How much time do you waste searching and summarizing information?
Enterprises want to use AI to enable productivity across their workforce. GenAI that can leverage real-time search is at the top of the list of productivity boosters.
In this tutorial, we'll show you how to deploy SearchQnA, a smart search app that can quickly find and synthesize new information across multiple sources on the web—useful for everything from staying up to date on market research to finding product recommendations. SearchQnA combines the power of large language models (LLMs) with programmatic web search, leveraging AI microservices from the LF & AI Data Foundation’s Open Platform for Enterprise AI project (OPEA) to make it easy to build and deploy.
We're deploying the SearchQnA app on Intel® Tiber™ AI Cloud, but OPEA solutions are designed to be cloud agnostic, and work with a range of compute options should you choose to use an alternative cloud provider.
What is Search QnA?
SearchQnA is a retrieval augmented generation (RAG) system that leverages the synergy between LLMs and Google’s Programmable Search Engine. It helps in the following way:
- New Data Search: Allows your LLM chatbot to use current news or data that is available via web search, even if the model was trained on older data.
- Prioritized Results: A top link prioritization algorithm identifies the top K links for each query, and the system scrapes full-page content in parallel. This prioritization ensures the extraction of the most relevant information.
- Efficient Indexing: The extracted data is indexed in a vector store (Chroma* database) for efficient retrieval.
- Contextual Result Matching: The bot matches your original search queries with relevant documents stored in the vector store, presenting you with accurate and contextually appropriate results.
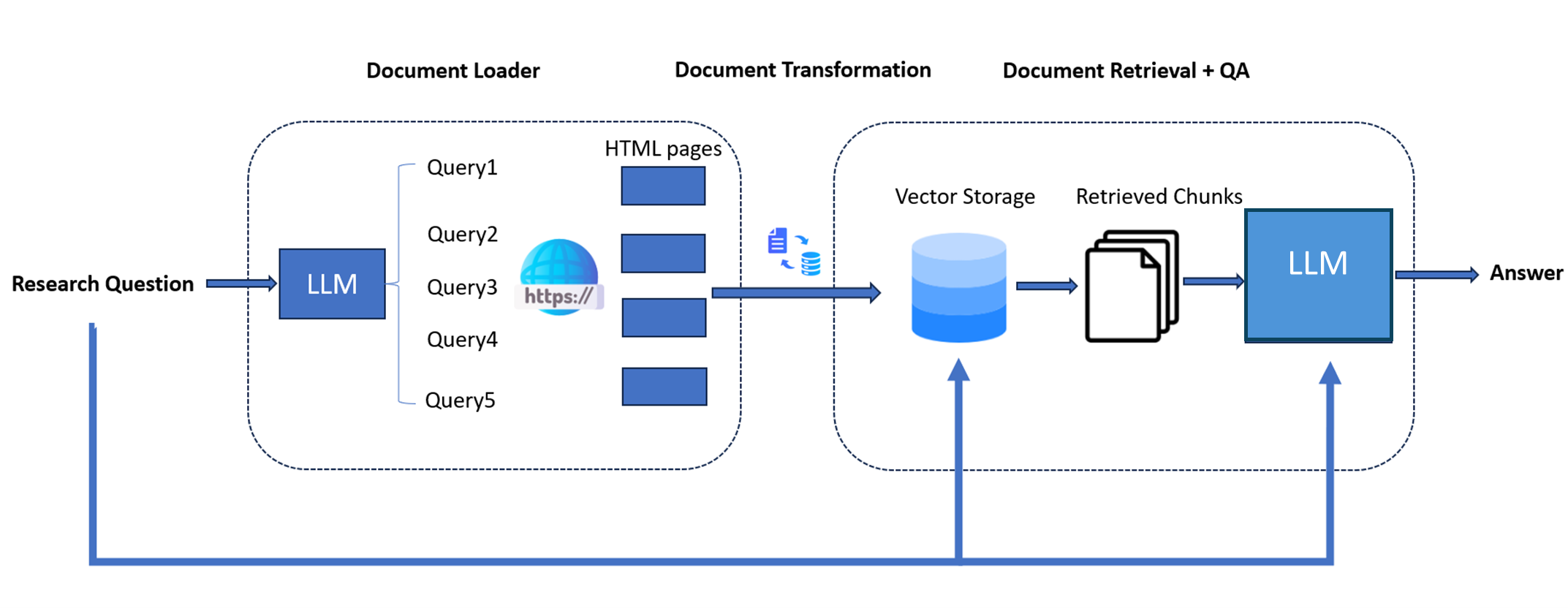
Workflow showing a large language model enabled with web search capability.
Some potential applications for SearchQnA include:
- Enhanced Customer Support: Your chatbots can answer complex customer questions by combining general LLM knowledge with current web search information.
- Market Research and Competitive Analysis: Quickly gather information on competitors, market trends, and customer sentiment.
- Content Creation: Generate ideas and gather information for blog posts, articles, and marketing materials.
- Internal Knowledge Base: Create an internal Q&A system for employees, integrating company-specific information with web search.
- Up-to-Date Information Retrieval: Get up-to-date answers to questions requiring current information, like news or stock prices.
How SearchQnA Works
Below is a diagram of the SearchQnA architecture implemented with a docker compose file. All the components you see are provided in OPEA GenAIComps. OPEA does have Kubernetes examples, but we’ll use the docker compose approach in this article.
When the user browses to the web page, the OPEA Nginx* component (searchqna-xeon-nginx-server) will proxy-pass the request to display the UI from the searchqna-xeon-ui-server, a ready-made Svelte* front-end.

Containers diagram of the deployed SearchQnA application. The megaservice chains together multiple services. The orange boxes are Hugging Face services that are “wrapped” and orchestrated as OPEA components.

The SearchQnA chat UI. The app gathers context from search and feeds it into the large language model to formulate its answer.
When the user then submits a query in the UI, the request is made to the route /v1/searchqna. The Nginx server intercepts the request, and proxy passes it to the searchqna-xeon-backend-server. This backend is where all the query processing takes place and will use multiple AI models, and the Google Programmable Search Engine.
To process the request, the searchqna-xeon-backend-server orchestrates the sequence of calls defined in a “megaservice,” via a directed-acyclic-graph (DAG). The megaservice processes the query (embedding-server), retrieves relevant web results (web-retriever-server), reprioritizes the results (reranking-tei-xeon-server), and then finally invokes the LLM (llm-textgen-server) to generate a response back to the user in their browser.
Deploying SearchQnA on the Cloud
OPEA offers a large selection of AI microservice components that can be deployed on any cloud. The framework supports a range of compute options including CPU, GPU, or dedicated AI accelerators. In this example, we’ll use the Intel® Tiber™ AI Cloud with an instance powered by Intel® Xeon® CPUs.
Accounts and API Keys
The first step to deploying the solution is to obtain the necessary accounts and API keys below:
1. Open a Hugging Face* account. After you’ve opened your Hugging Face account, obtain an access token for it:
It’s best practice to use a secrets manager, e.g., Infisical, HashiCorp, GCP, AWS, Azure, and not store your tokens as plain text.
2. Create a Google Programmable Search Engine. Create a new Google Programmable Search Engine as shown below and take note of your search engine ID, preferably in a secrets manager. You’ll use this ID later in environment variables to configure your application.
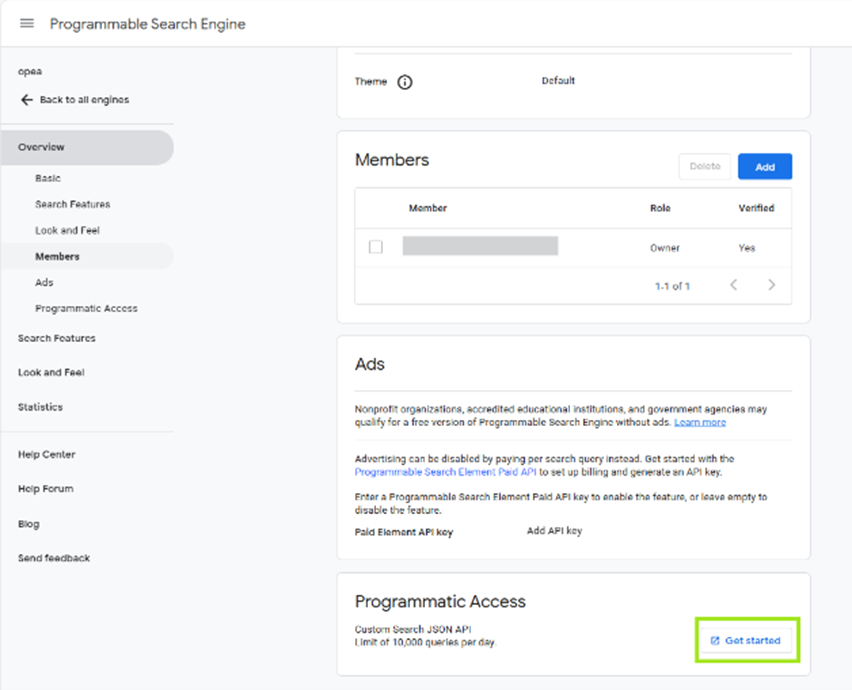
3. Obtain the Programmable Search Engine API key. Once you’ve created your new search engine, scroll to the bottom of the Overview page to the “Programmatic Access” section. Click “Get Started,” then “Get a Key.” Take note of the key as before; you’ll need it later.
4. Obtain a cloud virtual machine instance with Intel® Xeon® processor, with 64 GB disk space, and 64 GB RAM. We’ll use the Intel® Tiber™ AI Cloud Large instance. You may sign up for an account, and choose the instance as follows in the screenshot below:
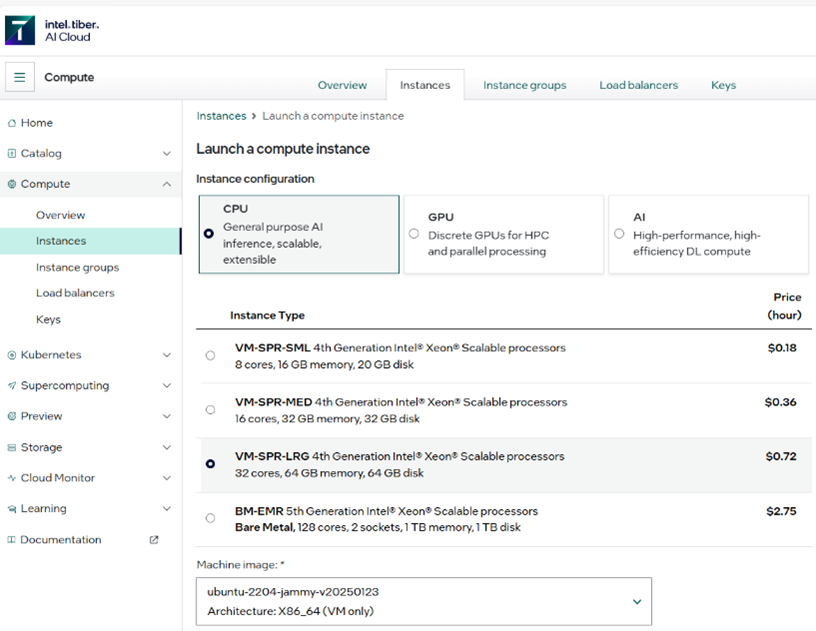
5. Generate and upload your SSH key before spinning up this machine. Go to SSH Keys — Intel® Tiber™ AI Cloud Docs for help generating your SSH key if necessary.
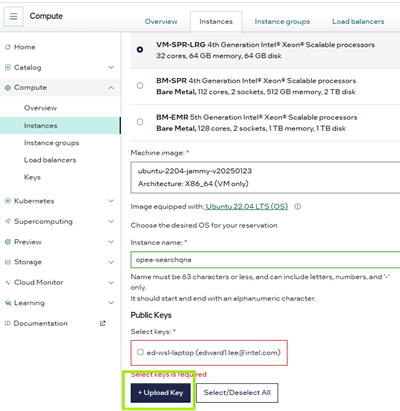
6. SSH into your machine and configure SearchQnA. To SSH into your new instance, you’ll see instructions when you view your instance on Intel® Tiber™ AI Cloud as shown in the figure below. Follow the instructions in your terminal.
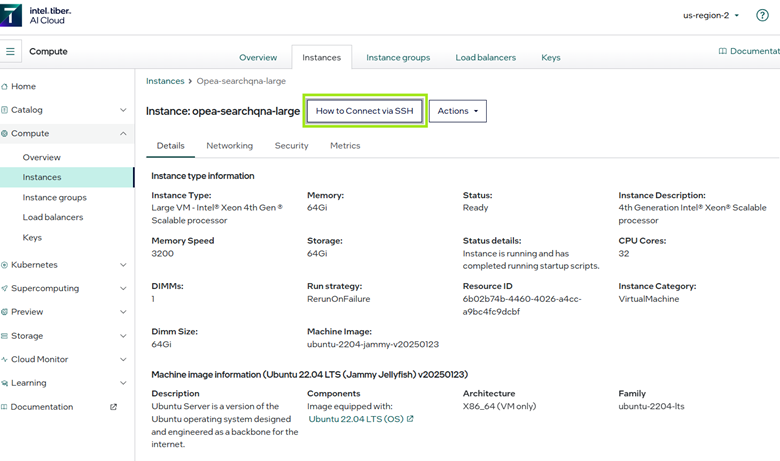
7. Once you’ve SSH’d successfully into the machine, clone down the OPEA Examples repo.
git clone https://github.com/opea-project/GenAIExamples.git
8. Install Docker Community Edition.
source GenAIExamples/ChatQnA/docker_compose/install_docker.sh
9. Set the following environment variables in your terminal.
export TAG=1.2
export host_ip=$(hostname -I | awk '{print $1}')
export no_proxy=""
# Create a Google Programmable / Custom Search Engine: https://programmablesearchengine.google.com/controlpanel/create
export GOOGLE_CSE_ID="my google programmable search key"
# Obtain key: https://developers.google.com/custom-search/v1/introduction
export GOOGLE_API_KEY="my google API key"
export HUGGINGFACEHUB_API_TOKEN="my hugging face token"
export LLM_MODEL_ID="Intel/neural-chat-7b-v3-3"
export LOGFLAG=True
And:
cd GenAIExamples/SearchQnA/docker_compose
source set_env.sh
Note that it's best practice to not store secrets in plain text—use one of the secrets managers noted earlier in this article.
10. Build images and run the containers.
Build the opea/searchqna-ui image first:
cd GenAIExamples/SearchQnA/ui
docker build --no-cache -t opea/searchqna-ui:1.2 --build-arg https_proxy=$https_proxy --build-arg http_proxy=$http_proxy -f docker/Dockerfile .
Next, you’ll want to build and run the rest of the images. The environment variable TAG=1.2 specified earlier corresponds to the last set of stable images at the time of writing this article.
To pull the Docker images and run the containers:
cd GenAIExamples/SearchQnA/docker_compose/intel/cpu/xeon
docker compose up -d
This isn’t required, but should you ever need to build the Docker images from the latest source, you may refer to GenAIExamples/SearchQnA/docker_build/build.yaml, and GenAIComps.
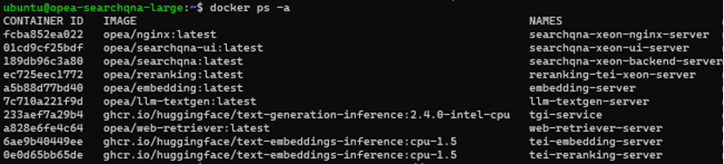
Once the images are built and containers are up, list the running containers as follows:
docker ps -a
You will see something like below (I’ve truncated columns for readability).
To observe services in greater detail, inspect the containers’ logs. For example, to view the logs of web-retriever-server, use this command:
docker logs web-retriever-server
The above can help verify that the Google Programmatic Search Engine is accessible.
In the next section, we’ll show you how to test the individual services to get a better sense of what each service does, and what to expect from the output.
Test the Services
The following commands will allow you to observe example requests and output of each microservice, which is useful for debugging.
# tei
curl http://${host_ip}:3001/embed -X POST -d '{"inputs":"What is Deep Learning?"}' -H 'Content-Type: application/json'
# embedding microservice (OPEA wrap of tei)
curl http://${host_ip}:3002/v1/embeddings -X POST -d '{"text":"hello"}' -H 'Content-Type: application/json'
# web retriever microservice
export your_embedding=$(python3 -c "import random; embedding = [random.uniform(-1, 1) for _ in range(768)]; print(embedding)")
curl http://${host_ip}:3003/v1/web_retrieval -X POST -d "{\"text\":\"What is the 2024 holiday schedule?\",\"embedding\":${your_embedding}}" -H 'Content-Type: application/json'
# tei reranking service
curl http://${host_ip}:3004/rerank -X POST -d '{"query":"What is Deep Learning?", "texts": ["Deep Learning is not...", "Deep learning is..."]}' -H 'Content-Type: application/json'
# reranking microservice
curl http://${host_ip}:3005/v1/reranking -X POST -d '{"initial_query":"What is Deep Learning?", "retrieved_docs": [{"text":"Deep Learning is not..."}, {"text":"Deep learning is..."}]}' -H 'Content-Type: application/json'
# tgi service
curl http://${host_ip}:3006/generate -X POST -d '{"inputs":"What is Deep Learning?","parameters":{"max_new_tokens":100, "do_sample": true}}' -H 'Content-Type: application/json'
# llm microservice
curl http://${host_ip}:3007/v1/chat/completions -X POST -d '{"query":"What is Deep Learning?","max_tokens":100,"top_k":10,"top_p":0.95,"typical_p":0.95,"temperature":0.01,"repetition_penalty":1.03,"stream":false}' -H 'Content-Type: application/json'
You may have noticed that within the megaservice, components are essentially “wrapping” other open source services.
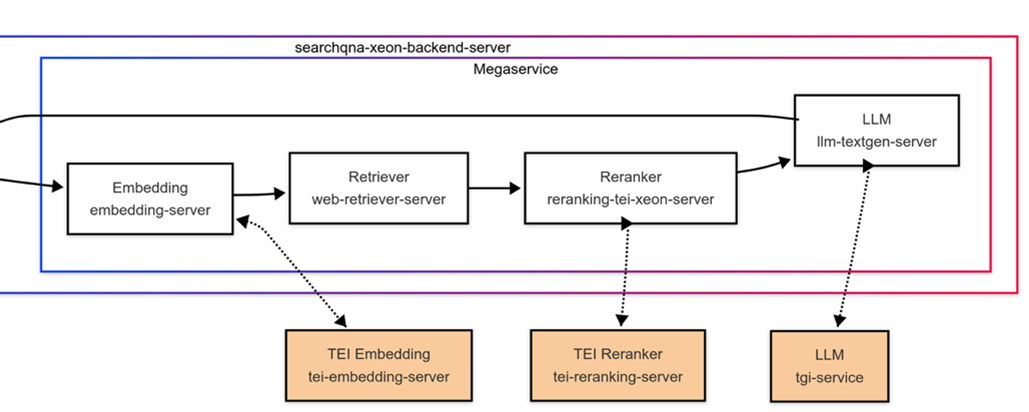
For example, the:
- embedding-server is calling a Hugging Face text embeddings-inference (TEI) server tei-embedding-server (in orange) and turns the user input into a query embedding vector (see component here).
- web-retriever-server is a server that calls the Google Programmable Search Engine and uses LangChain to vectorize and index outputs to a vector database Chroma Db (see the web retriever component).
- reranking-tei-xeon-server calls tei-reranking-server, a Hugging Face server that serves a reranking model (see the reranking component).
- llm-textgen-server calls a Hugging Face text generation service tgi-service to serve the LLM model that you defined in the LLM model that you defined in the LLM_MODEL_ID environment variables set in step 9 in the terminal earlier (find more information here: text generation component).
These components are interchangeable. For example, llm-textgen-server also can be based on vLLM or Ollama or another model inference server that suits your needs. OPEA provides a selection of popular inference servers. The “wrapping” pattern provides a few benefits:
- Abstraction of the underlying service: Allows easy interchangeability / upgradability of popular AI microservices that otherwise would be fragmented, requiring developers to build the connectivity.
- Orchestration: Standardizing component inputs and outputs allows the megaservice to orchestrate the call graph of components for data to pass through.
- Monitoring and telemetry: OPEA Comps provides monitoring/telemetry with Prometheus, Grafana, and Jaeger (see telemetry).
- Consistent configuration management: When substituting OPEA components, they would have similar configuration with similar set of environment variables.
The Python code that creates the megaservice can be found in the searchqna.py, which is containerized in the searchqna-xeon-backend-server.
If you'd like to wrap your own OPEA components to orchestrate with other OPEA services, you can see what others have contributed here.
Expose the UI
A quick way to expose your UI is by using a Cloudflare tunnel UI. The TryCloudflare tool lets you quickly expose local services to the internet with no Cloudflare account required:
sudo apt update
sudo apt install -y wget
wget https://github.com/cloudflare/cloudflared/releases/latest/download/cloudflared-linux-amd64.deb
sudo dpkg -i cloudflared-linux-amd64.deb
cloudflared tunnel --url http://localhost:80
After running the command, you’ll see a public URL like the one below that you can open in your browser:
https://<random-subdomain>.trycloudflare.com
For more information on this technique, check out Expose Local Apps with Tunnels — Intel® Tiber™ AI Cloud Docs
Spinning Down
To wrap things up, in the same path as the compose.yaml type:
docker compose down
This will stop and remove all your running containers in the compose.yaml. To see that the containers are removed:
docker ps –a
Try It Out
The SearchQnA RAG AI system provides a powerful and flexible way to leverage AI-powered search and create tools that boost productivity across the business. By combining the strengths of LLMs and programmatic web search, SearchQnA enables you to access up-to-date information from the web and gain valuable insights with an LLM chat interface.
In this tutorial, we demonstrated how to build a full-stack, open source, AI app with the Open Platform for Enterprise AI (OPEA) on a Xeon instance on the Intel Tiber AI Cloud, but you can deploy this solution on any cloud with a range of hardware.
OPEA’s framework makes it possible for enterprise developers to quickly build and deploy GenAI, RAG-based applications using standardized, interoperable components that reduce your time to market and cut down on solution maintenance. To learn more about OPEA and how to build other practical GenAI applications, check out these resources:
OPEA (Open Platform for Enterprise AI) Introduction | AI with Guy
About the Author
Ed Lee, Sr. AI Software Solutions Engineer, Intel
Ed Lee works with startups as part of the Intel® Liftoff® program. The program accelerates AI startups to build innovative products with open ecosystems. At Intel, he works with several open ecosystems such as OPEA, OpenVino, vLLM, and on a range of hardware and cloud services. His background spans finance, tech, and healthcare, and has delivered solutions including LLMs, graphs, reinforcement learning, and cloud services. Ed is a co-inventor on patents about AI for chronic kidney disease, and modular data pipelines. He holds a master's degree in financial engineering from UC Berkeley.