Overview
For developers in the PyTorch ecosystem, the frontier is increasingly shifting toward edge deployment. As models become more sophisticated, the challenge of deploying them efficiently across devices—from entry-level hardware to powerful AI PCs—has become paramount. Within the PyTorch ecosystem, ExecuTorch provides this foundation as a portable, high-performance runtime for on-device inference. (Learn more about ExecuTorch 1.0)
This raises an important question: how do we bridge the gap between a standard, exported PyTorch model and the diverse, heterogeneous hardware inside modern devices? This question is more critical than ever with the latest generation of AI PCs, powered by architectures like Intel® Core™ Ultra Processors (Series 2). These machines are purpose-built for local AI, defined by the tight integration of multiple specialized compute units on a single chip. They feature a high-performance CPU for immediate, low-latency responsiveness, a high-throughput integrated GPU for demanding parallel tasks, and most importantly, a powerful Neural Processing Unit (NPU) architected for sustained, energy-efficient inference. With each processor optimized for different metrics—latency, throughput, and performance-per-watt—the fundamental challenge for a developer becomes: how do we make a single PyTorch model intelligently leverage this entire suite of specialized hardware without fragmenting the development workflow or leaving the PyTorch ecosystem?
In this technical deep dive, we explore the OpenVINO™ backend for ExecuTorch, a solution engineered to abstract away the complexity of heterogeneous computing. We will examine how it integrates directly into the PyTorch 2.x workflow, automating the entire optimization pipeline to allow a single model to intelligently leverage the specialized capabilities of CPUs, GPUs, and NPUs for near-native performance.
The Solution's Foundation: ExecuTorch and OpenVINO
To solve the on-device challenge, the PyTorch ecosystem offers ExecuTorch, its next-generation runtime for portable, high-performance inference. Built on the principles of Ahead-of-Time (AOT) compilation, ExecuTorch converts models into a lightweight, self-contained .pte binary format that minimizes runtime overhead and is fully compatible with the modern torch.export workflow. While ExecuTorch includes a set of default CPU kernels for broad portability, its primary mechanism for high-performance hardware acceleration is its extensible backend system, which allows it to hand off computation to specialized backends.
The OpenVINO™ (Open Visual Inference & Neural Network Optimization) toolkit from Intel helps bridge this gap. As an open-source toolkit designed to optimize AI performance on Intel hardware, OpenVINO serves as an ideal backend for ExecuTorch, enabling developers to get the most out of Intel hardware. It provides a suite of model optimization tools, including hardware-aware quantization, and a powerful, heterogeneous runtime. This runtime is the key: it abstracts away the complexity of the underlying silicon, providing a single API to execute models with optimized kernels across the CPU, GPU, and NPU.
"We're making it easy for the PyTorch community to build for the AI PC era," says Adam Burns, Vice President, Client and Edge AI Frameworks at Intel. "With OpenVINO integrated into ExecuTorch, developers can tap into the full power of Intel CPUs, GPUs, and NPUs—without leaving their PyTorch workflow."
Beginning of the Journey: From nn.Module to Export IR (EXIR)
The journey begins with the standard PyTorch 2 workflow. We start with a typical torch.nn.Module and use torch.export to capture a graph representation of the model. This process, powered by TorchDynamo, traces the model's forward pass and produces an ExportedProgram, which contains a clean, graph-based representation of the model in ATen dialect—the standard PyTorch operator set.
This FX Graph is our source of truth, a static and portable representation of the model's logic, ready for optimization.
The OpenVINO Backend: A Technical Walkthrough
The OpenVINO™ backend is not just a simple backend; it’s an integrated compilation toolchain that operates on the EXIR graph. It consists of an ahead-of-time (AOT) compilation phase that produces a final, deployable asset, and a runtime component that executes it.
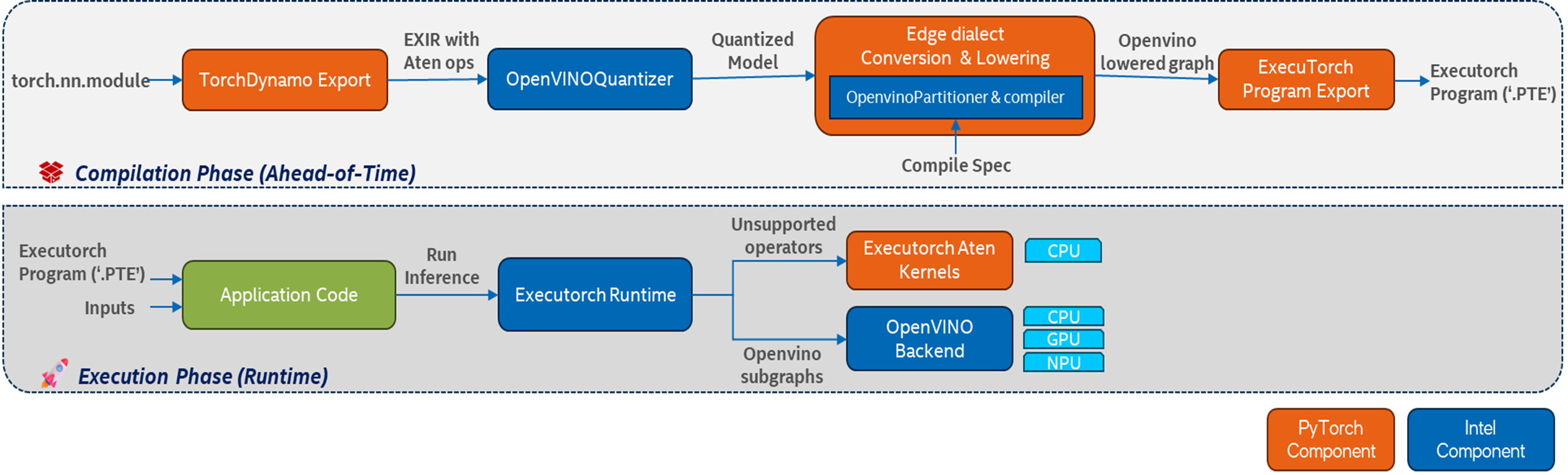
Phase 1: Ahead-of-Time (AOT) Compilation
This initial phase is a critical, offline pre-processing step where the standard PyTorch model is transformed into a highly efficient, deployable artifact specifically optimized for Intel hardware. During this AOT stage, the model undergoes a series of sophisticated analyses and transformations. It leverages the full power of the OpenVINO™ toolkit to prepare the model for peak performance by applying hardware-aware optimizations and intelligently partitioning the computational graph. This approach ensures that the heavy lifting of compilation and optimization occurs only once, before deployment, resulting in a portable asset that is primed for fast and efficient execution.
Step 1: Backend-Aware Quantization
The first stage in the pipeline is optimization via the OpenVINOQuantizer, which is powered by Neural Network Compression Framework (NNCF). This post-export pass applies backend-aware quantization to convert models to lower precision for maximum performance. The OpenVINOQuantizer supports two distinct, backend-aware compression pathways to optimally prepare a model for the target hardware: Post Training Quantization (PTQ) and Weight Compression (WC).
The first pathway is full Post-Training Quantization (PTQ), designed for maximum inference acceleration. In modes like INT8_SYM or INT8_MIXED, this process targets both weights and activations. It leverages a calibration dataset to analyze the dynamic range of tensors throughout the model, calculating the optimal scaling factors to convert them from FP32 to INT8 with minimal accuracy degradation. This holistic quantization unlocks significant performance gains by enabling the use of specialized low-precision hardware instructions, such as Intel® AMX and VNNI on modern CPUs, or the native integer compute units on an NPU.
The second pathway is a distinct Weights-Only (WO) compression mode, engineered to address the enormous memory footprint of large models, particularly LLMs. Available for both INT8 and aggressive INT4 precision, this is a data-free approach that exclusively compresses the model's weight tensors while activations remain in their native floating-point precision. This dramatically reduces model size—a critical requirement for on-device deployment of generative AI. To preserve the fidelity of large models at such low precision, the underlying NNCF compress_pt2e API is used which allows the user to employ a combination of sophisticated techniques like AWQ, scale estimation, group-wise scaling and mixed precision compression.
Crucially, both pathways are fundamentally backend aware. NNCF, through its integration with the OpenVINO™ backend, understands which operators the target hardware (CPU, GPU, or NPU) can accelerate in a low-precision format. It automatically creates an optimal mixed-precision model, ensuring that operators are only quantized if it results in a performance benefit. This avoids the common pitfalls of generic quantization, resulting in a model that is maximally optimized for the specific capabilities of the AI PC.
Step 2: Graph Partitioning and Lowering
This is the core of the backend’s intelligence. The OpenvinoPartitioner traverses the EXIR graph node by node and identifies the largest possible contiguous subgraphs of operators that are supported by the OpenVINO™ runtime.
The result is a hybrid graph. The subgraphs destined for acceleration are "lowered"—converted from PyTorch ATen ops into a serialized OpenVINO™ model (ov::Model) and compiled into hardware-specific blobs. These lowered subgraphs are then replaced in the main graph by a single, opaque call_delegate custom operator. The remaining operators, which may be unsupported by the backend, are left untouched as standard ATen ops.
Step 3: Serialization to a .pte File
Finally, this entire hybrid graph—containing the ExecuTorch bytecode for the main graph, the serialized OpenVINO model blobs for the delegated subgraphs, and the model weights—is bundled into a single, self-contained .pte file. This portable asset is all you need to deploy.
Phase 2: Heterogeneous Execution at Runtime
At runtime, the ExecuTorch runtime loads the .pte file and acts as the primary orchestrator.
- It executes the graph operator by operator.
- When it encounters a standard ATen op, it dispatches it to its own highly efficient, portable CPU kernels.
- When it encounters a call_delegate operator, it invokes the OpenVINO™ backend.
- The backend receives the pre-compiled OpenVINO model blob and the input tensors. It then uses the OpenVINO runtime to execute this subgraph on the user-specified target hardware—CPU, integrated or discrete GPU, or NPU.
This "hybrid execution" model is a key advantage. It guarantees that your entire PyTorch model will run, providing a robust fallback to the CPU for any operator not supported by the backend. This eliminates the painful process of manually modifying a model to achieve full backend compatibility.
Putting Theory into Practice:
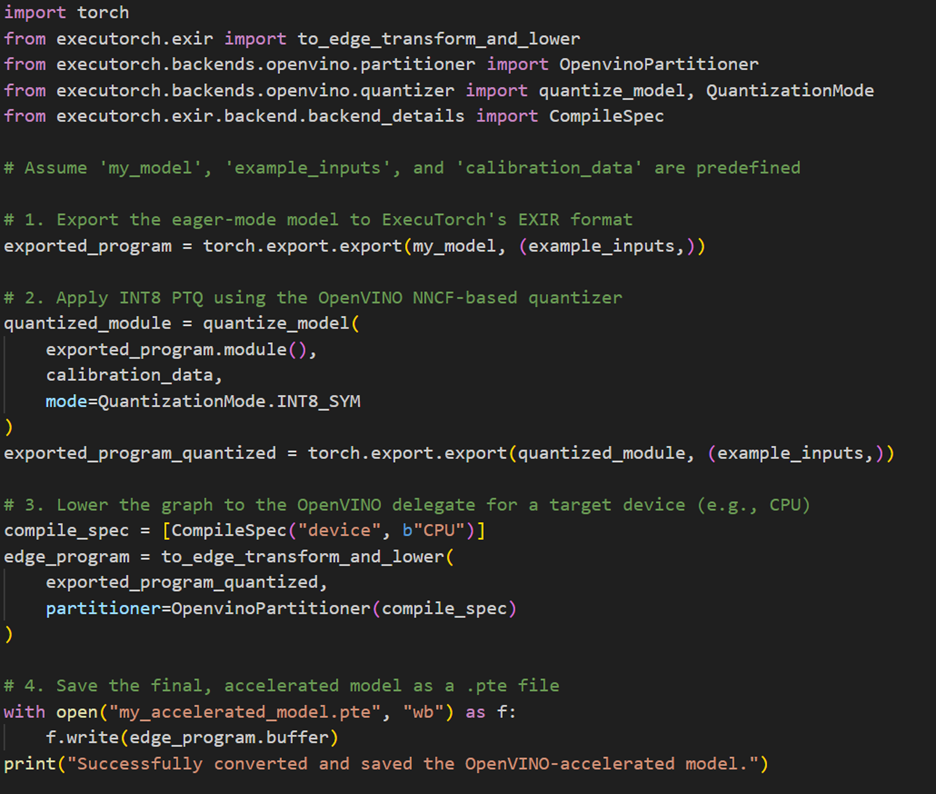
Now, let's translate the concepts we've discussed into the core API calls that enable this workflow. The process is a programmatic, multi-stage pipeline that takes a standard torch.nn.Module and transforms it into a highly optimized ExecuTorch program (.pte file) by chaining together several key functions as below:
- Graph Capture: The process begins by using the standard torch.export function to obtain the initial EXIR graph in the ATen dialect.
- Optimization & Quantization: The exported graph is then passed to the quantize_model function, which leverages the OpenVINOQuantizer and NNCF's advanced PTQ algorithms to apply backend-aware quantization.
- Graph Lowering: The optimized graph is then passed to to_edge_transform_and_lower along with the OpenvinoPartitioner. This is the critical step where subgraphs are identified and marked for delegation to the OpenVINO runtime.
- Finalization: Finally, the lowered graph is converted into the .pte artifact, a self-contained, deployable binary ready for execution.
The following code snippet demonstrates how these stages are linked together to create the final, hardware-accelerated asset.
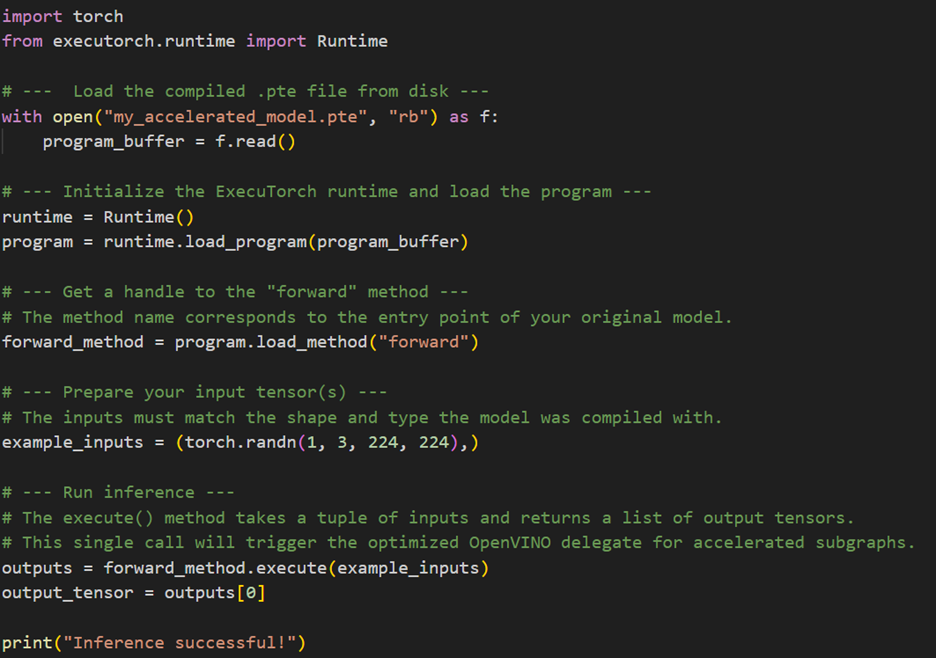
Once the Ahead-of-Time (AOT) compilation is complete, you are left with a portable .pte file. The next step is to load and execute this program using the ExecuTorch runtime. This runtime is designed to be lightweight and efficient, making it ideal for on-device applications.
The infer_model function from our example script provides a practical template for this process. It demonstrates the key steps: initializing the executorch.runtime. Runtime, loading the program from its binary buffer, getting a handle to the main forward method, and then executing it with input tensors. It also includes standard benchmarking practices like running warmup iterations before measuring latency to ensure caches are warm and performance is stable.
The following code snippet distills this process down to its essential API calls, showing how you would integrate the .pte model into your own application for inference.
Practical Applications:
The arrival of the AI PC, powered by heterogeneous compute platforms like Intel® Core™ Ultra processors, marks a fundamental shift in personal computing. No longer is a PC reliant on a single processor for all tasks. Instead, it offers a suite of specialized processors—a powerful Central Processing Unit (CPU), a high-throughput Graphics Processing Unit (iGPU), and a highly efficient Neural Processing Unit (NPU)—on a single chip. This architecture enables developers to run AI workloads on the most suitable hardware for the job, a concept known as heterogeneous execution. The following use cases demonstrate how ExecuTorch can be used to target these specific processors, unlocking new levels of performance and efficiency for a variety of on-device AI applications.
Use Case 1: Real-Time Object Detection with YOLOv12
Object detection is one of the most popular and impactful tasks driving the adoption of on-device AI. From automating warehouse inventory management to enabling real-time traffic analysis in smart cities, these models are transforming a huge variety of real-world applications. The YOLO family of models has consistently proven to be a fast, accurate, and reliable solution, making it a perfect candidate for deployment on the next generation of client hardware. With the help of Executorch optimizations, one can run the latest Yolo12 model on-device with minimal runtime and optimum performance. Recommended INT8 quantization recipe allows to reduce memory and energy consumption of deployed models with insignificant impact on quality of detections. The GIF below shows YOLOv12 object detection running in real-time on Intel® Core™ Ultra Processors (Series 2), highlighting the impressive capabilities of the platform's CPU.

The demo is available in Executorch examples with OpenVINO backend.
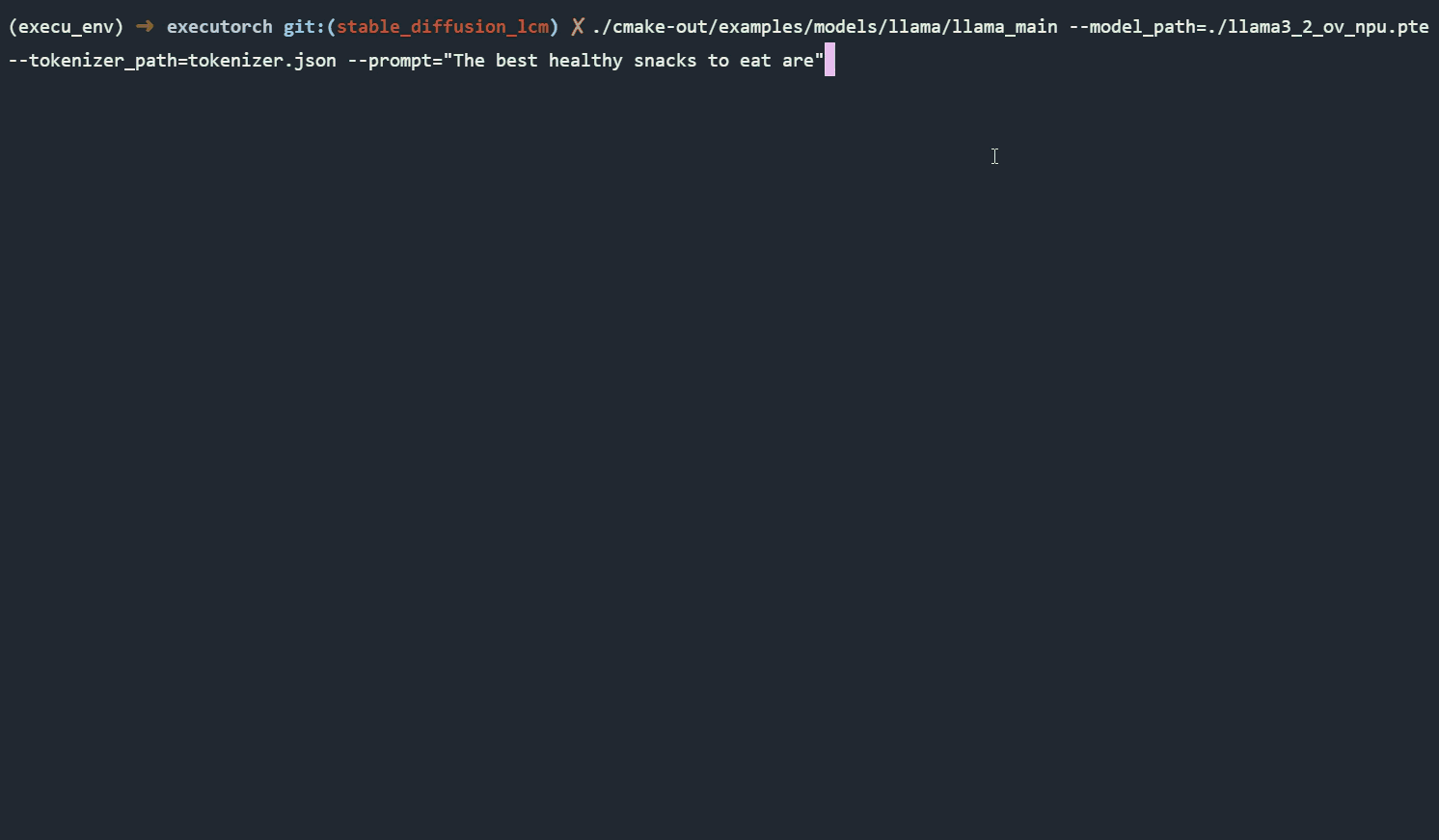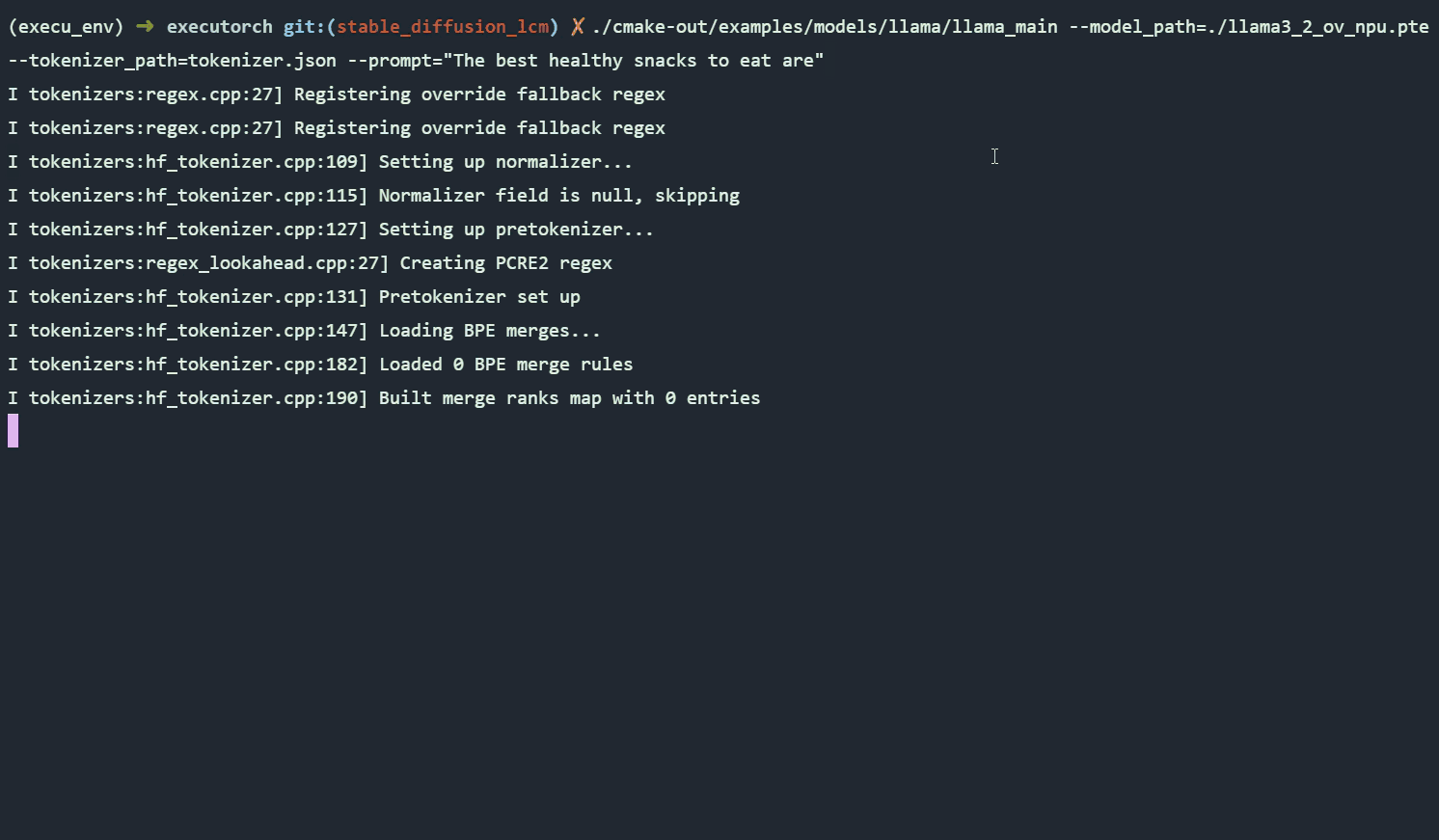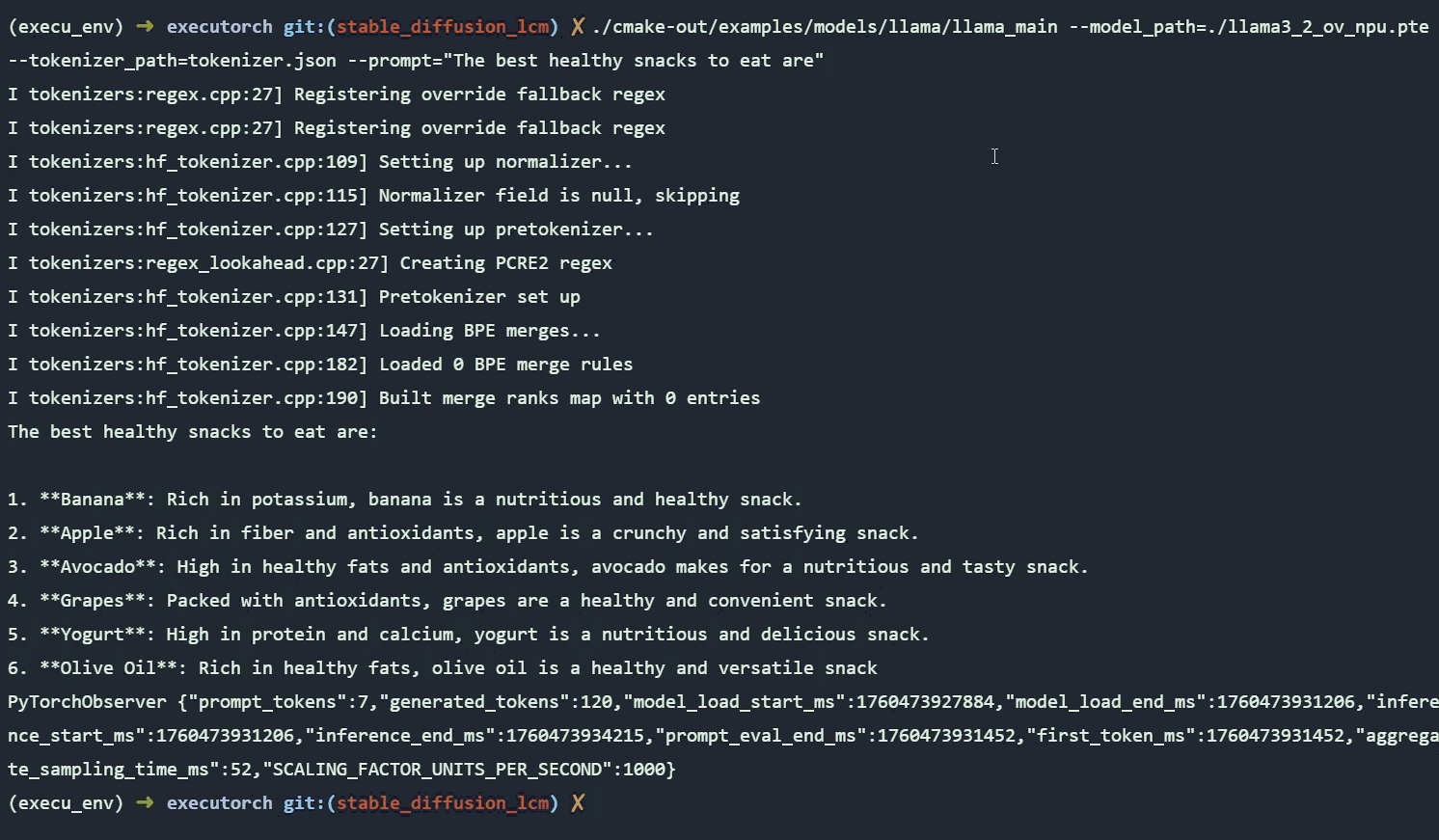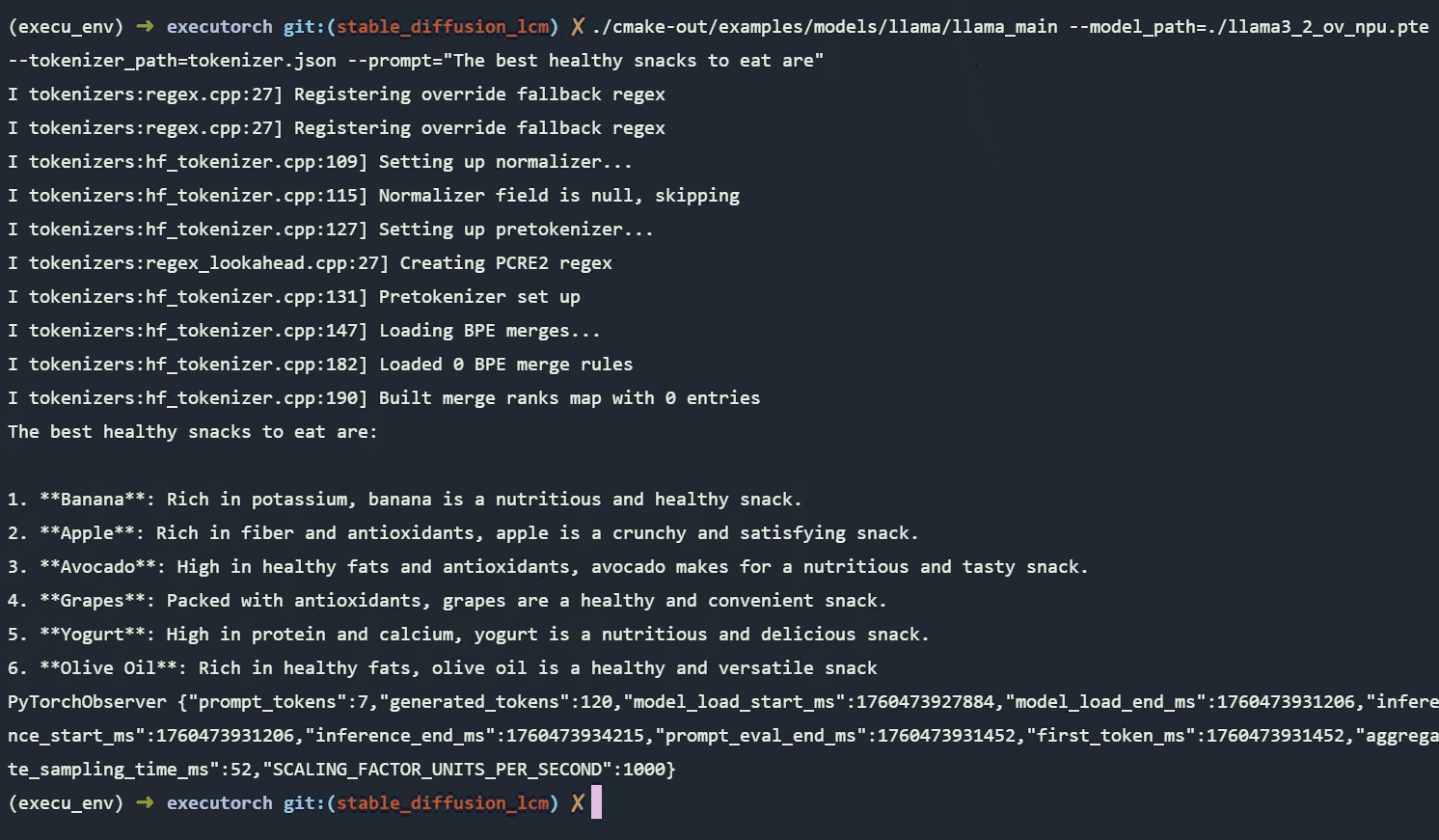
Use Case 2: On-Device Chat with Llama 3.2 1B
Llama is a collection of advanced language models developed by Meta, designed to understand and generate human-like text for tasks such as answering questions, writing, summarizing, and coding. Llama 3.21B is a lightweight 1‑billion-parameter version optimized for edge devices, supporting long context windows (~128K tokens) and multiple languages for tasks like summarization, instruction-following, and multilingual text generation.
With Executorch, exporting Llama 3.21B for the OpenVINO backend allows you to run the model efficiently on Intel AI PCs. The model can also be quantized to 4-bit integers and deployed for the OpenVINO backend, enabling faster inference and optimized performance while leveraging Intel hardware.
Detailed instructions for exporting Llama 3.21B and running it on-device can be found in Llama example page. The GIF below shows Llama 3.21B inference running on Intel® Core™ Ultra Processors (Series 2) NPU.
Use Case 3: Image Generation with Stable Diffusion
Stable Diffusion is a state-of-the-art text-to-image generation model that creates high-quality images from text descriptions, widely used for creative tasks such as digital art, concept design, prototyping, and image editing. The Latent Consistency Model (LCM) is an optimized variant of Stable Diffusion that drastically reduces inference time by requiring only 4-8 denoising steps compared to traditional Stable Diffusion's 25-50 steps, while maintaining image quality.
By leveraging ExecuTorch with the OpenVINO backend, developers can deploy LCM (SimianLuo/LCM_Dreamshaper_v7) to run text-to-image generation directly on Intel AI PCs. The LCM architecture comprises three core components - the text encoder, UNet, and VAE decoder, each exported with FP16 precision for deployment using OpenVINO on Intel hardware.
Detailed instructions for exporting and running the model can be found in the Stable Diffusion Examples page.
The high-resolution image shown below was generated using GPU-accelerated inference on Intel® Core™ Ultra Processors (Series 2). The image takes less than 5s to generate on GPU, demonstrating the platform's capability to produce high-quality outputs with reduced synthesis time.

Prompt used for generation: “Mountain landscape at sunset with aurora borealis, digital art style,vibrant colors”
Conclusion
The OpenVINO backend for ExecuTorch represents a significant step forward for on-device AI within the PyTorch ecosystem. It provides a robust, developer-friendly path from research to deployment that honors the design principles of PyTorch 2.0. By automating complex tasks like hardware-aware quantization and graph partitioning, it allows developers to seamlessly target the full spectrum of compute resources in modern AI PCs, ensuring that PyTorch models can run with the performance and efficiency that users demand.
To learn more and get started, explore the official ExecuTorch documentation and the resources available for OpenVINO.
For additional performance gains on Intel hardware or for more capabilities at the edge or in the cloud, consider using the native OpenVINO™ toolkit.
Acknowledgments
Muthaiah Venkachalam (Intel), Maksim Proshin (Intel), Ravi Panchumarthy (Intel), Maxim Vafin (Intel), Dmitriy Pastushenkov (Intel), Stefanka Kitanovska (Intel), Adam Burns (Intel), Matthew Formica (Intel), Preethi Raj (Intel), Whitney Foster (Intel), Stephanie Maluso (Intel)
Mergen Nachin (Meta), Kimish Patel (Meta), Bilgin Cagatay (Meta), Andrew Caples (Meta)