Enhance Business Capabilities with RAG and LLMs
Integrating retrieval augmented generation (RAG) with large language models (LLMs) significantly enhances business capabilities. It enhances the capabilities of LLMs by incorporating dynamic, authoritative external knowledge, which allows for more accurate and comprehensive responses. This integration also enables businesses to generate insightful content that is up-to-date and contextually relevant by tapping into vast data sources. In addition, RAG opens new avenues for personalized customer interactions, making engagements more tailored and effective. Now, enterprises can use their data and domain expertise more efficiently, maximizing the use of their knowledge resources.
Advantages and Shortcomings of RAG
While RAG offers many advantages, it also has shortcomings.
One major limitation is that RAG can struggle with the relevance and accuracy of retrieved information, leading to potential misinformation. Additionally, the system may not effectively handle nuanced queries or complex tasks that require deep understanding. Integrating RAG with enterprise applications adds to the complexity, especially when combining structured and unstructured data from various sources. Data indexing and storage also pose significant challenges, as RAG-based databases can expand considerably, leading to issues in storage and indexing.
Address Challenges with Agent-based RAG and OPEA on the Intel® Gaudi® Platform
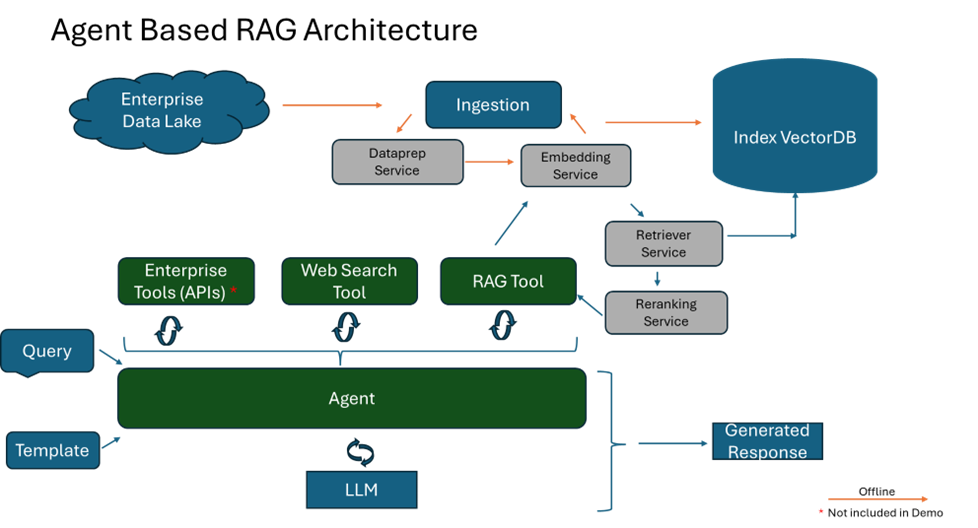
In this post, we show how Intel is making it easier for enterprises to implement agent-based RAG through open source software, Open Platform for Enterprise AI (OPEA) using the Intel® Gaudi® and Intel® Xeon® platforms, addressing each of the issues, and driving business value. OPEA is an ecosystem orchestration framework to integrate performant generative AI (GenAI) technologies and workflows leading to quicker GenAI adoption. Agent-based RAG incorporates intelligent agents that can analyze context more deeply and refine search strategies. These agents can filter and prioritize retrieved data, ensuring higher relevance and accuracy in responses.
We use a React* agent, which synergizes reasoning and acting by retrieving enterprise data and searching the web. Open-source LLMs are served with a text generation interface (TGI) that runs on Intel Gaudi AI accelerators. Intel Gaudi AI accelerators are designed to meet the demands of large-scale AI training and inference. They are cost-effective: Compared to other high-end AI GPUs, Intel Gaudi AI accelerators have a lower total cost of ownership, making them a more economical choice for enterprises. They support large-scale AI workloads, making them suitable for enterprise-level applications.
Integration and Architecture
OPEA provides a close integration of its retriever architecture with options for the LLM's architecture in both hardware and software. We have deployed TGI, which serves the LLM and runs on Intel Gaudi software.
In the agent-based RAG architecture, the RAG tool is responsible for dynamically fetching relevant information from external sources, including embedding and reranking, ensuring that responses generated remain factual and current. The cores of this architecture are vector databases, which are instrumental in enabling efficient and semantic retrieval of information. These databases store data as vectors, allowing RAG to swiftly access the most pertinent documents or data points based on semantic similarity.
Deployment of LLM
docker run -d --runtime=habana --name "comps-tgi-gaudi-service" \
-p <port> -v <model folder>:/data \
-e HF_TOKEN=< your_huggingface_token> \
-e HABANA_VISIBLE_DEVICES=all \
-e PT_HPU_ENABLE_LAZY_COLLECTIVES=true \
-e OMPI_MCA_btl_vader_single_copy_mechanism=none \
--cap-add=sys_nice --ipc=host \
ghcr.io/huggingface/tgi-gaudi:2.0.4 \
--model-id <model name> \
--sharded true --num-shard <#shard> --max-input-tokens 8092 --max-total-tokens 16184
Validation of LLM
curl http://localhost:9009/generate -X POST -d '{"inputs":"What is Deep Learning?","parameters":{"max_new_tokens":32}}' -H 'Content-Type: application/json'
Deployment of RAG Tool
To deploy the RAG tool, we use OPEA code. Ensure the environmental variables are set and then use the DocIndexRetriever.
git clone https://github.com/opea-project/GenAIExamples.git
# Build the Custom Retrieval image
cd GenAIExamples/DocIndexRetriever
docker build --no-cache -t opea/doc-index-retriever:latest --build-arg https_proxy=$https_proxy \
--build-arg http_proxy=$http_proxy -f ./Dockerfile .
cd GenAIExamples/DocIndexRetriever/docker_compose/intel/cpu/xeon
docker compose up -d export RAG_TOOL_ENDPOINT=http://<ip_address>:8889/v1/retrievaltool
The docker compose deploys the following components.
Redis vector database: For this demo, deploy the redis vector database to store the data and the embeddings.
Embedding service: This service converts the data into vector embeddings based on the model deployed.
git clone https://github.com/opea-project/GenAIComps.git
cd GenAIComps
docker run --name opea/embedding-tei:latest
DataPrep service: This service ingests the data into the vector database and also communicates with the embedding service to convert the PDF or other data to vectors.
docker run --name opea/dataprep-on-ray-redis:latest
Retriever service: This service retrieves the data from the vector database based on the query requested by the user. It also communicates with the embedding service to convert user queries to vector embeddings.
docker run --name opea/retriever-redis:latest
Text embeddings inference (TEI) reranking service: This service helps to rank the retrieved data based on the user query.
docker run --name opea/reranking-tei:latest
Validation of RAG tool and its services: OPEA Project GenAI Examples
Validation with the User Interface
We've used Gradio for the user interface (UI), but other frameworks like Streamlit* and React can also achieve similar functionality.
The UI code for this example can be found on GitHub*.
Conclusion
As enterprises continue to navigate the complexities of AI adoption, solutions like OPEA and agent-based RAG with Intel Gaudi AI accelerators provide the necessary tools and infrastructure to overcome challenges and achieve their AI goals. By embracing these technologies, businesses can unlock new levels of efficiency, accuracy, and innovation in their AI-driven initiatives.
Thank you for exploring these advancements with us. Intel showcases many real-world examples and is resolute in furthering innovation in the RAG pipeline. We look forward to seeing how these technologies will continue to evolve and drive the future of enterprise AI.