

Authors:
Intel: Anisha Kulkarni, Anoob Kodankandath, Jianlin Qiu, Yamini Nimmagadda, Jeevaka Badrappan, Ratnesh Kumar Rai, Rijubrata Bhaumik
Google: Matt Kreileder, Weiyi Wang, Somdatta Banerjee
On-device AI demands substantial processing power, which can strain system resources and quickly drain battery life. To deliver seamless, intelligent features on next‑generation PCs, dedicated AI acceleration is essential. Intel® Core™ Ultra processors meet this need with an integrated NPU purpose‑built for maximum efficiency.
To unlock these capabilities for developers, Google and Intel are partnering to make AI acceleration easier to use. LiteRT is Google’s on‑device framework for high‑performance ML and GenAI deployment on edge platforms, and its integration with OpenVINO™ brings Intel’s NPU within easy reach of the LiteRT developer community. This dramatically simplifies offloading demanding AI workloads and helps realize the full potential of the AI PC. Through the new OpenVINO™ backend, LiteRT provides a unified API to access the NPU across both Windows and Linux, abstracting away hardware complexity so developers can focus on creating smarter, more innovative experiences.
Announcing LiteRT Support for Intel NPUs via OpenVINO™
To enable developers to easily harness these benefits on Intel-powered AI PCs, we are thrilled to announce full LiteRT support for NPUs on Intel® Core™ Ultra processors, leveraging the Intel® Distribution of OpenVINO™ toolkit as a high-performance backend.
This collaboration between Google and Intel provides a unified LiteRT API, abstracting away hardware complexities across both Windows and Linux.
How it Works: LiteRT intelligently delegates supported model operations to the OpenVINO™ backend, which optimizes and executes them on the Intel NPU.
LiteRT Support for Intel NPUs via OpenVINO™ introduces several major advantages for developers:
- Effortless NPU Acceleration: Delegate more than 90 common classical models from LiteRT’s on-device ML model suite to the Intel NPU.
- Optimized GenAI: Experience highly optimized execution for models like Gemma 4 E2B, achieving ~1.3x speed-up on the OpenVINO NPU over LiteRT WebGPU on Intel® Core™ Ultra Series 3 processors.
- Radical Power Efficiency: The NPU consumes significantly less power than the GPU for sustained AI workloads. Running Gemma 4 E2B model on the NPU shows 2.8x improvement in performance per watt over GPU.
- Developer Flexibility: Choose between Ahead-of-Time (AOT) compilation for minimal startup latency or Just-in-Time (JIT) for dynamic execution.
Performance Realized: Generative AI & Beyond
The benefits of offloading to the Intel NPU via LiteRT are clear across the AI spectrum.
Generative AI: The Gemma Family
The value proposition is even more compelling for state-of-the-art language models. The integration delivers optimized support for multiple models in the Gemma family:
Gemma 4 E2B: A lightweight model for fast, real-time on-device processing, now fully multimodal with native audio capabilities. On Intel® Core™ Ultra Series 3 processors, LiteRT with OpenVINO™ integration enables the NPU to achieve 1.3x prefill and 1.2x decode performance, along with a 2.8x improvement in performance per watt compared to the GPU.
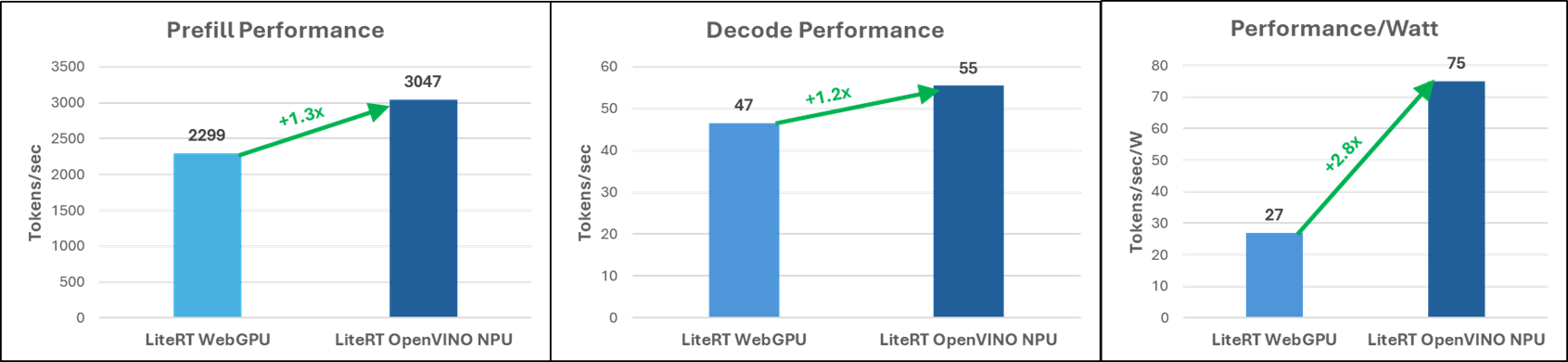
Gemma 4 E2B model inference on Intel® Core™ Ultra 7 355
The OpenVINO backend for LiteRT delivers a major efficiency leap for AI on Intel platforms by unlocking the NPU. This path provides superior performance-per-watt over the WebGPU backend, making it ideal for power-constrained environments. On mainstream systems like the Intel® Core™ Ultra 7 355 (4 Xe), the NPU handles workloads at less than half the power of the GPU while achieving nearly 1.3x the throughput in critical LLM prefill stages. This efficiency transforms the enterprise "day-in-the-life" experience. For instance, while a professional is engaged in a video conference, a task that already taxes the GPU for video encoding, an LLM like Gemma 4 can run simultaneously on the NPU to provide live transcription or instant query responses. This intelligent load-balancing ensures a seamless meeting experience without the thermal throttling or rapid battery drain typical of GPU-only processing.
On high-end flagship systems like the Intel® Core™ Ultra X7 358H (12 Xe), the backend remains highly competitive. Despite the GPU's high compute TOPs, the NPU’s raw decode throughput is on par with the LiteRT-LM WebGPU backend, allowing developers to deliver high performance while preserving the GPU for other intensive tasks. The NPU path is 3x more power efficient than the GPU. This enables high-performance gaming scenarios where the GPU is fully dedicated to rendering immersive graphics, while the NPU handles a background LLM assistant to facilitate real-time communication and strategy with other players. By offloading these "always-on" AI tasks, developers can deliver sophisticated intelligence without sacrificing performance.
Embedding Gemma: A lightweight (308M parameter) multilingual model designed specifically for high-quality retrieval and on-device semantic search or RAG (Retrieval-Augmented Generation) pipelines. It supports over 100 languages and runs more than 20x faster than on CPU, with 12.8 ms inference time.
The OpenVINO backend for LiteRT will expand to include GPU support, bringing specialized optimizations to all accelerators. This roadmap ensures a scalable, high-performance path for next-generation AI features across all device segments.
Classical Models: Instant Responsiveness
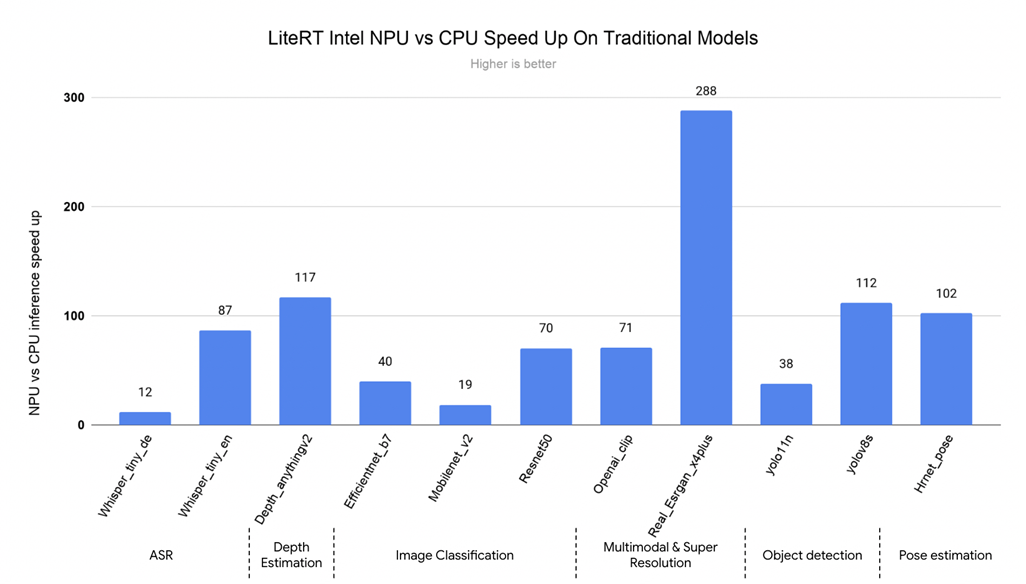
We benchmarked a set of canonical ML models (vision, audio, and NLP) demonstrating a massive jump in performance over CPU (LiteRT XNNPACK) execution:
- Over 45 models (~50%) execute in under 5ms on the NPU, compared to only 4 models achieving this on the CPU.
- This unlocks a host of live AI experiences that were previously unreachable on standard desktop processors.
Get Started Today
Incorporating Intel NPU acceleration into your applications using LiteRT is designed to be straightforward.
Both Python and C++ APIs can be used for just-in-time (JIT) or ahead-of-time (AOT) compilation of a provided .tflite model.
JIT compilation in Python
# 1. Load model and initialize runtime.
env = Environment.create(options=EnvironmentOptions(
compiler_plugin_path=intel_openvino_backend.get_compiler_plugin_dir() or "",
dispatch_library_path=intel_openvino_backend.get_dispatch_dir() or "",
))
opts = Options.create()
opts.hardware_accelerators = HardwareAccelerator.NPU
ov_opts = opts.intel_openvino_options
ov_opts.performance_mode = IntelOpenVinoOptions.PERFORMANCE_MODE.THROUGHPUT
ov_opts.configs_map["CACHE_DIR"] = "/tmp/litert-openvino-cache"
model = CompiledModel.from_file(
"/path/to/mymodel.tflite",
environment=env,
options=opts,
)
# 2. Prepare input/output buffers.
signature_index = 0
input_buffer = model.create_input_buffers(signature_index)[0]
output_buffer = model.create_output_buffers(signature_index)[0]
# 3. Fill the input buffer.
input_buffer.write(input0)
# 4. Invoke.
model.run_by_index(signature_index, [input_buffer], [output_buffer])
# 5. Read the output.
output = output_buffer.read(num_elements, np.float32).reshape(output_shape)
AOT compilation in Python
from ai_edge_litert.aot import aot_compile
from ai_edge_litert.aot.vendors.intel_openvino import target as intel_target
# Compile for a single Intel NPU target (PTL or LNL).
aot_compile.aot_compile(
"model.tflite",
output_dir="out",
target=intel_target.Target(soc_model=intel_target.SocModel.PTL),
)
# Compile for every registered backend/target.
aot_compile.aot_compile("model.tflite", output_dir="out", keep_going=True)
Architecture Overview
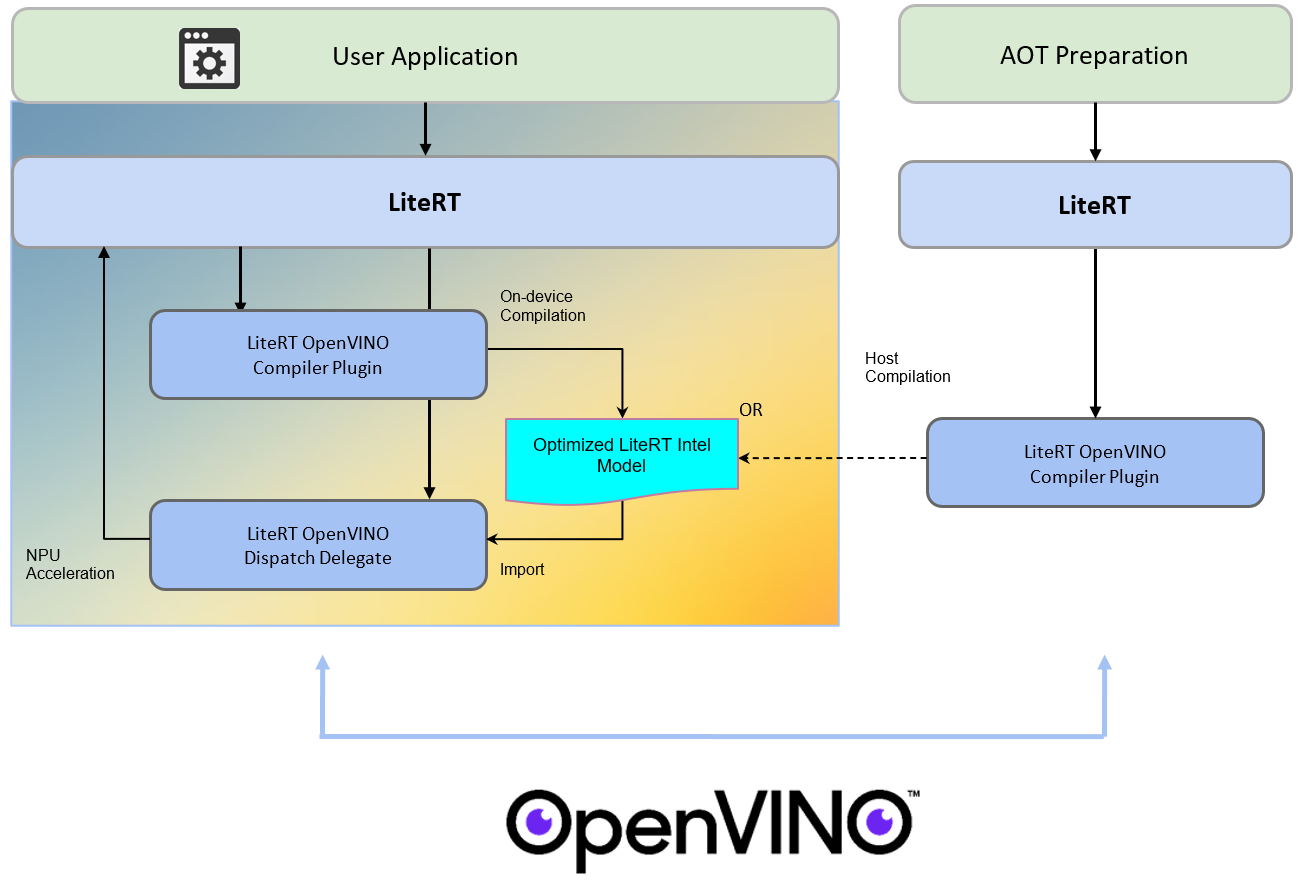
The OpenVINO backend for LiteRT enables high-performance inference on Intel NPUs through a streamlined two-stage pipeline. In the Compilation Flow, the model is processed by the OpenVINO compiler plugin, which identifies supported subgraphs and optimizes them into hardware-specific compiled blobs embedded within a standard .tflite container. At runtime, the Dispatch Flow takes over; the backend imports these compiled blobs and initializes the necessary execution context, including the allocation of OpenVINO remote tensors to ensure efficient, zero-copy data handling. By bridging the LiteRT API with the OpenVINO Runtime and underlying Intel NPU drivers, this architecture allows developers to leverage specialized AI silicon with minimal friction, ensuring maximum throughput and energy efficiency for edge AI applications.
Building Applications with LiteRT OpenVINO Backend
The example below shows Gemma 4 E2B optimized for the Intel NPU, illustrating how hardware-accelerated, on-device AI can power fast, efficient local experiences.
Featured Demo: Local Page Summarizer
A practical example of this integration in action is the Page Summarizer demo. It captures content from the active browser tab or document and generates a summary locally on the Intel NPU, illustrating how hardware-accelerated, on-device AI can deliver responsive experiences while keeping data on the device.
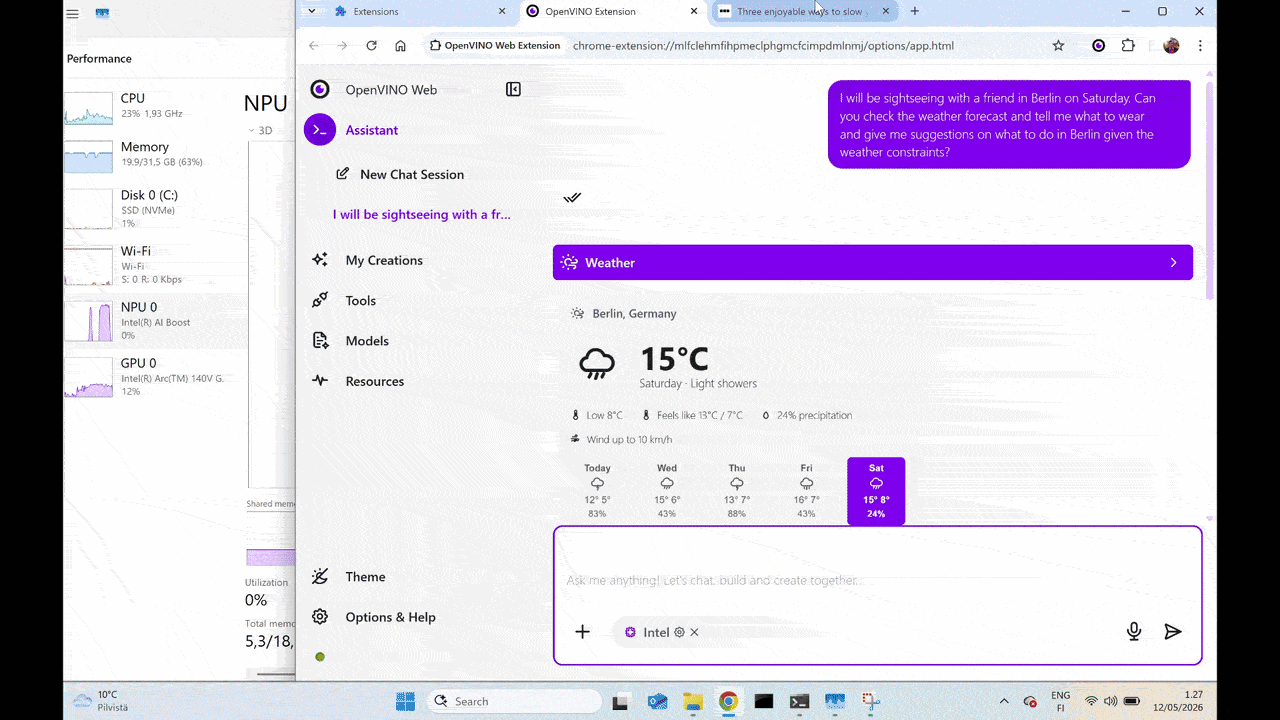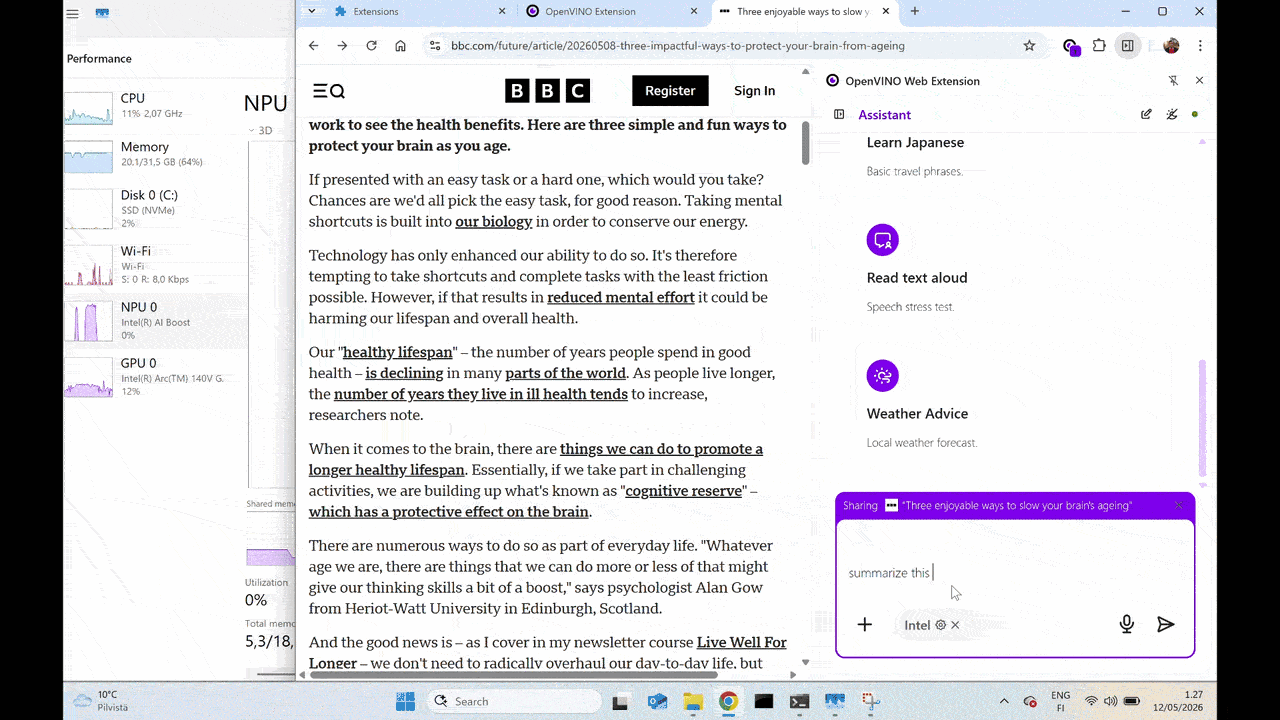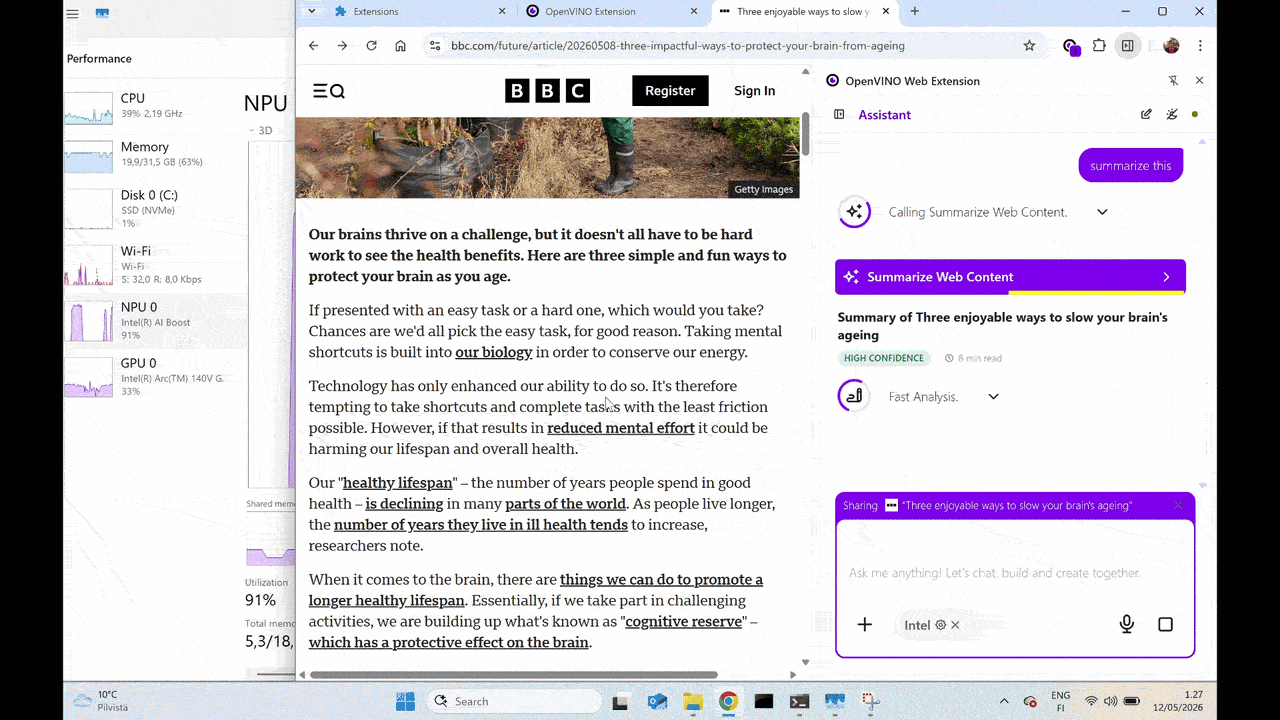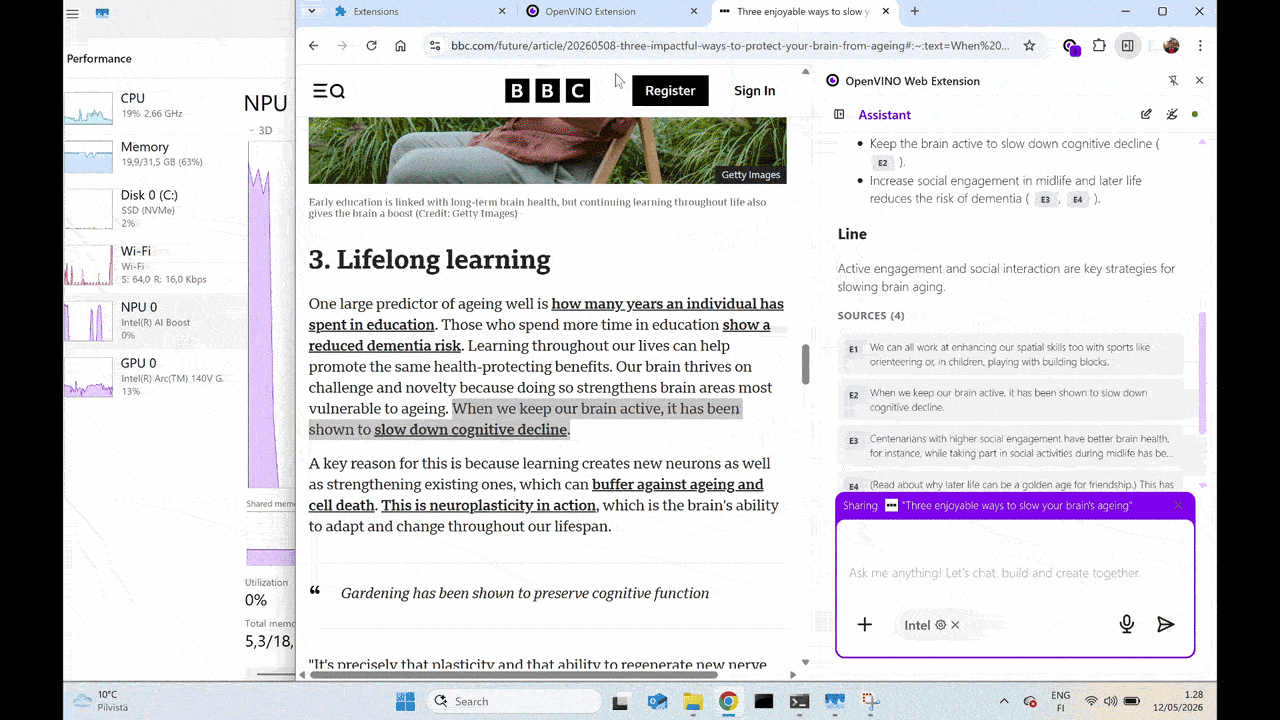
Gemma 4 E2B running on Intel NPU (Neural Processing Unit), powered by LiteRT-LM OpenVINO backend.
Advanced Capabilities: Real-Time Tool Calling
The demo also highlights that on-device AI does not have to be limited to static inputs. Using LiteRT-LM tool-calling APIs, the local model can securely connect to external tools in its environment to retrieve up-to-date information, invoke local functionality, and combine model intelligence with live context, all while preserving the privacy and low-latency benefits of local execution.
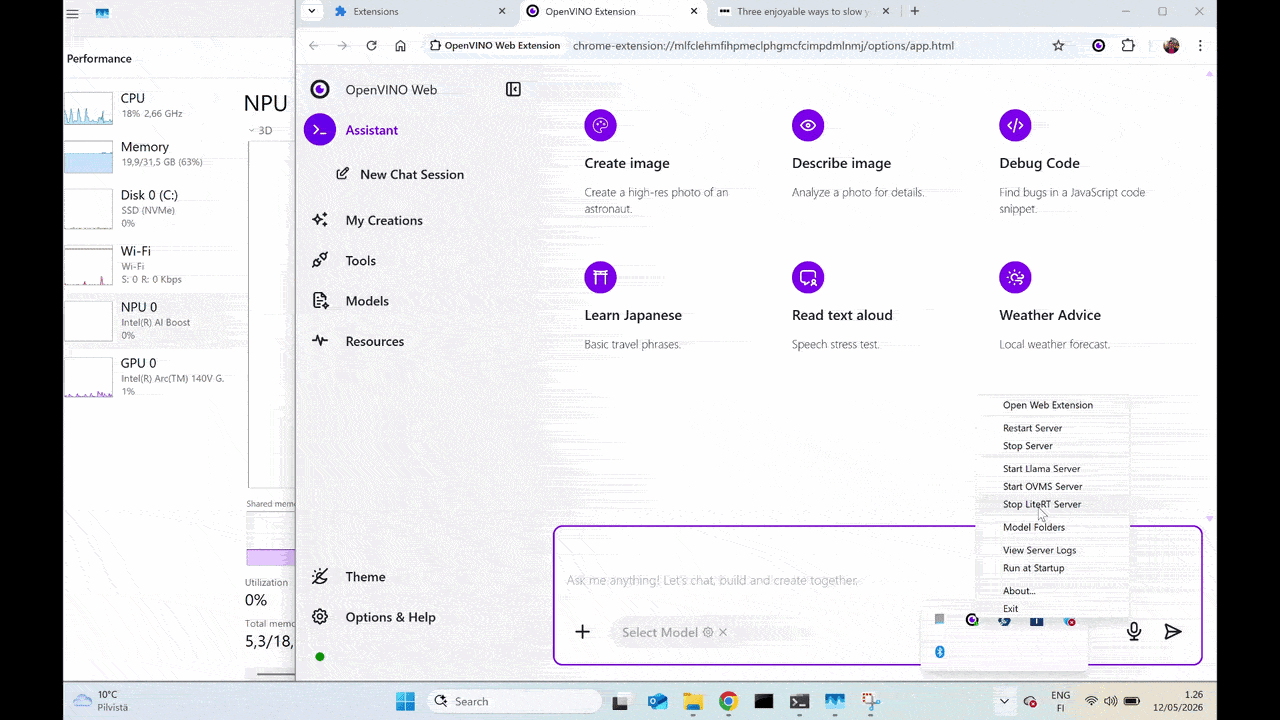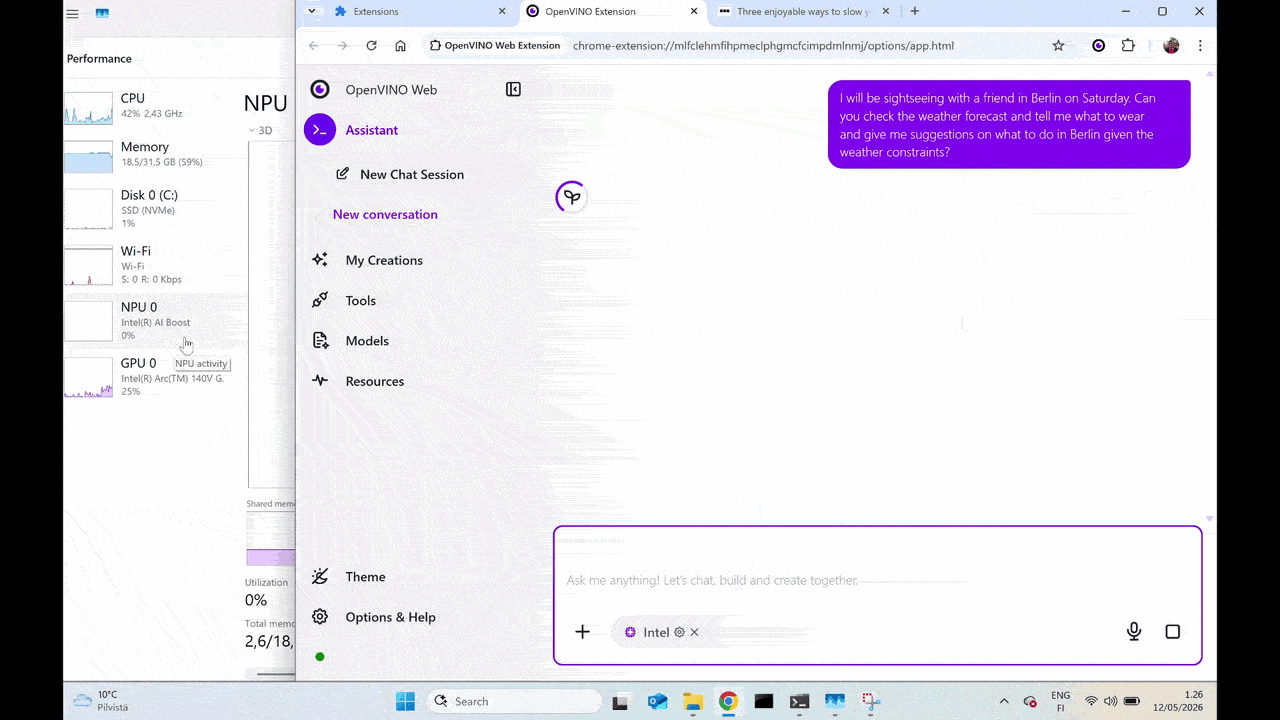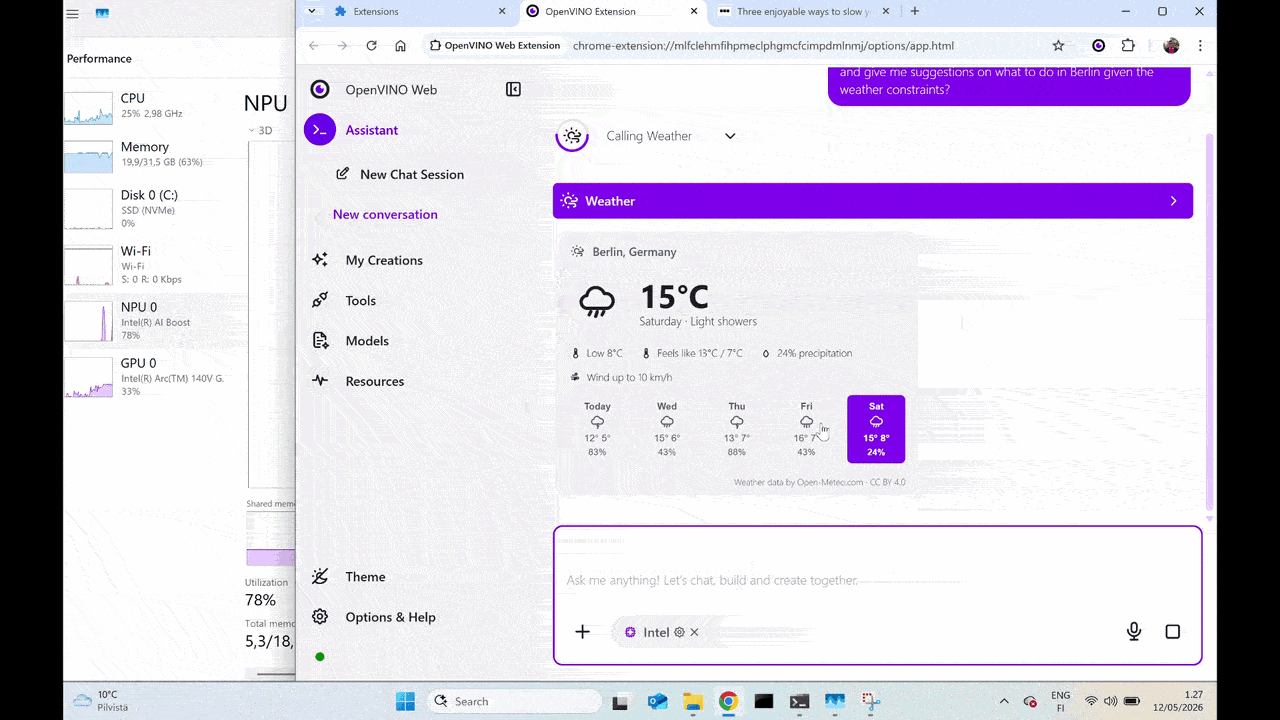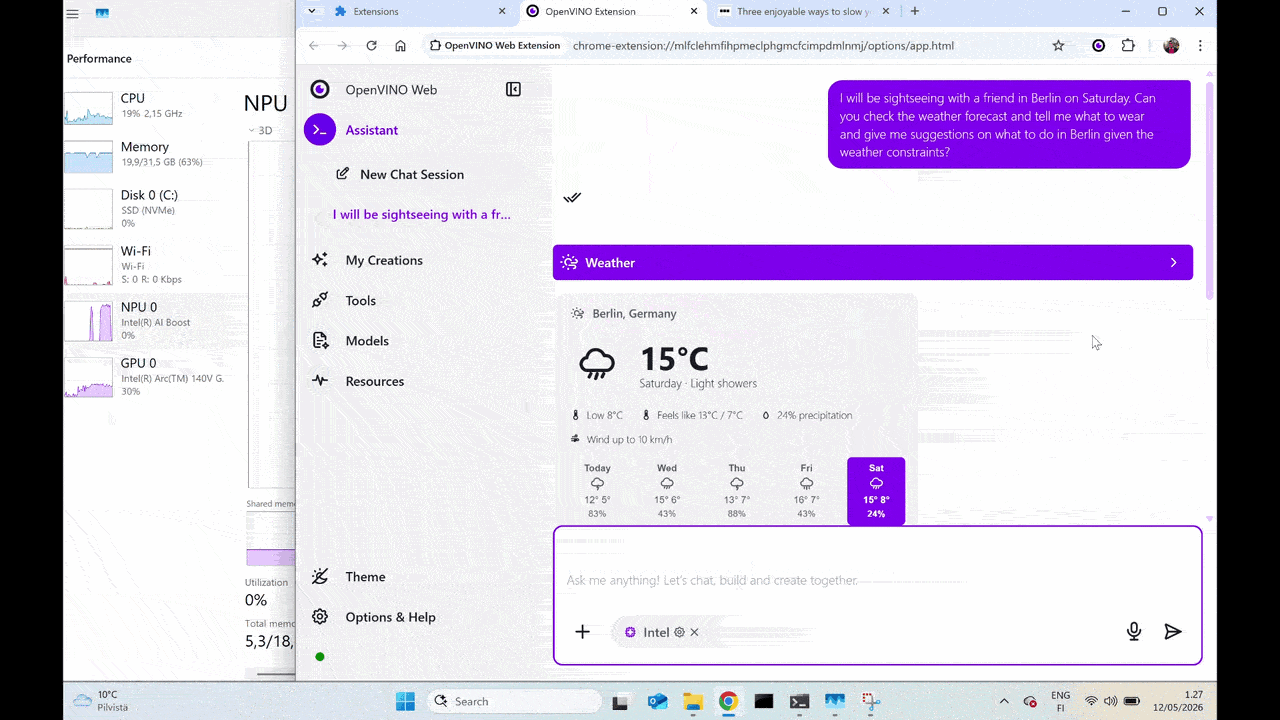
Real-Time Tool Calling powered by LiteRT-LM OpenVINO backend
What's Next
The integration of OpenVINO as a backend in LiteRT and LiteRT-LM is a major milestone, unlocking efficient LLM inference on Intel NPUs across Windows and Linux. This effort makes Intel NPUs accessible in LiteRT developer ecosystem offering a practical, scalable path for multimodal and generative AI to run privately and natively on everyday devices without cloud dependence. We are incredibly excited to see what you build with this power. We encourage you to explore the OpenVINO LiteRT Documentation, check out the LiteRT-LM models for Intel NPU in Hugging Face , and visit the LiteRT Github repository. You can learn more about OpenVINO at our homepage. Happy building!
Acknowledgements
Intel Team:
Ritul Jasuja, Junwei Fu, Yingying Ma, Vijeetkumar Benni, Ningxin Hu, Kayanthieni Panchalingam, Gautam Desai, Shreekanth Rao, Adam P Burns, Lei Zhai, Jianhui Dai, Paul Cooper, Rijubrata Bhaumik, Preethi Raj, Whitney Foster, Wenzeng Chen, Drygiel Lucas, Uscilowski Adrian, Mahitha Palagiri, Ghosh Soham, Zhaoliang Ma.
Google AI Edge Team:
Andrew Zhang, Jingjiang Li, Chunlei Niu, Yu-hui Chen, Wai Hon Law, Lu Wang, Chintan Parikh, Sachin Kotwani, Cormac Brick, Matthias Grundmann.
Configuration Details
Processor: Intel® Core™ (Series 3) Ultra 7 355 tested in MSI Prestige 14 Flip AI+ D3MTG, Memory: 32GB LPDDR5 8533 MT/S, Storage:Phison 1TB ESR01TBYCCA4-EDJ-2MS, Display Resolution: 2880x1800, OS:Windows 11 25H2(26200.8246), Graphics Driver: 32.0.101.8737, NPU Driver: 32.0.100.4724, BIOS: E14T2IMS.10E, Power Plan: Default, Power Mode: Balanced
Processor: Intel® Core™ (Series 3) Ultra X7 358H tested in LP5x, RVP, Pre PRQ - N32247-200, Memory: 32GB LPDDR5, 8533Mhz, Storage: SAMSUNG MZVL71T0HFLU(1TB), OS: Microsoft Windows 11(26200.8116), Graphics Driver: 32.0.101.8737, NPU Driver: 32.0.100.4724, BIOS: PTLPFWI1.R00.4132.D04.2604011509, Power Plan: Default, Power Mode: Balanced
Power and Performance measurement (Measured as of May 2026):
Intel Core (Series 3) Ultra 7 355 power measured via SocWatch with Gemma4 performance measured via LiteRT OpenVINO backend for NPU and LiteRT WebGPU backend for GPU. Intel® Core™ (Series 3) Ultra X7 358H measured on RVP via powermeter with Gemma4 performance measured via LiteRT OpenVINO backend for NPU and LiteRT WebGPU backend for GPU.