Intel® has a long-term collaboration with Apache* MXNet* (incubating) community to accelerate neural network operators in CPU backend. Since MXNet v1.2.0, Intel and MXNet community announces MXNet is optimized with Intel® Math Kernel Library for Deep Neural Networks (Intel® MKL-DNN) formally. Since the v1.7.0 version, MKL-DNN is the default CPU backend in MXNet’s binary distributions. End users can take advantage of Intel hardware advances including latest 3rd gen of Intel® Xeon® Scalable processors (codename Ice Lake) and Intel® Deep Learning Boost (Intel® DL Boost) technology directly.
Note: With the version 1.1 of Intel® MKL-DNN, name was changed to Deep Neural Network Library (DNNL). With the start of oneAPI project next name change occurred – it was changed to be consistent with the rest of oneAPI libraries and currently is called oneAPI Deep Neural Network Library (oneDNN).
Installation
Developers can easily install MXNet using it's Installation Guide.
The following screenshot shows the current version and preview versions. Developers can also choose to install the binary from Anaconda*, PIP or build from source for CPU. MXNet supports wide range of different programming languages, including most popular ones: Python*, Java and C++.

oneAPI Deep Neural Network Library (oneDNN) is designed to accelerate the neural network computation. It is optimized for Intel processors utilizing available ISA and extensions like Intel® AVX-512 VNNI and will deliver the maximum performance of deep learning application on CPU.
Users can install newest MXNet release in the Python* environment on Intel® CPU using the command below:
> pip install mxnet
If user wants to try the new features in advance (not officially released yet), he can install a nightly build from master by the command:
> pip install mxnet --pre
For other options including PIP, Docker and Build from source, please check Ubuntu* installation guide, CentOS installation guide, other MXNet PIP packages, and please validate your MXNet installation.
To check if MXNet was installed successfully with oneDNN, run following command in Python* terminal:
Python 3.6.2 |Continuum Analytics, Inc.| (default, Jul 20 2017, 13:51:32)
[GCC 4.4.7 20120313 (Red Hat 4.4.7-1)] on linux
Type "help", "copyright", "credits" or "license" for more information.
>>> import mxnet as mx
>>> mx.runtime.Features().is_enabled('MKLDNN')
True
Getting Started
A better training and inference performance is expected to be achieved on Intel® CPUs with MXNet built with Intel® oneDNN. Once user has installed MXNet package, he can start a simple MXNet Python* code with a single convolution layer and verify if oneDNN backend works.
import mxnet as mx
num_filter = 32
kernel = (3, 3)
pad = (1, 1)
shape = (32, 32, 256, 256)
x = mx.sym.Variable('x')
w = mx.sym.Variable('w')
y = mx.sym.Convolution(data=x, weight=w, num_filter=num_filter, kernel=kernel, no_bias=True, pad=pad)
exe = y.simple_bind(mx.cpu(), x=shape)
exe.arg_arrays[0][:] = mx.nd..random.normal(shape=exe.arg_arrays[0].shape)
exe.arg_arrays[1][:] = mx.nd.random.normal(shape=exe.arg_arrays[1].shape)
exe.forward(is_train=False)
o = exe.outputs[0]
To get more details about what is happening under the hood to debug and profile network setting, the environment variable MKLDNN_VERBOSE is needed:
export MKLDNN_VERBOSE=1 # use 2 to get even more information
#or
export DNNL_VERBOSE=1
For example, by running the code snippet above, the following debugging logs are printed and it provides more insights on Intel® oneDNN convolution and reorder primitives. That includes: memory layout, inferred shape and the time cost of primitive execution.
dnnl_verbose,info,oneDNN v1.7.0 (commit 2e4732679f0211bb311780d0f383cf2dce9baca7)
dnnl_verbose,info,cpu,runtime:OpenMP
dnnl_verbose,info,cpu,isa:Intel AVX-512 with AVX512BW, AVX512VL, and AVX512DQ extensions
dnnl_verbose,info,gpu,runtime:none
dnnl_verbose,exec,cpu,reorder,jit:blk,undef,src_f32::blocked:abcd:f0 dst_f32::blocked:aBcd16b:f0,,,32x32x256x256,20.0149
dnnl_verbose,exec,cpu,reorder,jit:uni,undef,src_f32::blocked:abcd:f0 dst_f32::blocked:ABcd16b16a:f0,,,32x32x3x3,0.0200195
dnnl_verbose,exec,cpu,convolution,jit:avx512_common,forward_inference,src_f32::blocked:aBcd16b:f0 wei_f32::blocked:ABcd16b16a:f0 bia_undef::undef::f0 dst_f32::blocked:aBcd16b:f0,,alg:convolution_direct,mb32_ic32oc32_ih256oh256kh3sh1dh0ph1_iw256ow256kw3sw1dw0pw1,43.668
dnnl_verbose,exec,cpu,reorder,jit:uni,undef,src_f32::blocked:abcd:f0 dst_f32::blocked:ABcd16b16a:f0,,,32x32x3x3,0.11499
dnnl_verbose,exec,cpu,reorder,jit:blk,undef,src_f32::blocked:aBcd16b:f0 dst_f32::blocked:abcd:f0,,,32x32x256x256,17.9299 out:f32_OIhw16i16o,num:1,32x32x3x3,0.0510254 mkldnn_verbose,exec,reorder,jit:uni,undef,in:f32_nChw16c out:f32_nchw,num:1,32x32x256x256,20.4819
MXNet provide bunch of samples to help users to do CNN for Image Classification, Text Classification, Semantic Segmentation, R-CNN, SSD, RNN, Recommender Systems, Reinforcement Learning etc. Please visit the GitHub* Examples.
Please also check this website for excellent MXNet tutorials.y
oneDNN supported Graph Optimization
Graph optimizations have huge impact on neural network performance. Utilizing MXNet subgraph API, oneDNN can be used also to optimize popular patterns which results in less memory operations and decreasing framework overhead – this leads to overall improved performance without losing accuracy. Currently, these optimizations are enabled by default and can be recognized by following information in logs:
[10:27:59] ../src/executor/graph_executor.cc:1995: Subgraph backend MKLDNN is activated.
It can be disabled by setting env variable:
export MXNET_SUBGRAPH_BACKEND=NONE # default is MKLDNN
To optimize network even more, users can quantize network to utilize INT8 computations – see more Model Quantization for Production-Level Neural Network Inference.
Run Performance Benchmark
Users can benchmark the performance with Intel® Optimized MXNet by running following script from MXNet repository:
python example/image-classification/benchmark_score.py
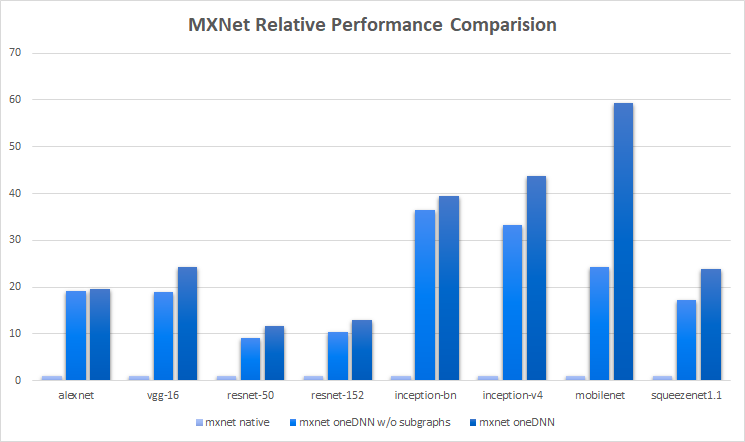
Below are the results collected on Intel(R) Xeon(TM) Platinum 8280L @ 2.70GHz with version mxnet-native v1.8.0 and mxnet v1.8.0 (with and without subgraphs optimizations) [1] :
Performance Analysis and Profiling
If you think that network performance is not satisfactory even with oneDNN enabled, you probably want to track down and fix the slowness. There are numerous ways to do it with different tools – below are described the easiest and most common in MXNet environment. First, use export MKLDNN_VERBOSE=1 to make sure that Intel® oneDNN is running correctly. In the verbose logs you can check execution time of the individual primitives.
Besides, MXNet has a built-in profiler that gives detailed information about the execution time at the symbol level. The profiler can then be turned on with an environment variable for an entire program run, or programmatically for just part of a run.
mx.profiler.set_config(profile_symbolic=True,
aggregate_stats=True,
continuous_dump=True,
filename='profile_output.json')
mx.profiler.set_state('run')
exe.forward(is_train=False)
o = exe.outputs[0]
mx.nd.waitall()
mx.profiler.set_state('stop')
print(mx.profiler.dumps())
Output from above code snippet with MXNET_EXEC_BULK_EXEC_INFERENCE=0 should look like this:

After the execution finishes, you can load profile_output.json to your browser’s tracing (Example - chrome://tracing in a Chrome* browser) to inspect the results in more granulated way.

Note: The output file can grow extremely large, so this approach is not recommended for general use. Depending on model size profiling only few iterations is recommended.
See example/profiler for complete examples of how to use the profiler in code.
References
- MXNet Documentation
- MXNet GitHub
- Build/Install MXNet with Intel® MKL-DNN
- Apache MXNet v1.2.0 optimized with Intel® Math Kernel Library for Deep Neural Networks (Intel MKL-DNN)
- Amazing Inference Performance with Intel® Xeon® Scalable Processors
- Model Quantization for Pruduction-level Neural Network inference
- oneDNN documentation
[1] Benchmarks run with following command:
mxnet- native and with oneDNN: KMP_AFFINITY=granularity=fine,noduplicates,compact,1,0 OMP_NUM_THREADS=56 python example/image_classification/benchmark_score.py
With subgraphs disabled:
MXNET_SUBGRAPH_BACKEND=NONE KMP_AFFINITY=granularity=fine,noduplicates,compact,1,0 OMP_NUM_THREADS=56 python example/image_classification/benchmark_score.py