Background
The COVID-19 pandemic caused a significant surge in data due to the sudden rush for digitalization of services and remote knowledge-sharing across businesses, making it increasingly difficult to find relevant, precise information quickly.
Semantic search systems are an improvement on traditional keyword-based search systems that enable the use of the contextual meaning within a query to find matching documents more intelligently. These systems have been shown to provide better results and user experiences, especially when queries are specified in a natural language format. The key component in building effective semantic search systems is transforming queries and documents from text form into a form that captures semantic meaning. An AI-powered semantic vector search enables users to find answers, content, and products more accurately than traditional text search systems.
Solution
In collaboration with Accenture*, Intel developed this vertical search engine AI reference kit. Paired with Intel® software, this kit may help customers develop a semantic search system. It transforms queries and documents from a text form into a form that captures semantic meaning by using a BERT model to compute distances between user queries and documents to determine how semantically similar two documents are.
End-to-End Flow Using Intel® AI Software Products
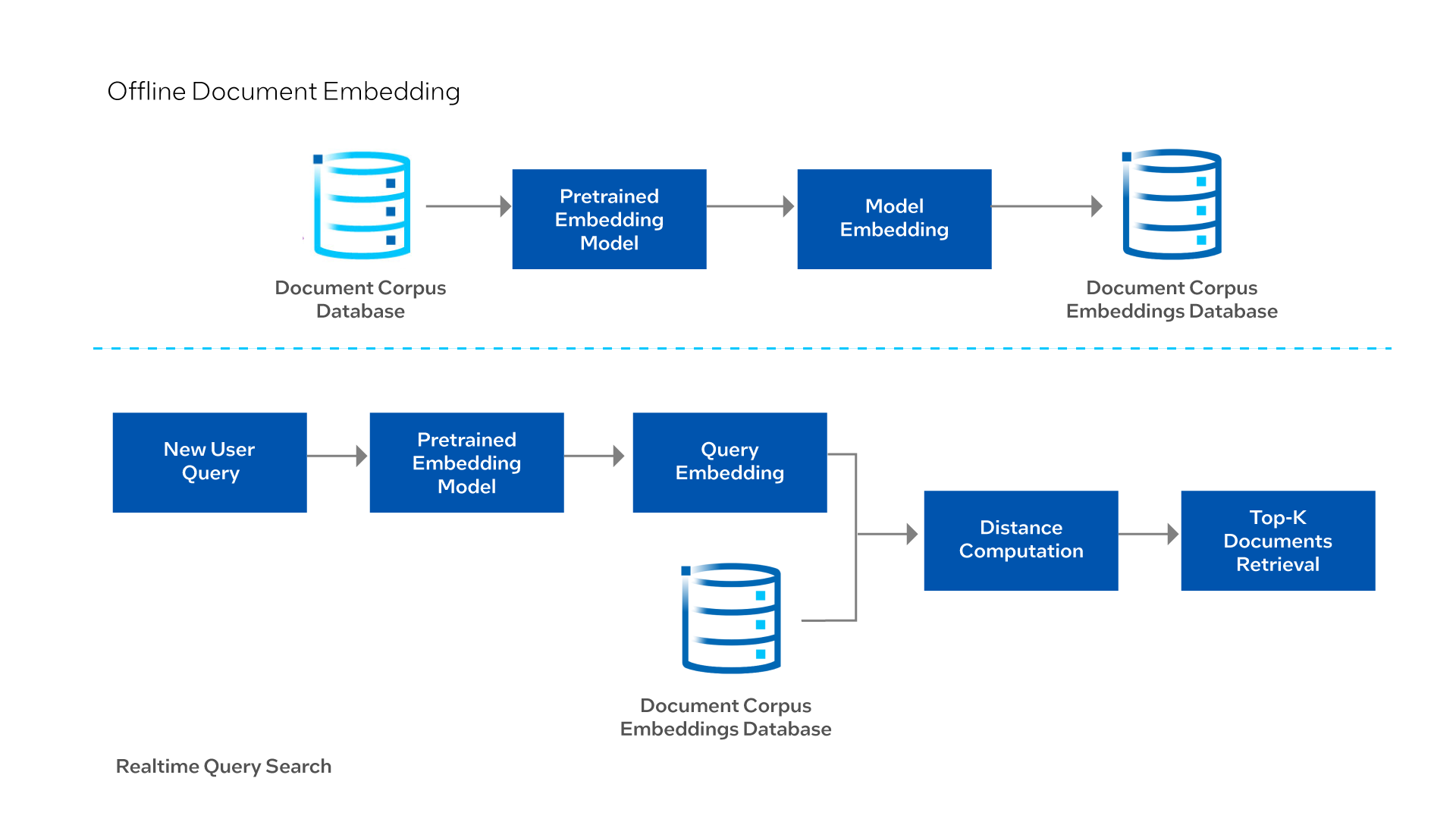
The dataset used for demonstration in this reference implementation is a question-answering dataset called HotpotQA1 constructed of a corpus of short answers and a set of queries built on top of the corpus.
For demonstration purposes, we truncated the document corpus for this dataset from approximately two million entries to 200,000 for embedding, and 5,000 for quantization experiments.
This reference solution starts by using the pretrained large language model to convert or embed every single document in the corpus to a dense vector. The resulting embeddings are stored in a file for use in the real-time semantic search component. For these purposes, and because the document corpus is not massive, these are stored in a file as a NumPy array of dimension n_docs x embedding_dim. In larger production pipelines, these can be stored in a database that allows for vector embeddings.
When a new query arrives in the system, it passes into the same pretrained large language model to create a dense vector embedding of it. After loading the NumPy array of document embeddings from the offline component, this solution computes the cosine similarity score between the query and each document. From this, it returns the K- closest document based on the similarity score.
This reference kit includes:
- Training data
- An open source, trained model
- Libraries
- User guides
- Intel® AI software products
At a Glance
- Industry: Cross-industry
- Task: Document encoding to ingest raw document text and transform it into a high-dimensional dense vector embedding to effectively capture semantic meaning. Real-time semantic search ingests a raw user query and transforms it into a high-dimensional dense vector embedding. Compute distances between user queries and documents to determine how semantically similar two documents are.
- Dataset: HotpotQA1 question-answering dataset constructed of a corpus of short answers and a set of queries built on top of the corpus. Corpus truncated from over two million entries to 200,000 for embedding and 5,000 for quantization experiments.
- Type of Learning: Deep learning
- Models: BERT
- Output:
- For offline document embedding, the output is a dense vector embedding
- For real-time semantic search, the output is the top K-closest document in the corpus
- Intel AI Software Products:
- Intel® Extension for PyTorch* with oneAPI Deep Neural Network Library (oneDNN)
- Intel® Neural Compressor
Technology
Optimized with Intel oneAPI for Better Performance
The vertical search engine model was optimized by the Intel Extension for PyTorch and Intel Neural Compressor for better performance across heterogeneous XPU and FPGA architectures.
Intel Extension for PyTorch and Intel Neural Compressor allow you to reuse your model development code with minimal code changes for training and inferencing.
Performance benchmark tests were run on Microsoft Azure* Standard_D4_v5 using 3rd generation Intel® Xeon® processors to optimize the solution.
Benefits
Improving on traditional keyword-based search systems, semantic search systems enable the use of the contextual meaning within a query to find matching documents more intelligently. An AI-powered semantic vector search enables users to find answers, content, and products more accurately compared to traditional text search systems.
Faster encoding and real-time queries result in less compute time and costs spent to produce search results. Additionally, the increased accuracy in the search results drives increased productivity, better customer experience, and increased user satisfaction.
With Intel® oneAPI toolkits, little to no code change is required to attain the performance boost.
Reference
1. Yang, Zhilin, et al. "HotpotQA: A dataset for diverse, explainable multi-hop question answering." arXiv preprint arXiv:1809.09600 (2018).