new "X86" backend
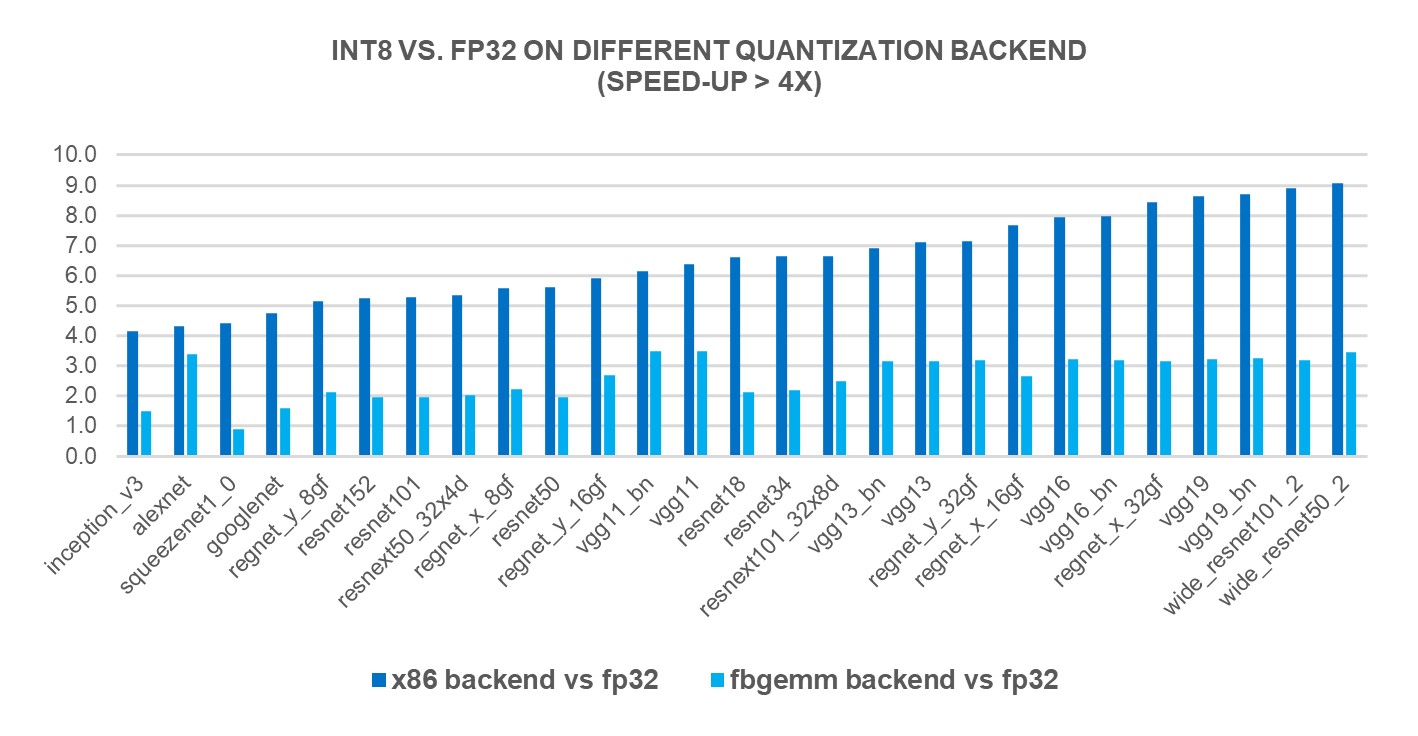
Figure 3: Models with larger than 4x performance boost with the new "X86" backend
Testing Date: Performance results are based on testing by Intel as of March 7, 2023 and may not reflect all publicly available security updates.
Configuration Details and Workload Setup: AWS EC2 r7iz.metal-16xl instance (Intel(R) Xeon(R) Gold 6455B, 32-core/64-thread, Turbo Boost On, Hyper-Threading On, Memory: 8x64GB, Storage: 192GB); OS: Ubuntu 22.04.1 LTS; Kernel: 5.15.0-1028-aws; Batch Size: 1; Core per Instance: 4; PyTorch 2.0 RC3; TorchVision 0.15.0+cpu.
How to Use
By default, users on x86 platforms will utilize the x86 quantization backend and their PyTorch programs will remain unchanged when using the default backend. Alternatively, users have the option to specify "X86" as the quantization backend explicitly.
Below is an example of PyTorch static post-training quantization with “X86” quantization backend.
import torch
from torch.ao.quantization import get_default_qconfig_mapping
from torch.quantization.quantize_fx import prepare_fx, convert_fx
from torchvision import models
qconfig_mapping = get_default_qconfig_mapping()
# or explicity specify the qengine
# qengine = 'x86'
# torch.backends.quantized.engine = qengine
# qconfig_mapping = get_default_qconfig_mapping(qengine)
class MyModel(torch.nn.Module):
def __init__(self):
super().__init__()
self.conv = torch.nn.Conv2d(in_channels=3, out_channels=16, kernel_size=3, stride=1)
self.relu = torch.nn.ReLU()
def forward(self, x):
x = self.conv(x)
x = self.relu(x)
return x
model_fp32 = MyModel().eval()
# Or use a pretrained real model
# model_fp32 = models.resnet50(weights=models.ResNet50_Weights.DEFAULT)
x = torch.randn((1, 3, 224, 224), dtype=torch.float)
x = x.to(memory_format=torch.channels_last)
# Insert observers according to qconfig and backend config
prepared_model = prepare_fx(model_fp32, qconfig_mapping, example_inputs=x)
# Calibration
calibration_data_loader = ...
for x in calibration_data_loader:
x = calibration_data_loader()
prepared_model(x)
# Convert to quantized model
quantized_model = convert_fx(prepared_model)
# Run quantized model
x = torch.randn((1, 3, 224, 224), dtype=torch.float)
x = x.to(memory_format=torch.channels_last)
y = quantized_model(x)
Technical Details
For more design and technical discussion, please refer to the RFC.
We devised heuristic dispatching rules according to the performance numbers from the models we benchmark to decide whether to invoke oneDNN or FBGEMM performance library to execute the convolution or matrix multiplication operations. The rules are a combination of operation kinds, shapes and CPU architecture information etc. Detailed logic is available here.
Summary
PyTorch 2.0 introduces a new quantization backend for x86 CPUs called “X86” that uses FBGEMM and oneDNN libraries to speed up int8 inference. It brings better performance than the previous FBGEMM backend by using the most recent Intel technologies for INT8 convolution and matmul. We welcome PyTorch users to try it out and provide us feedback.
Acknowledgement
We would like to thank Jerry Zhang, Nikita Shulga, and Jongsoo Park from Meta for providing valuable feedback and code reviews.