Problems
In pursuit of speed, big data processing never stops. On one hand, memory provides a speed at least one order of magnitude faster than disk does; on the other hand, higher volume memory is available at lower prices, making it feasible to store data in memory. Along with this trend, a quantity of memory-centric computational frameworks emerged, such as Spark. However the existing memory-centric computational frameworks still face some challenges.
- Data sharing: A cluster may be running multiple computational frameworks and a number of applications. For example, a cluster may be running Spark and Hadoop at the same time, and the current way of sharing data between the two frameworks is using HDFS. That is to say, when MapReduce needs to use Spark’s outputs as its inputs, the intermediate results have to be written into and read from HDFS. Because HDFS read/write are "heavy" operations which require disk read/write, and moreover, backup policies also bring in network overhead, sharing data using HDFS is a solution of low efficiency.
- Volatile on-heap cache: In computation frameworks like Spark, the memory management module and the computing engine are running in the same JVM, and all caching data are stored in the JVM heap space, so if the computing engine throws runtime exceptions which makes JVM exit, all data cached in JVM heap space will be lost.
- GC overhead: Since most of the existing big data computing frameworks are running on JVM, GC overhead is unavoidable. For memory-centric computational frameworks like Spark, the GC issue is more serious, because intermediate data is cached in JVM heap space. During data processing, the size of cached data becomes larger and larger, and GC cannot clean them up, which makes the on-heap data size too huge for GC, and therefore a sharp increase in GC overhead.
Solutions
Tachyon solves those problems. It is a memory-centric distributed storage system, which stores data off-heap. It plays the role of the independent memory management module in big data processing software stack. Below it is the persistent storage layer which supports a variety of distributed storage systems, such as HDFS and S3; on top of it sits the computing layer which supports different computation frameworks, like Spark and MapReduce. It is used to manage and accelerate the access of storage layer from computation layer.

How does Tachyon solve the three questions mentioned above?
For the first question - Data sharing: Different applications and computation frameworks can share the intermediate data through Tachyon. For example, if the output of a Spark job is the input data of a MapReduce job, the intermediate results generated by the Spark job can be written into Tachyon, for the MapReduce job to read. Because Tachyon stores data in memory, which is efficient for data sharing, and the whole work-flow does not access HDFS, and thus greatly reduces overhead.
For the second question – Volatile on-heap cache: Because Tachyon stores all data in the off-heap space, application crashes don’t impact data managed by Tachyon, in which way in memory data won’t be lost versus to the original on-heap data.
For the third question - GC overhead: Obviously, because all data is stored in the off-heap space in Tachyon, GC does not manage this part of data, and no GC overhead is involved.
Case Studies
Tachyon has its own Tachyon file API, through which users can interact with Tachyon as a file system. In addition Tachyon also implements the FileSystem interface of HCFS (FileSystem Compatibility with Apache Hadoop), so that all HCFS-compatible applications and computing frameworks can be easily integrated with Tachyon.
Currently, Tachyon can be seamlessly integrated with Hadoop and Spark. With very simple configuration, users can use Tachyon to store and share data used by Hadoop and Spark, thereby improving application performance and the user experience.
Here we use three use cases to show the real-world application of Tachyon and how it improves applications’ performance.
Use Case 1
In the first use case, we use Tachyon to share data across different applications at high speed.
The figure below depicts the real time data processing paradigm for some real-world use case.
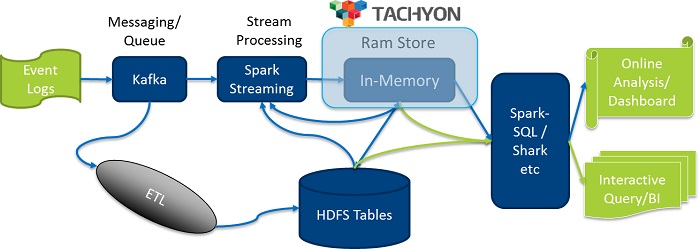
The upper half of the picture shows online data processing flow, and it is divided into two parts by Tachyon, which are front-end processing and back-end data analytics. In front-end processing, the streaming data is first stored in Kafka. As a distributed message queue, Kafka can efficiently cache and distribute incoming data, and a SparkStreaming job periodically read data from Kafka, perform data processing and then write the processed intermediate results into Tachyon. In the back-end analytics, end users can query and analyze the intermediate results from Tachyon with Shark, Spark-SQL etc.
Without Tachyon, it either takes an embedded service in the same process to complete the entire process flow, or requires writing the intermediate results into HDFS for data sharing. Both of those methods have limitations, because the former one will increase the complexity of the application, and the services are so coupled, while the latter is inefficient. After Tachyon is introduced, the entire process flow is divided into front-end processing and back-end analytics, which simplifies the front-end program’s logic, because the front-end program only needs to handle simple data processing, thereby improving the robustness of the application and response speed, and the back-end is given better support for different applications and even computing frameworks, thereby greatly enhancing the application’s scalability. Since Tachyon stores data in memory, data are written and read at a very high speed. This greatly improves the response speed of the application, and thus can support applications sensitive to response delay, such as online analytics and interactive query, at the back-end.
The lower half of the figure shows processing and query for historical data. Data in Kafka can be processed by the ETL program, and then stored in HDFS as historical data. Applications can query over both the historical data in HDFS and online data in Tachyon, and get richer analytics results.
Use Case 2
The second case uses Tachyon to perform OffHeap data storage.
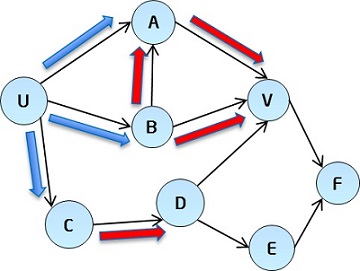
It is a graph computing use case, in which the input data is a directed graph, and the algorithm is used to compute the N-degree association of each vertex. N-degree association is the association between two vertices that are N distance (N-hop) away. For example, in the figure above, the blue arrows point to vertices in 1-degree associations with the vertex U, and the red arrows point to vertices in 2-degree associations with U. The algorithm is as follows:
- Weightn(u, v) = ∑k=1...MWp (U,V)k (M is the number of paths that are of N distance from U to V)
- Wp(U,V)k = ∏e=1...nWe (We is the weight of the number e edge in one path)
Equation 1 shows that if there are M paths of N length paths starting from vertex U to vertex V, and Wp(U, V) represents the weight of the Kth path, then the N-degree association between U and V is the sum of the M paths’ weights. Equation 2 shows that the weight of an N-distance path equals to the product of all edges’ weights on this path. In input data, each edge’s weight is a floating-point number between 0 and 1, the product will also be a floating-point number between 0 and 1, and the degree of association decreases when N increases. The algorithm can be used in social network to compute users’ correlation for recommending friends, or in e-commerce websites to compute products’ correlation for recommending products.
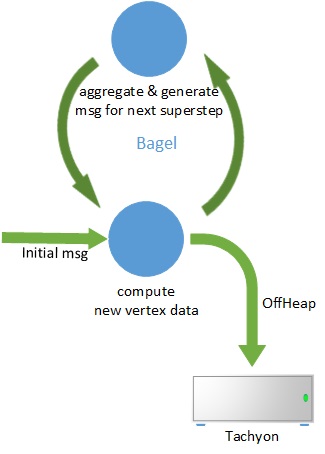
We use Spark’s graph computing framework Bagel to solve this problem. Bagel is an implementation of the Pregel model on Spark. In Bagel, jobs run as a sequence of iterations, which are called Super Steps. In each Super Step, each vertex in the graph runs a user-defined function that takes the current vertex state and a list of messages sent to current vertex from previous Super Step as input, updates the state of current vertex, and generate a list of outgoing messages to vertices associated with current vertex, sends messages to other vertices for use in the next iteration, and determines whether the current vertex remains active or not. While each node receives messages sent to it during the previous Super Step, for the first Super Step, nodes take the application’s initial messages as inputs. The compute function runs for several iterations, until all nodes are no more active, or the number of iterations reaches a predefined upper limit.
During each Super Step, Bagel caches the new vertex state and outgoing messages for the next iteration which are generated by UDF in RDD. When the number of iterations and the amount of intermediate data increase, GC overhead becomes larger and larger. We eliminate GC overhead by storing intermediate results of each iteration in Tachyon. By specifying the RDD URI’s scheme as Tachyon, Spark will automatically store the data into Tachyon.
Because Tachyon stores all data in Off-Heap memory space and GC does not manage this part of data, so the GC overhead on cached data is completely eliminated, and it brings a performance increase close to 30% in huge data amount scenarios in this case.
More importantly, as the JVM heap memory increases, GC overhead grows exponentially rather than linearly with it, when the heap reaches a certain volume, GC overhead becomes unbearably heavy, and Tachyon must be used to successfully run the program.
Use Case 3
In the third use case, we use Tachyon to locally store remote data.
Multiple clusters may be deployed in user’s production environment, and different clusters perform different tasks. The scenario of this case is that one of the clusters is dedicated to act as storage service, which is very similar to Amazon's S3 service, it stores various data of different users. A number of computing clusters, which are similar to Amazon's EC2 service, Spark and MapReduce jobs are running on them.
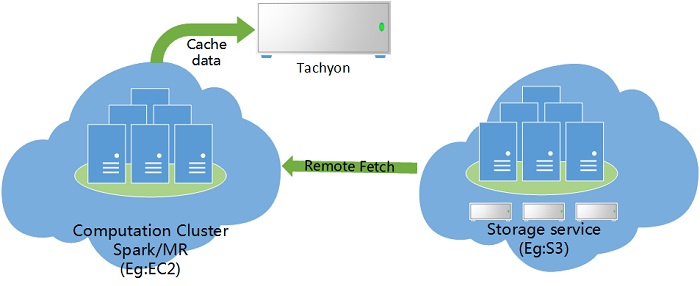
As shown by the figure above, since the data and computation are handled by different clusters, when an application needs to repeatedly access data on the remote data storage cluster, or multiple applications need to access the same data on the remote data storage cluster, the remote data needs to be repeatedly transferred to computation nodes through network, which introduces heavy network overhead.
Tachyon well solves this problem: The application needs to read only once from a remote cluster that provides data storage service, store the remote data locally in Tachyon, and then access data in local memory or external storage space. This can effectively reduce the overhead caused by remote data access.
There are two ways of using Tachyon as storage for a local working set: The first approach is having a dedicated service to automatically move data from remote data storage cluster to local Tachyon space, another approach is considering remote data storage cluster as local Tachyon cluster’s under file system, and Tachyon offers loadufs service to load data from under file system.
Summary
Through the above three use cases, we can conclude several scenarios that Tachyon is applicable to:
The first scenario: The application’s outputs need to be shared across different applications and computing frameworks. The first use case is an example of this scenario, in which the intermediate results may be used by different back-end applications.
The second scenario: Application has large account of in-memory data, and requires long-running and iterative computing capacity. The second use case is an example of this scenario, which utilized Tachyon to greatly reduce application’s memory consumption and GC overhead, and as a result enhanced the robustness and performance of the application.
The third scenario: Repeated access to a large amount of remote data is required. The third use case is an example of such a scenario, where Tachyon plays the role of local storage manager integrated with remote storage, so that applications can directly read local data in subsequent operations, and thereby reduce the overhead of remote data access.
The fourth scenario: The application requires fast response, and sensitive to latency. Take the first use case for example, when the back-end users need to do online analytics or interactive query, because Tachyon stores data in memory, response time is shortened and latency is reduced.
Tachyon has its own limitation. Because all data in Tachyon are stored as raw files, which brings serialization and de-serialization overhead during data write/read in Tachyon, and thus increases the CPU load, in some compute-intensive applications, Tachyon brings limited improvement to performance.
Tachyon is a fast growing project. Currently, we have three Tachyon contributors in our team, more than 500 commits are merged into Tachyon’s upstream, including bug fixes, usability and stability improvement and some key features. For example, tiered storage is a solution for memory shortage. It takes advantage of SSD and other high-speed storage devices, to expand the total space managed by Tachyon and further enhance Tachyon’s user experience.
The Tachyon Project
References
- A Reliable Memory Centric Distributed Storage System – Haoyuan Li @AMPCamp 5th Nov 21st 2014
- Real-time Analytical Processing (RTAP) Using Spark and Shark – Jason Dai @AMPLab Retreat Summer 2013